trunk-based development can work with manual QA
 Shehriyar Qureshi
Shehriyar Qureshi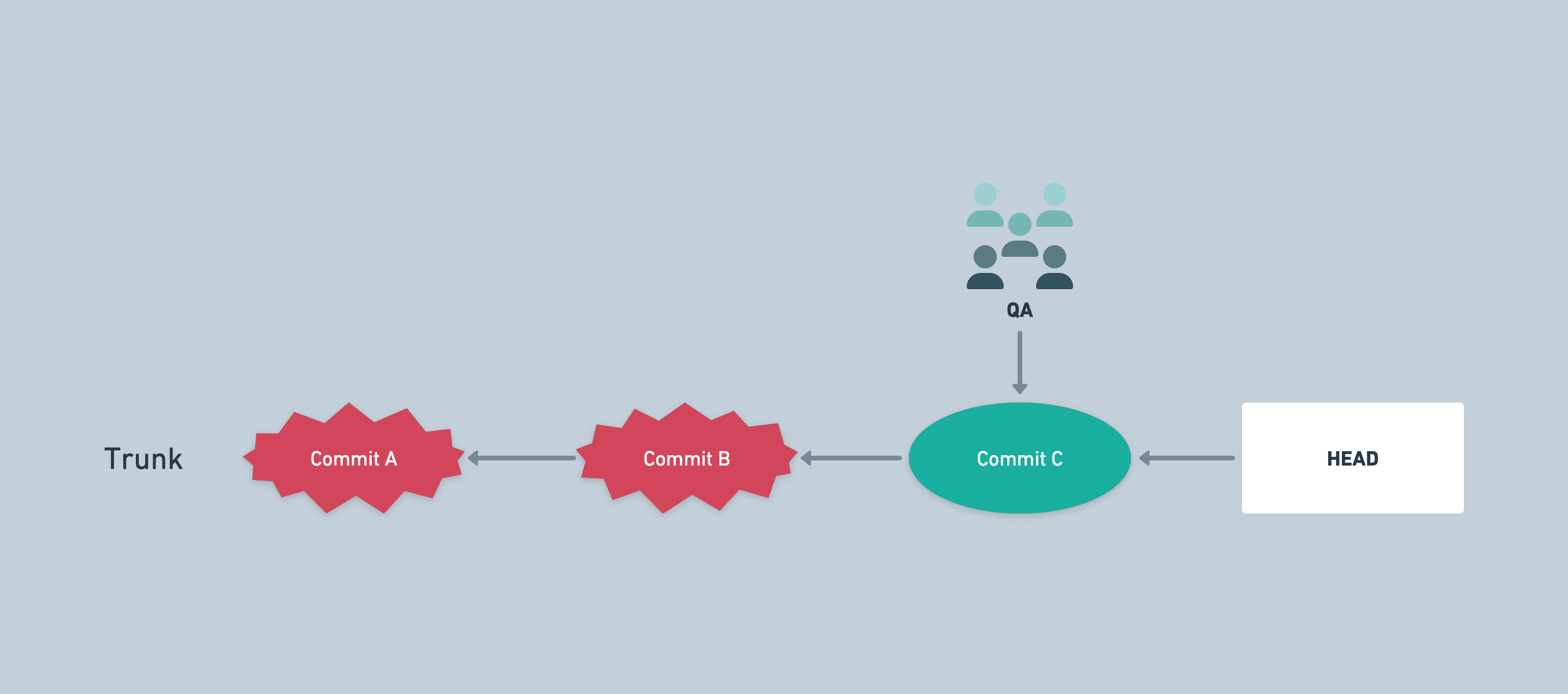
Trunk-based development is something I've wanted to try out. However, it's not that easy to implement in a codebase that doesn't have tests.
I talked a bit about it with my HoE (Head of Engineering) Ahmad Luqman, they presented good views as to why it would not be feasible to implement true CI in our existing system.
The problem with most codebases
There are two main characteristics I've noticed in most codebases:
- No tests (I've done this)
- Running on the same mutable server for a long time
This results in low confidence related to both new features and deployment. It also makes it very hard to add trunk-based development, because new code needs to be tested manually, which is time-consuming.
However, this doesn't mean that we should just ignore the thought of introducing better practices.
I'm trying to pave way to make it easy to adopt trunk-based development with manual QA.
Feature Flags
This is the easiest process to integrate into any workflow. It should work quite well with traditional git-flows.
Example without feature flags
Suppose we have three long-lived branches, which are common in git-flow:
developstagingproduction
I create a new feature without a feature flag, and it gets merged into develop. After this, QA got a bit slow and a few other devs merged their changes into develop. My commits are now buried inside newer commits.
Sometime later, QA finally gets the time to test my feature and it turns to be buggy, because I wrote it :D
However, it's time to merge into staging, but my changes are in-between other feature commits, and my changes cannot be merged into staging as they're broken.
We could try cherry-picking, but it is tedious. If we don't want to cherry-pick, we end up creating complex branching models, which seem more of a temporary workaround than a solution.
Same example with feature flags
Suppose the long-lived branches are the same. This time however, when I code the new feature, I add a small check to see if an environment variable is defined. If not, the feature does not run. This is my simple feature flag.
Again, QA was busy testing other things and other devs merged their code into develop.
QA finally tests my changes (we add the env var in develop deployment for QA), and it turns out to be buggy.
Now, if the time comes to merge develop into staging, and I haven't pushed commits to fix my buggy feature, we can simply merge everything, and just disable the env var that turns on my feature.
This will prevent us from scuttling around trying to find a way to remove my commits while merging. They can live in staging silently. I can then push the fix to develop, merge it into staging, and the feature flag can be turned on once QA approves it's good.
This avoids us having to either cherry-pick or create complex branching models. We still retain our git-flow as it was before the introduction of feature flags.
Incorporating trunk-based development
The main problem
Testing. This is what blocks us from ditching all long-lived branches and simply having a trunk, or mainline.
Potential Solution
Empowering QA to automatically deploy any commit they want in an environment. I believe I had heard this from Dave Farley, but I can't remember which video it was.
Example
Suppose we have a repo on Gitlab with the same three long-lived branches. I push some code. Afterwards, other devs merge their code.
QA needs to test our changes out. In a normal flow, they'd just be testing the HEAD i.e. the latest commit.
To provide them more flexibility, e.g. to test individual features, we give them access to the Gitlab repo, and they are able to deploy any commit from develop, into the development deployment.
They're able to use the development deployment to test out each feature individually by deploying specific commits that only include one new feature. For easier understanding, think that QA is deploying each merge commit that was created after the merge requests, or the latest commit of merge requests if keeping the history linear.
This helps out not bloat the codebase with a lot of feature flags.
We could do something like this:
- Create a feature branch out of
develop - If implementing a new feature, add a feature flag. If doing small changes in existing code, proceed without feature flags if it becomes unnecessary
- Merge to
developquickly (feature branch is short-lived) - If QA finds a new feature buggy and
developneeds to be merged intostaging, disable it with feature flag. If the bug is in modified code, allow QA to find the last good commit (by testing different commits and finding the latest good one).
This allows us to deploy that last good commit if we need to update staging.
If we don't want to deploy into staging, we can wait until a new fix is pushed. QA can test the new commits, or HEAD in this case, and if that's good, we can deploy the HEAD.
QA testing commits
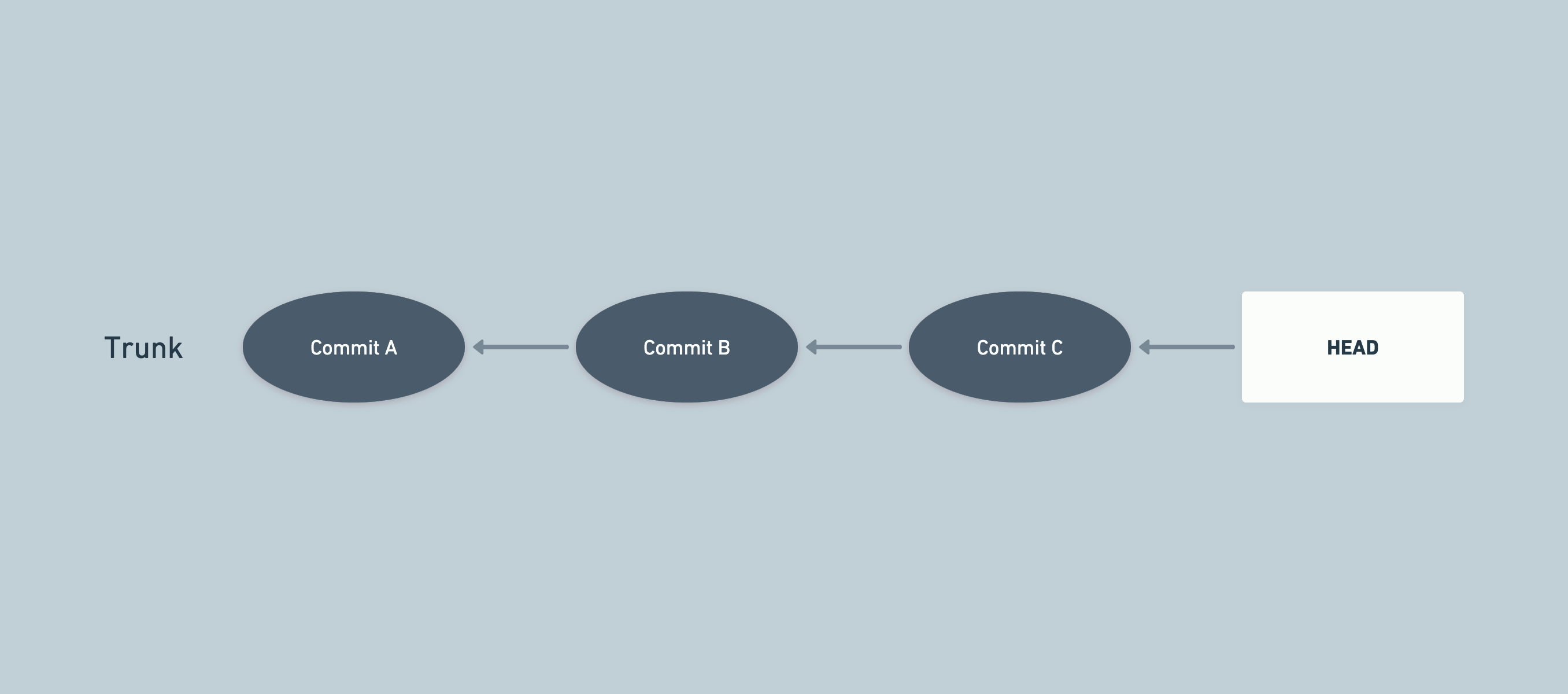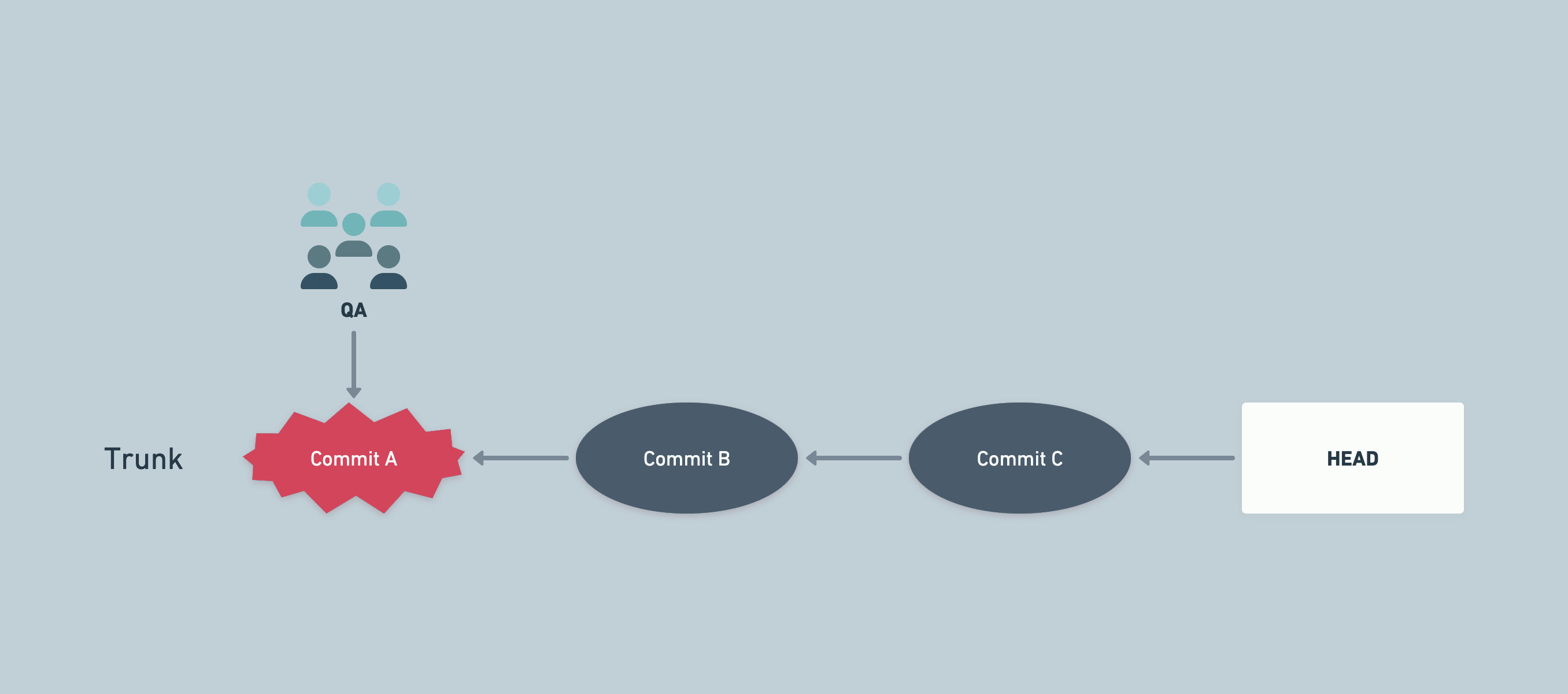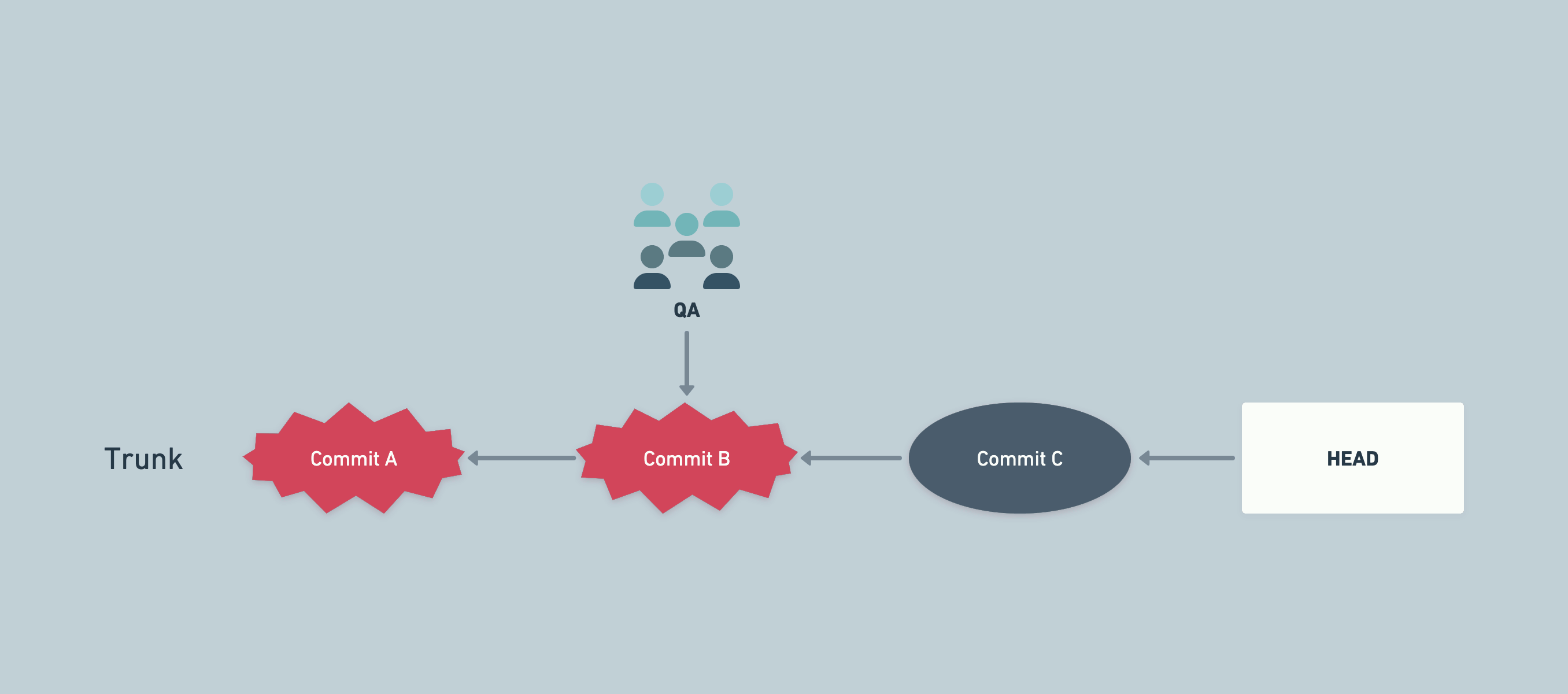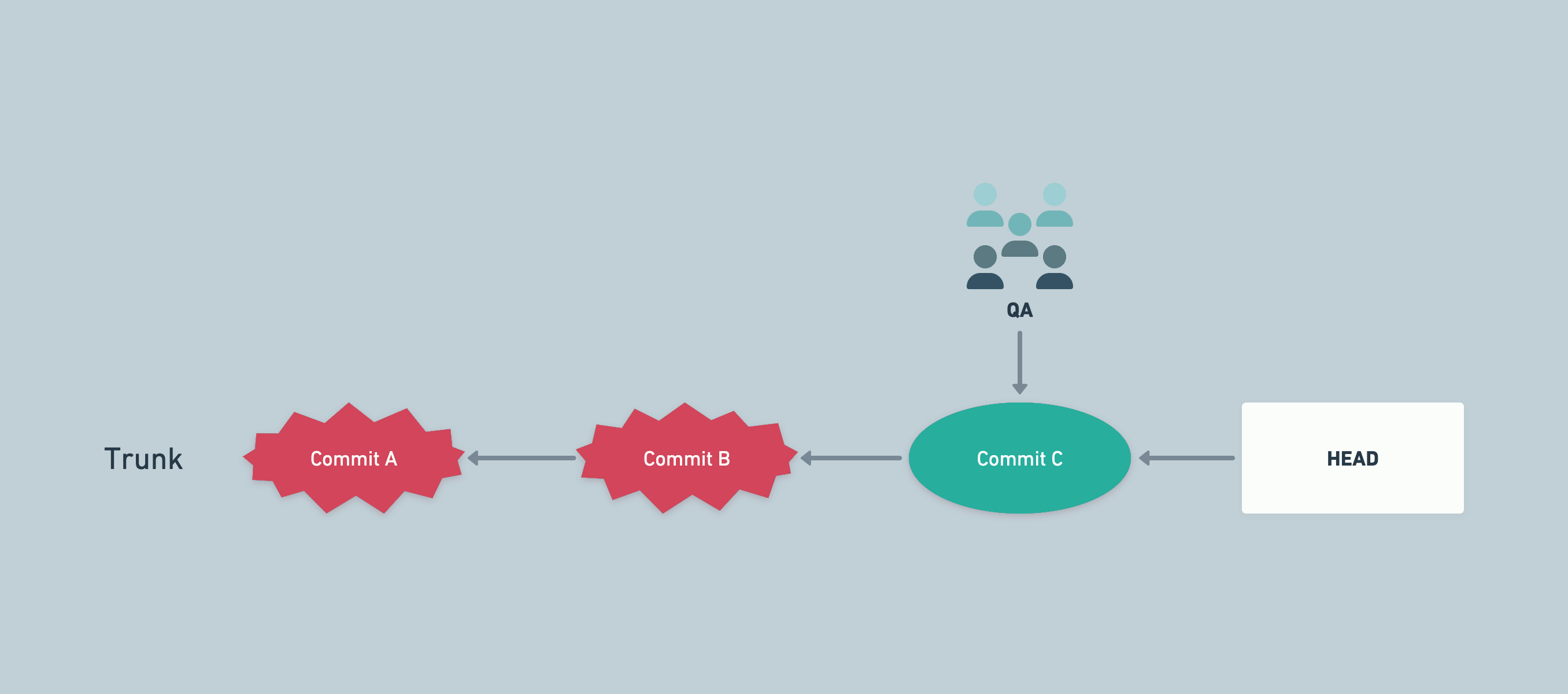
A sample flow combining QA and trunk-based development
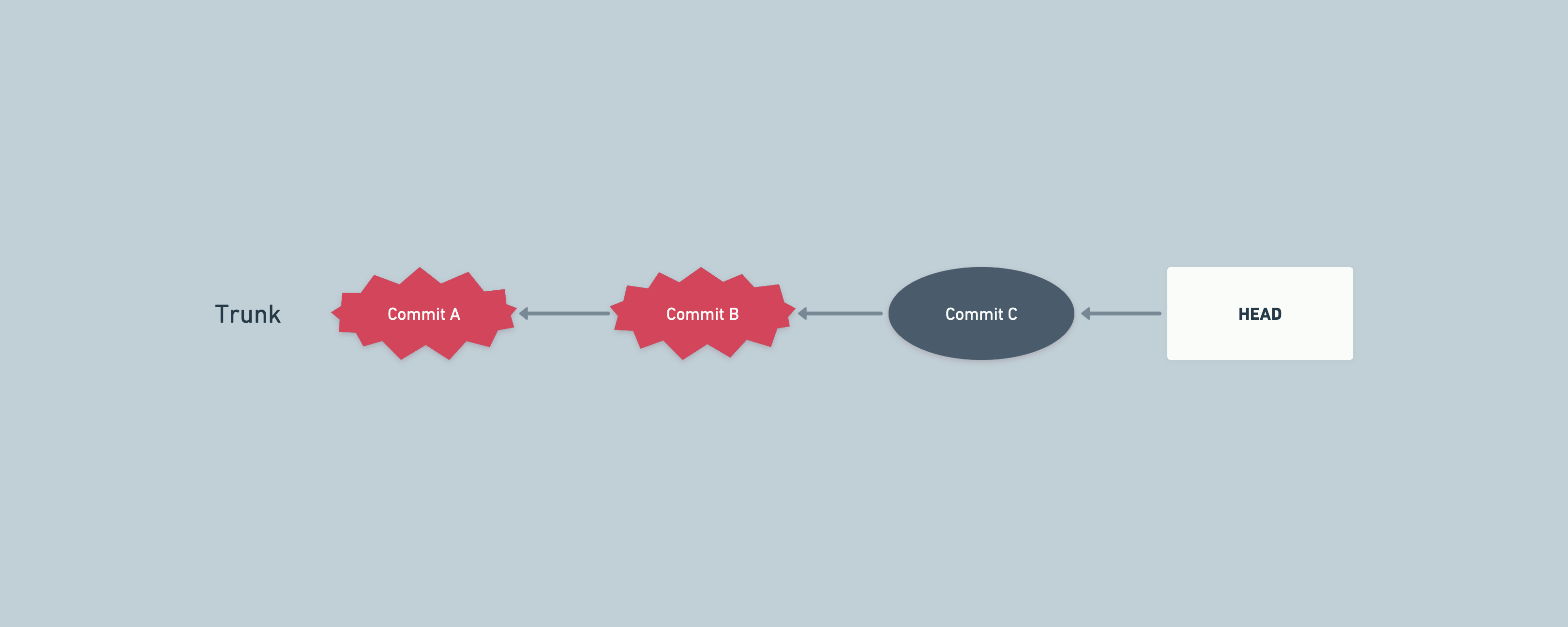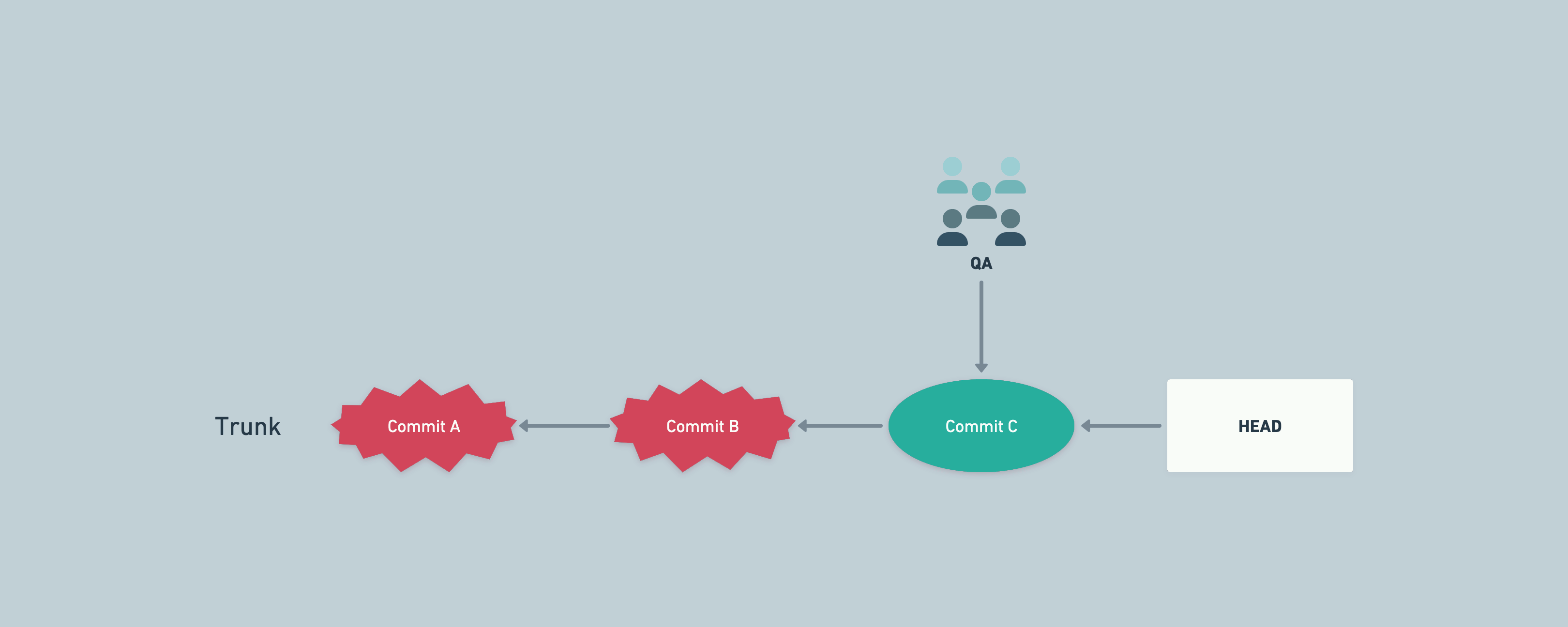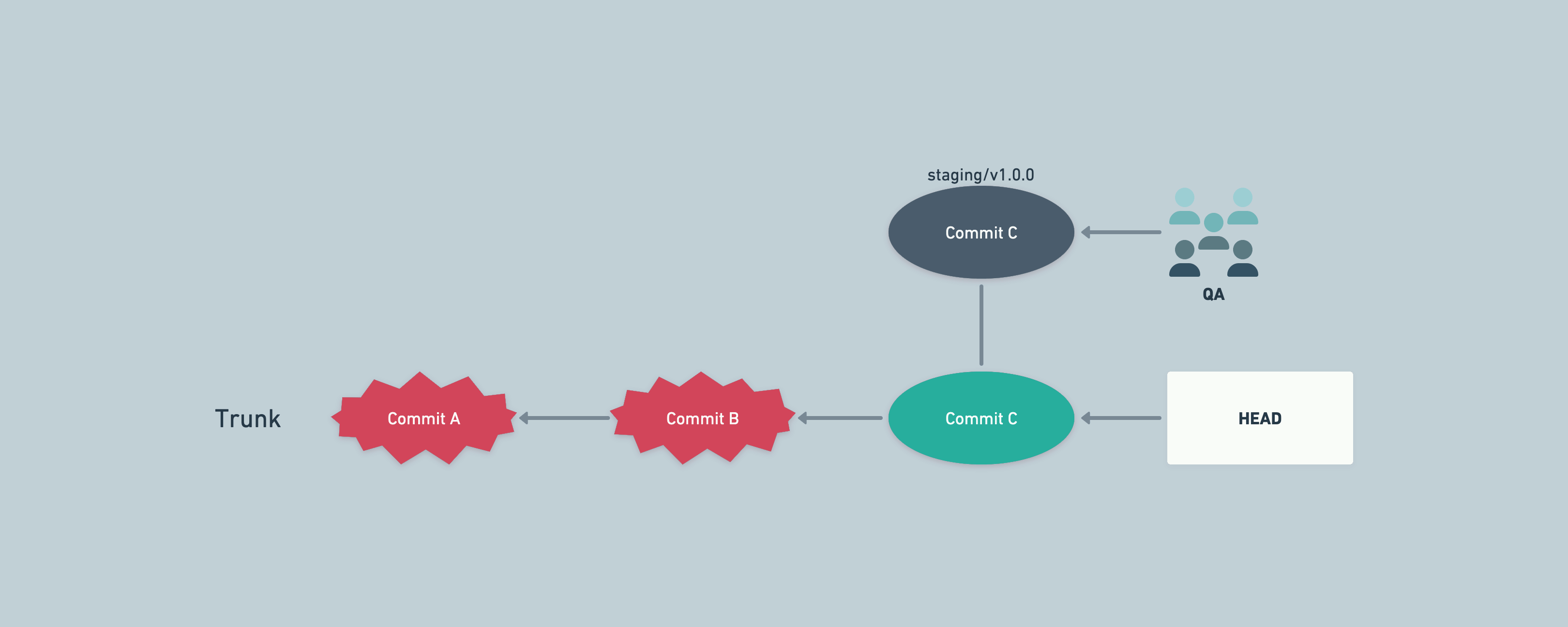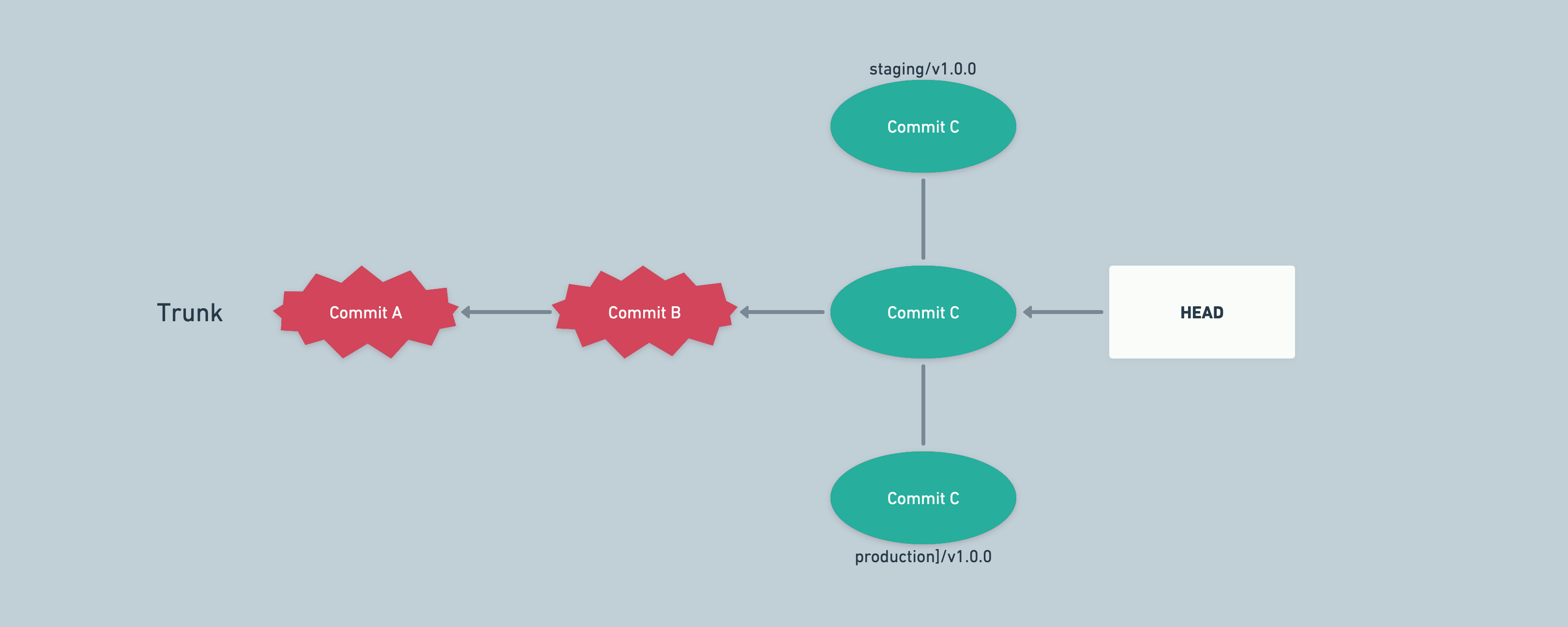
An example of finding bad commits in a later environment (e.g. staging)
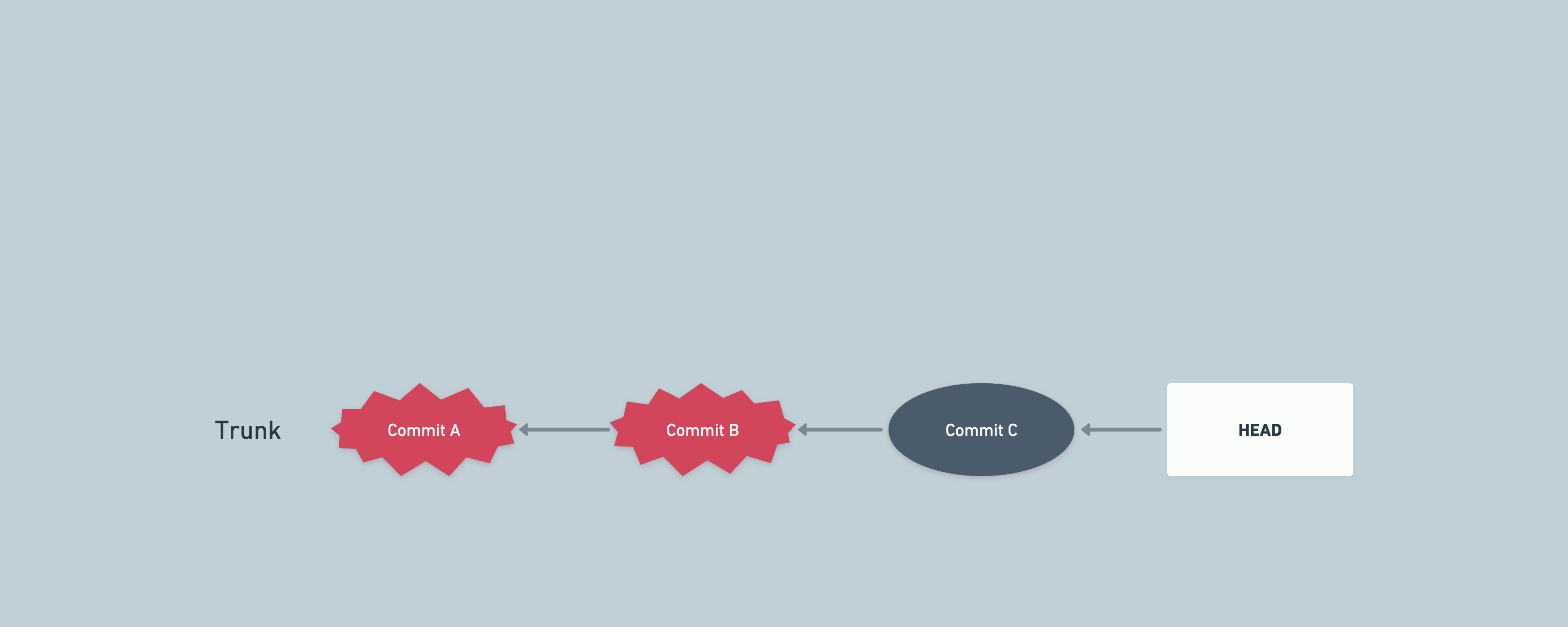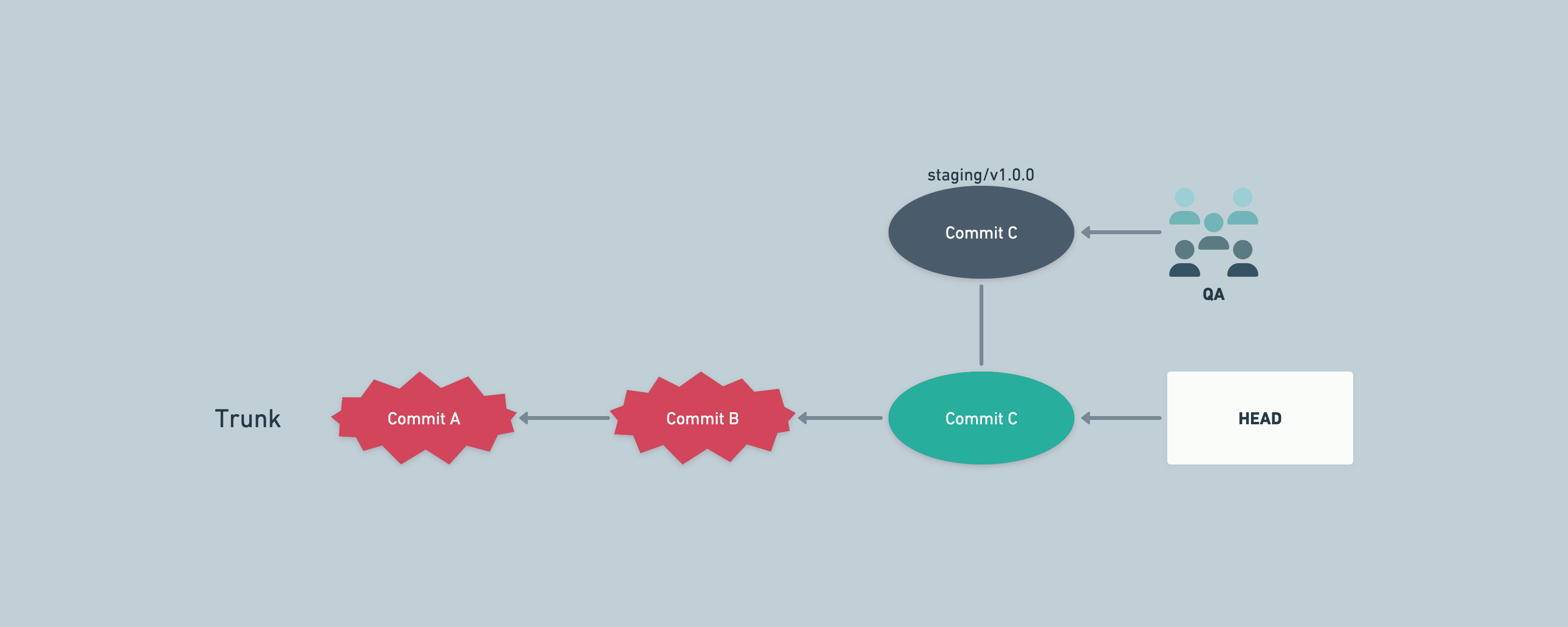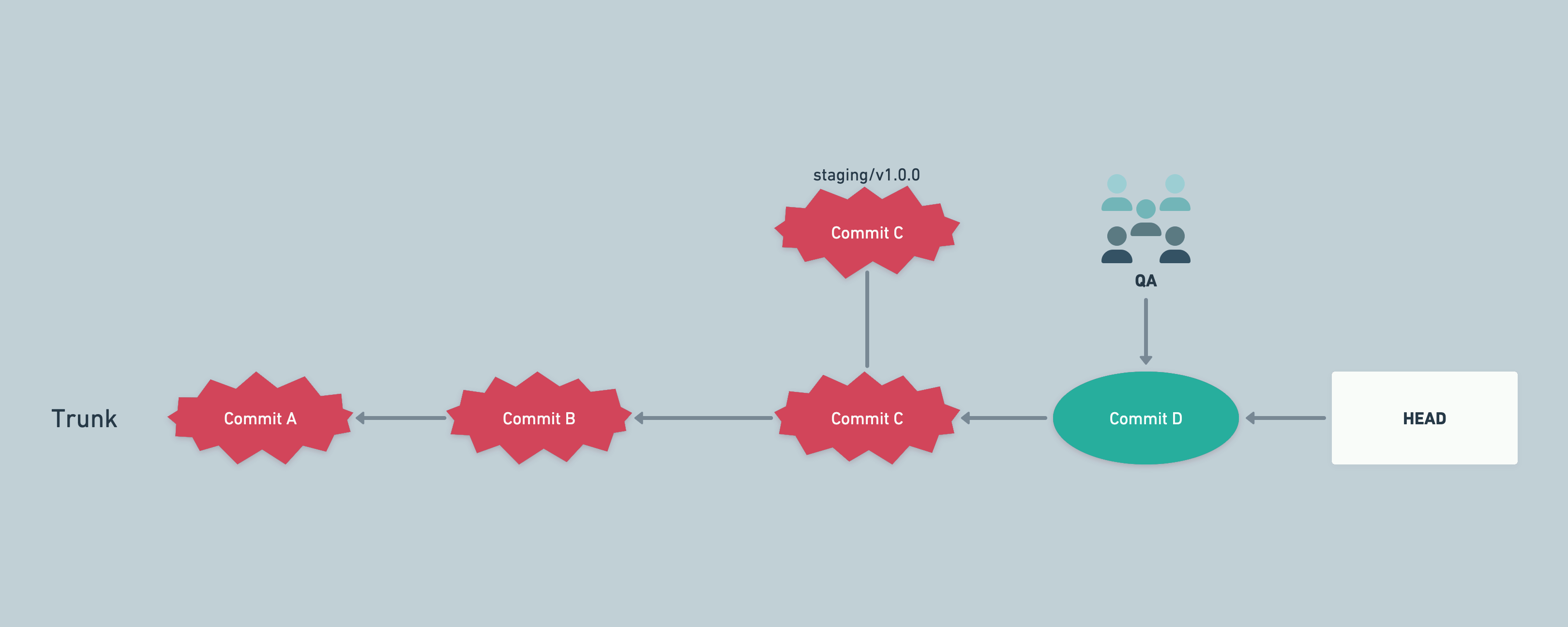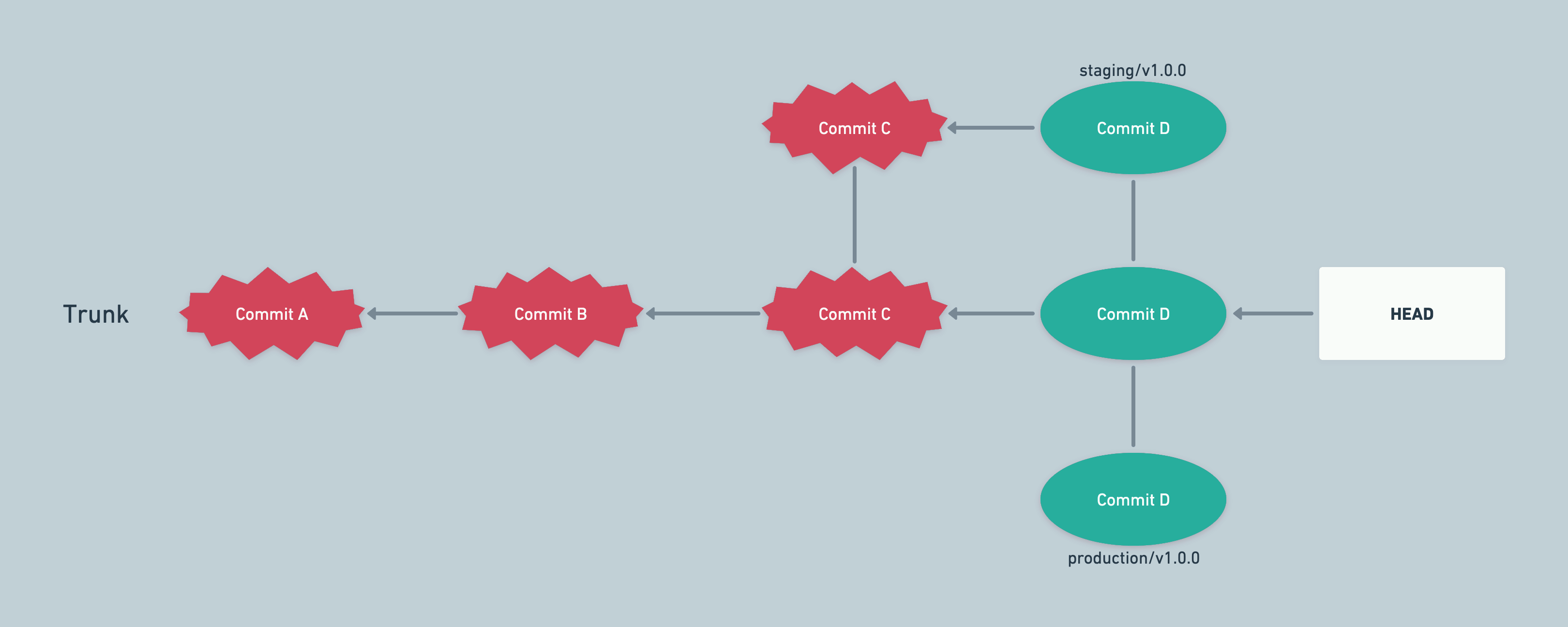
The above could happen if we have different data in development environment, while staging has production data mirrored. Some bugs might remain hidden in development environment because of data being very different across environments.
Subscribe to my newsletter
Read articles from Shehriyar Qureshi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shehriyar Qureshi
Shehriyar Qureshi
Self-taught software engineer from Pakistan. Dabbled in a variety of stacks (node, rust, python).