Parallelising ETL workflows with the Jongleur gem
 Fred Heath
Fred Heath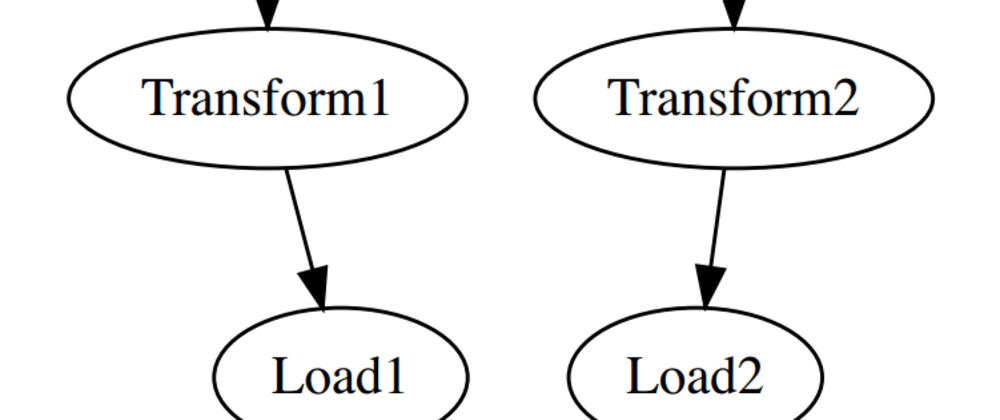
Our assignment
Our company has just gone on a huge recruitment spree and has just hired 100,000 new employees. The HR department has sent us a spreadsheet with the employee details, asking us to save them in the company staff database. After having a look at the data, we notice a few actions we need to take before inserting the details into our database and we come up with the following algorithm:
Read data from the spreadsheet
Break employees' full name into first name and last name fields
Assign each employee a unique company number
Insert employee into the database as long as their first and last name is less than 255 characters long
A single-process ETL pipeline
We then proceed to write a crude but effective ETL pipeline
require 'csv'
require 'pg'
require 'ostruct'
require 'securerandom'
@users = []
@conn = PG.connect( dbname: 'testdb' )
DATA_FILE = "data/users.csv"
def extract(data_file)
CSV.foreach(data_file) do |row|
user = OpenStruct.new
user.name = row[0]
user.email = row[1]
@users << user
end
end
def transform
@users.map! do |usr|
usr.first_name = usr.name.split[0]
usr.last_name = usr.name.split[1]
usr.staff_no = SecureRandom.uuid
usr
end
end
def load(usr)
if( usr.first_name.length < 255 && usr.last_name.length < 255)
@conn.exec_params(
"INSERT INTO STAFF (FIRST_NAME, LAST_NAME, EMAIL, STAFF_NO) VALUES ($1, $2, $3, $4)",
[usr.first_name, usr.last_name, usr.email, usr.staff_no]
)
else puts "Validation failed for #{usr.first_name} #{usr.last_name}"
end
end
extract(DATA_FILE)
transform
@users.each {|usr| load(usr)}
Our extract method reads the data from file and stores it in memory. The transform method then splits the full name field into first and last name and assigns a UUID to the employee. Finally, our load method ensures the name fields don't exceed the expected length, before inserting the data into the Staff table.
We test our script and it works fine, however all this data crunching takes a long time and, us being the perfectionist that we are, would like to make it faster.
The need for speed
Enter Jongleur a Ruby gem that allows us to create tasks that are executed as separate OS processes and that can be ran with a certain precedence.
We'll use Jongleur to split our ETL pipeline into two separate and parallel pipelines, each dealing with one half of the input data. We want our task graph to look like this:

Each Extract, Transform and Load task will do exactly what we described in our initial algorithm above, but with only half of the spreadsheet records. The Cleanup task will kick-in last, to sweep away any undue remnants after our pipeline has been ran.
Representing the above graph in Jongleur is a simple matter of creating a Ruby Hash:
etl_graph = {
Extract1: [:Transform1],
Transform1: [:Load1],
Extract2: [:Transform2],
Transform2: [:Load2],
Load1: [:Cleanup],
Load2: [:Cleanup]
}
We can then just tell Jongleur to use our task graph
Jongleur::API.add_task_graph etl_graph
Design considerations
One thing we need to consider before creating our parallel tasks is how to share data between tasks which are ran as separate processes. Shared Memory could be used but has some pitfalls which is why we'll be using the wonderful in-memory data store which is Redis. Redis is (mostly) single-threaded, which means concurrent requests are executed sequentially and safely (and blazingly quickly). Furthermore, we'll take advantage of one of Jongleur's great features whereby each task can access the process ids (pids) of its predecessors. This means that we can use a task's pid as a key for its data. So our Extract1 task can save data to Redis with its own pid and when Transform1 task starts it will know exactly which data was created by Extract1, its predecessor!
Common attributes
Every Jongleur task class must inherit from the base class Jongleur::WorkerTask. This means that we can use this class to define data that we want accessible from any and all WorkerTask instances. In our case we want any Extract, Transform and Cleanup tasks to be able to access our Redis data store. To achieve that we simply define the Redis connection as a class variable in the Jongleur::WorkerTask hierarchy:
class Jongleur::WorkerTask
@@redis = Redis.new(host: "localhost", port: 6379, db: 15)
end
Extracting
Both our Extract1 and Extract2 tasks will need to have some common functionality, namely to parse records from the csv file and save them to Redis:
class Extract < Jongleur::WorkerTask
DATA_FILE = "data/users.csv"
def process_row(row, rowno)
user = {}
user[:num] = rowno
user[:name] = row[0]
user[:email] = row[1]
user
@@redis.hset(Process.pid.to_s, "user:#{rowno}", user.to_json)
end
end
Now the only divergence between Extract1 and Extract2 comes when reading the input data from the csv file. Extract1 will only read and store the first 50,000 records, while Extract2 will read and store the remaining 50,000 records.
class Extract1 < Extract
def execute
CSV.foreach(DATA_FILE).with_index(1) do |row, rowno|
break if rowno >= 50000
process_row(row, rowno)
end
end
end
class Extract2 < Extract
def execute
CSV.foreach(DATA_FILE).with_index(1) do |row, rowno|
next if rowno < 50000
process_row(row, rowno)
end
end
end
Transforming
Each Tranform task will need to use its Extracting predecessor's pid in order to load the extracted records it needs to transform. It will then proceed to split each record's name, assign it a UUID and save it back to Redis:
class Transform < Jongleur::WorkerTask
@desc = 'Transforming'
def execute
loader_id = Jongleur::Implementation.get_process_id(predecessors.first)
users = @@redis.hgetall(loader_id)
users.keys.each do |usr_key|
transformed_user = {}
data = JSON.parse users[usr_key]
transformed_user[:first_name] = data['name'].split[0]
transformed_user[:last_name] = data['name'].split[1]
transformed_user[:staff_no] = SecureRandom.uuid
transformed_user[:num] = data['num']
transformed_user[:email] = data['email']
@@redis.hset(Process.pid.to_s, "user:#{data['num']}", transformed_user.to_json)
end
end
end
class Transform1 < Transform; end
class Transform2 < Transform; end
Loading
Load1 and Load2 will pick up the records stored by their respective predecessor Transform tasks, will validate the name length and will insert the records in the Staff table of our HR's Postgres database:
class Load < Jongleur::WorkerTask
@desc = 'Loading'
def execute
loader_id = Jongleur::Implementation.get_process_id(predecessors.first)
users = @@redis.hgetall(loader_id)
conn = PG.connect( dbname: 'testdb' )
users.keys.each do |usr_key|
data = JSON.parse users[usr_key]
if( data['first_name'].length < 255 && data['last_name'].length < 255 )
conn.exec_params(
"INSERT INTO STAFF (FIRST_NAME, LAST_NAME, EMAIL, STAFF_NO) VALUES ($1, $2, $3, $4)",
[ data['first_name'], data['last_name'], data['email'], data['staff_no'] ]
)
else puts "Validation failed for #{usr.first_name} #{usr.last_name}"
end
end
end
end
class Load1 < Load; end
class Load2 < Load; end
Cleanup
All our Cleanup task has to do is to erase the Redis data created by the previously-ran tasks
class Cleanup < Jongleur::WorkerTask
def execute
@@redis.flushdb
puts "...Cleanup"
end
end
Running our pipelines
We now have
Defined our Task Graph and configured Jongleur with it
Implemented an
#executemethod for each of the Tasks in our Task Graph
We are now ready to invoke Jongleur and run our parallel pipelines:
API.run do |on|
on.completed do |task_matrix|
puts "Jongleur run is complete \n"
puts task_matrix
puts "oh-oh" if API.failed_tasks(task_matrix).length > 0
end
end
The output is:
Starting workflow...
starting task Extract1
starting task Extract2
finished task: Extract1, process: 22722, exit_status: 0, success: true
starting task Transform1
finished task: Extract2, process: 22723, exit_status: 0, success: true
starting task Transform2
finished task: Transform1, process: 22726, exit_status: 0, success: true
starting task Load1
finished task: Transform2, process: 22727, exit_status: 0, success: true
starting task Load2
finished task: Load1, process: 22729, exit_status: 0, success: true
finished task: Load2, process: 22732, exit_status: 0, success: true
starting task Cleanup
...Cleanup
finished task: Cleanup, process: 22745, exit_status: 0, success: true
Workflow finished
Jongleur run is complete
#<struct Jongleur::Task name=:Extract1, pid=22722, running=false, exit_status=0, finish_time=1546800512.6342049, success_status=true>
#<struct Jongleur::Task name=:Transform1, pid=22726, running=false, exit_status=0, finish_time=1546800518.355283, success_status=true>
#<struct Jongleur::Task name=:Extract2, pid=22723, running=false, exit_status=0, finish_time=1546800512.967079, success_status=true>
#<struct Jongleur::Task name=:Transform2, pid=22727, running=false, exit_status=0, finish_time=1546800519.273847, success_status=true>
#<struct Jongleur::Task name=:Load1, pid=22729, running=false, exit_status=0, finish_time=1546800533.147315, success_status=true>
#<struct Jongleur::Task name=:Load2, pid=22732, running=false, exit_status=0, finish_time=1546800534.1630201, success_status=true>
#<struct Jongleur::Task name=:Cleanup, pid=22745, running=false, exit_status=0, finish_time=1546800534.899818, success_status=true>
Jongleur gives us a thorough account of each Task's details and success status. Notice how both initial Tasks (Extract1, Extract2) start at the same time and each new Task starts only once its predecessor on the Task Graph has finished. If a Task failed, for whatever reason, Jongleur wouldn't execute its dependent tasks but it would continue running any other tasks it could. The status of all Tasks would still be visible in the Task Matrix structure yielded by the completed callback.
Performance
Running the simple single-process ETL pipeline at the beginning of this article produced the following timings:
9.55s user 1.40s system 32% cpu 33.494 total
Running the parallel Jongleur pipelines produced:
19.99s user 5.23s system 89% cpu 27.210 total
User time is increased with Jongleur (I'd guess due to using Redis) and so is kernel time, obviously due to forking and managing many processes, but overall time is approx. 18% faster using Jongleur with two pipelines. Also consider that in this example we only used two parallel lines, i.e. we split the data load into 2 parts. It is a simple matter to split it into 4, 8 or even 16 parallel lines (dependent on our CPU cores) and thus gain a massive performance gain, using the same logic and principles demonstrated here and simply adding more Tasks.
Jongleur advantages
Performance, through parallelisation.
Implicit precedence handling. Jongleur will start running a task only once its predecessor tasks have successfully finished running. If a task fails, its dependent tasks wil not be ran.
Code modularisation. If a task fails, for whatever reason, it will be marked as such by Jongleur and its dependent tasks will not be run. However, that won't stop any other tasks from being run, which means that partial failure does not necessitate complete failure, in use cases where this is desirable.
The Complete Code
including data file for this demo is freely available
The Future
Feel free to suggest improvements and new features for Jongleur or to talk to me about trying it out for your own Use Cases :)
Subscribe to my newsletter
Read articles from Fred Heath directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Fred Heath
Fred Heath
Product-driven, polyglot software engineer. I've spent over two decades working at every stage of the software development life-cycle, in a variety of roles and using a plethora of languages and platforms. My software interests include Ruby, Elixir, relational databases, Behavior-Driven Development, requirements management and agile methods. As well as an avid reader of anything on software development, quantum mechanics and Iain M.Banks novels, I love writing blog posts and speaking at conferences, having done so at several national and international software-related conferences. I have published two books: "Managing Software Requirements the Agile Way", came out of a need to improve some of the entrenched practices in managing requirements in the agile world. "The Professional ScrumMaster Guide" provides guidance on getting certified and applying Scrum pragmatically.