Application Locking
 Lucian Lazar
Lucian LazarWhether you are a manager or a developer, I’m sure you heard the complaints “the application is slow” or “the application is blocked”. They lead to unhappy clients and even lost contracts. This paper presents a way to get rid of waits and deadlocks caused by database level locking by implementing application locking. The effect is improving the performance and the stability of the applications.
Why Application Locking?
You may wonder why should we use application locking when all major databases have their own locking mechanisms.
The story started – as most performance problems do – with a slow application. It was a multi-user application with a few hundred users, most of the time concurrent, that processed big amounts of data. Sometimes the users complained about long processing times or even errors. After a lot of tracing I found not only a lot of wait events, but also several deadlocks per day. The database locking mechanism was heavy loaded with concurrency issues caused by parallel processing of the common entities. The database could not solve automatically all this processing with database-level locking, causing stability issues, performance issues and generally client insatisfaction.
I needed a solution to decrease the load on the database, especially on the database-level locking. In the end the solution was simple: if this causes problems then let’s stop using database-level locking and replace it with something else.
The solution was adding a new layer where the application sets the locks. When the application starts a process that needs an object, it marks the object in the new layer as locked. When the application finishes the process and does not need the object anymore, it removes the lock from that layer. It is a simple and efficient usage of logical locking that reduces the load on the database-level locking, reduces the database load altogether and ensures consistency and performance.
The new framework performed very well for that application. Replacing database-level locking with application locking removed almost completely the deadlocks and the waits and made the application faster and more stable.
How It Works
The application locking has a similar logic as the database-level locking, with the essential difference that it’s a separate layer used before the database locking.
When the application starts a process that needs to write in a table, it sets an exclusive lock on that table. If a second process needs to write in the same table, it has to wait till the first process completes and removes the lock. After that, the second process can set another exclusive lock on the table.
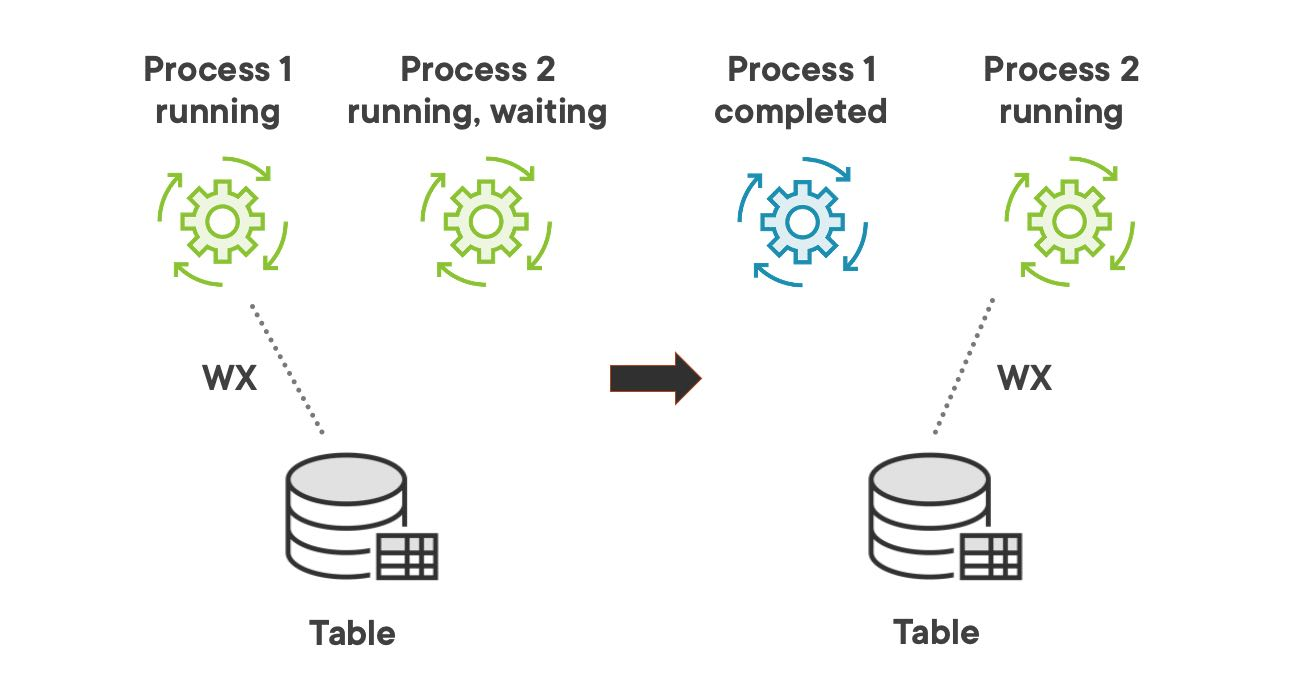
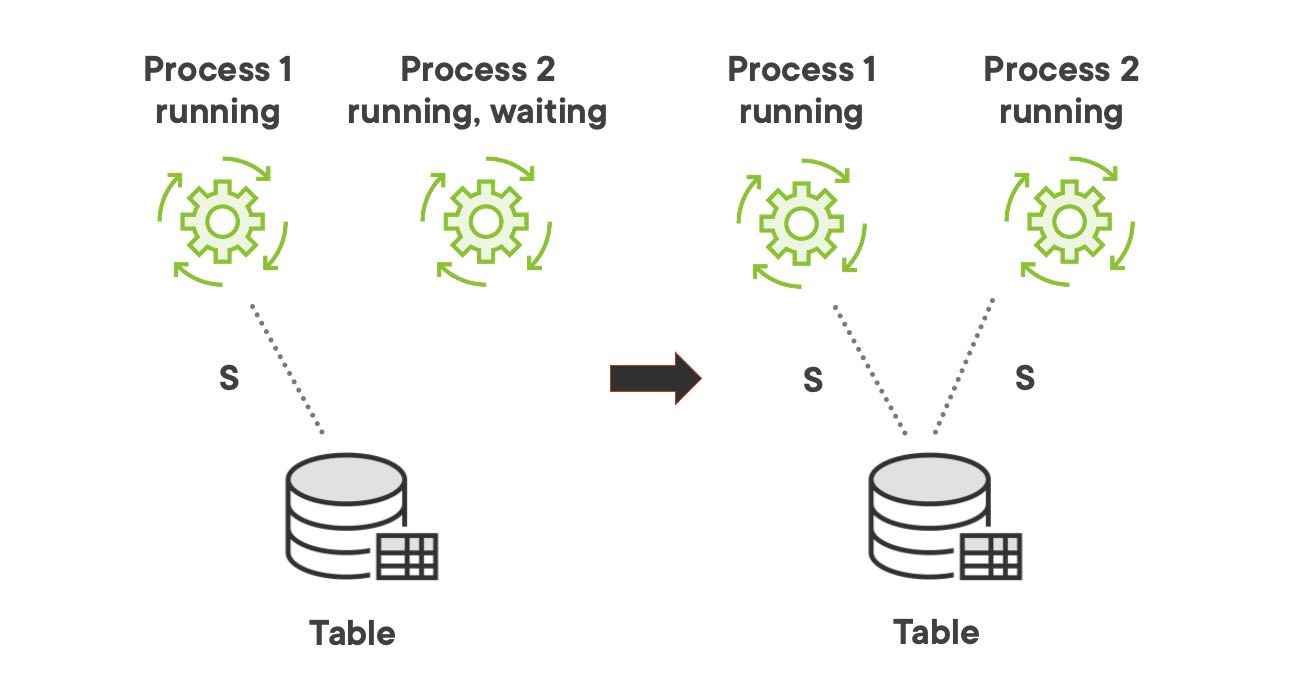
If the first process only needs to read from the table, it sets a shared lock on that table. If the second process also needs only to read from the same table, it does not have to wait till the first process is completed. The second process can set another shared lock on the table immediately and the two process can read in parallel from the same table.
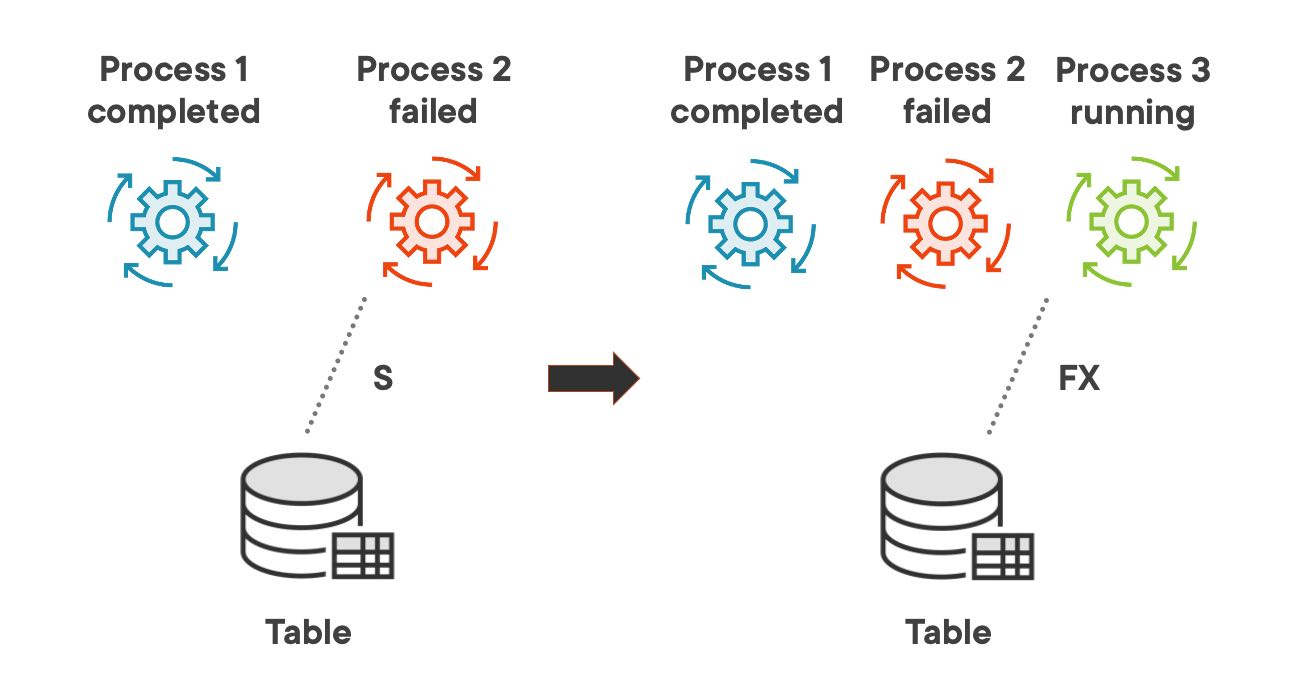
The normal flow for a process is to complete successfully and remove its locks. But sometimes a process might fail and leave orphan locks in the system. In this scenario, a third process cannot set a lock on that table. First, it must first release the orphan lock left by the failed process and only then it can set its own lock.
PL/SQL Application Locking Framework
Let’s see what exactly is this framework.
PL/SQL Application Locking is a PL/SQL framework that implements logical locking of objects at application level for applications that use Oracle databases. Its main effects are decreasing the load on the database and improving the stability and performance of the applications.
You can download it from the project page on Gitlab and integrate it freely in your application or translate it for Microsoft, Postgres or other databases. For a custom and complex implementation we can collaborate, extend the functionality and tailor the framework to your specific needs.
Content
Let’s dive in the technical content of the framework.
The framework consists of two tables: process runs and application locks and two packages: processing and application locking. This section explains the essential characteristics of the objects and has links to the project wiki with technical details of the logic, structure, parameters and call examples.
The process runs table and the processing package are generic and can map to existing objects in your application. The process runs table stores process runs identified uniquely by a run id and having as attributes start time, end time and a run status that can be running, completed successfully or failed.
create table process_runs(
run_id integer,
process_name varchar2(10),
run_status integer, -- 0 = running, 1 = success, 2 = fail
run_start timestamp,
run_end timestamp);
The processing package has two procedures: start process that starts a process with status running and end process that completes a process run and updates its status to successful or failed.
create or replace package processing as
procedure start_process(
pi_process_name in varchar2);
procedure end_process(
pi_run_id in integer,
pi_run_status in integer);
end;
The application locks table is the core of the framework and stores the logical locks set by the client. A lock is identified uniquely by a lock id, is set on a certain object by a certain process run id and can have three modes: shared, write exclusive or full exclusive.
create table application_locks(
lock_id integer,
resource_name varchar2(10),
lock_mode integer, -- 1 = S, 2 = WX, 3 = FX
run_id integer);
The application locking package contains the logic of the framework encapsulated in four procedures: acquire lock that adds a logical lock to a certain object by a certain run id, respecting an algorithm that allows upgrading certain lock modes, release locks that deletes the locks at the end of a process, get locks that lists the locks on a certain object and release orphan locks that deletes orphan locks on a certain resource left by completed process runs.
create or replace package application_locking as
procedure acquire_lock(
pi_resource_name in varchar2,
pi_lock_mode in integer,
pi_run_id in integer,
po_lock_id out integer);
procedure release_locks_for_run(
pi_run_id in integer,
po_released_locks out integer,
po_remaining_locks out integer);
procedure get_locks_on_resource(
pi_resource_name in varchar2,
po_locks out sys_refcursor);
procedure release_orphan_locks_on_resource(
pi_resource_name in varchar2,
po_released_locks out integer,
po_remaining_locks out integer);
end;
Download and Install
Run the objects.sql script that creates all the objects contained by the framework. For technical details about the usage of all procedures check the objects page in project wiki. You will need to have access to an Oracle database to run the script there or you can translate it for Microsoft, Postgres or other databases. You can replace the process runs table and the processing package with existing objects in your application and replace their references in the application locking package.
Demo
Run the demo.sql script that contains examples of using the framework and handle different flows. The demo page in project wiki contains more technical details about the flows in the testing scenarios with print screens and explications for all the procedure calls and data in the tables at each step.
The demo contains all the flows of using the PL/SQL Application Locking framework with different scenarios for acquire locks, release locks and release orphan locks.
Acquire Locks
In the acquire locks section of the demo we start two process runs and set different application locks on two tables for these two processes. Only one process can set a write exclusive application lock on a table at a time to write in it and two parallel processes can set shared application locks on the same table at the same time to read from it.
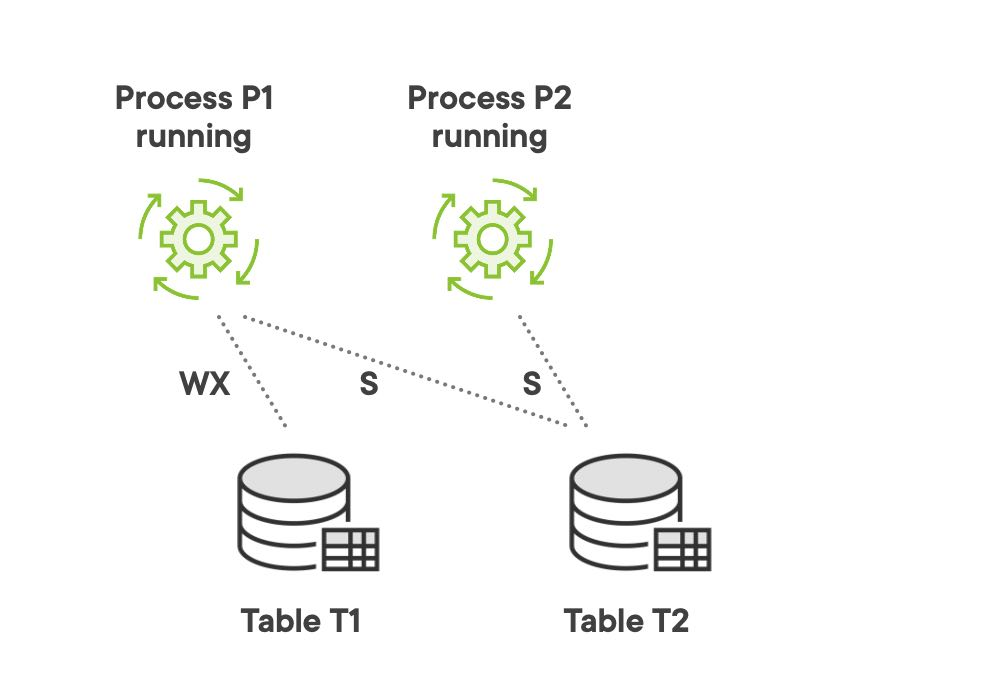
Let’s see the code for these steps. We start process P1 using the procedure start_process in package processing, set a WX lock on table T1 and a S lock on table T2 using the procedure acquire_lock in package application_locking. Then we start process P2 and set a S lock on table T2. For more technical details about the calls check the acquire lock page in project wiki.
-- start process P1
begin
processing.start_process('P1');
end;
-- P1 acquires WX lock on table T1
declare
v_lock_id integer;
begin
application_locking.acquire_lock('T1', 2, 1, v_lock_id);
end;
-- P1 acquires S lock on table T2
declare
v_lock_id integer;
begin
application_locking.acquire_lock('T2', 1, 1, v_lock_id);
end;
-- start process P2
begin
processing.start_process('P2');
end;
-- P2 acquires S lock on table T2
declare
v_lock_id integer;
begin
application_locking.acquire_lock('T2', 1, 2, v_lock_id);
end;
Release Locks
In the release locks section we complete the two process runs and release the application locks for one of these two processes. The first process completes successfully and releases its locks, while the second process fails and does not release its locks, leaving behind an orphan lock in the system.
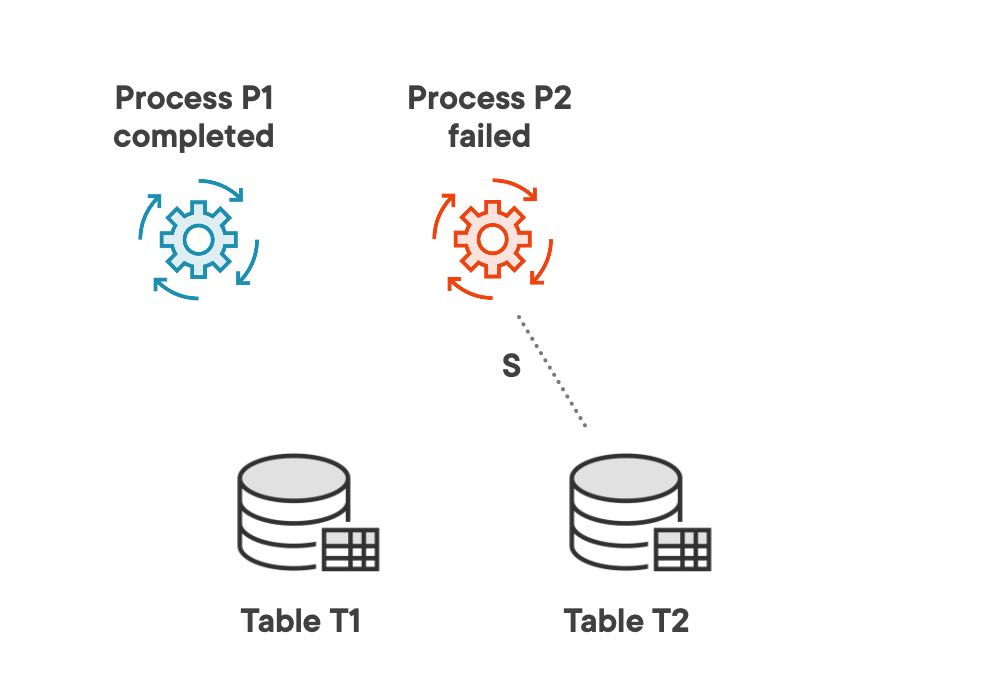
We complete process P1 with status completed successfully and release its locks on tables T1 and T2 using the procedure end_process in package processing. Then we complete process P2 with status failed and do not release its locks, leaving an orphan lock on table T2. For more technical details about the calls check the release locks page in project wiki.
-- complete process P1 successfully and release its locks
declare
v_released_locks integer;
v_remaining_locks integer;
begin
processing.end_process(1, 1);
application_locking.release_locks_for_run(1, v_released_locks, v_remaining_locks);
end;
-- complete process P2 with errors and do not release its locks
begin
processing.end_process(2, 2);
end;
Release Orphan Locks
In the release orphan locks section we start a third process that needs to use a table which remained locked by another completed process and see how it releases that orphan lock. After failing to acquire a lock on the table already locked, the third process checks the locks on that resource, confirms that there is an orphan lock and releases it. After the orphan lock is released, the third process will be able to acquire the lock on the table.
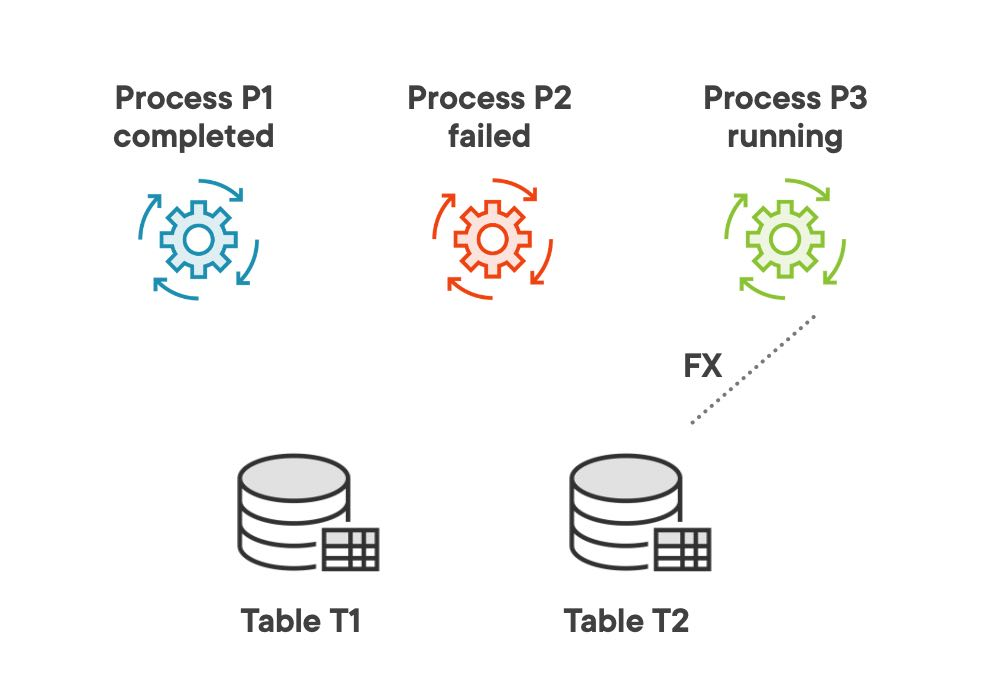
We start process P3, try to set FX lock on table T2 and fail because the table is already locked. Then process P3 checks the locks on table T2 using the procedure get_locks_on_resource in package application_locking and releases the orphan lock on table T2 using the procedure release_orphan_locks_on_resource. The orphan lock is deleted and process P3 can acquire FX lock on table T2. For more technical details about the calls check the release orphan locks page in project wiki.
-- start process P3
begin
processing.start_process('P3');
end;
-- P3 tries to acquire FX lock on table T2 and fails
declare
v_lock_id integer;
begin
application_locking.acquire_lock('T2', 3, 3, v_lock_id);
end;
-- P3 checks the locks on table T2
declare
c_locks sys_refcursor;
v_lock_id integer;
v_lock_mode integer;
v_run_id integer;
v_run_status integer;
begin
application_locking.get_locks_on_resource('T2', c_locks);
loop
fetch c_locks into v_lock_id, v_lock_mode, v_run_id, v_run_status;
exit when c_locks%notfound;
dbms_output.put_line('Lock id ' || v_lock_id);
end loop;
end;
-- P3 releases the orphan lock on table T2
declare
v_released_locks integer;
v_remaining_locks integer;
begin
application_locking.release_orphan_locks_on_resource('T2', v_released_locks, v_remaining_locks);
end;
Extended Functionality and Final Thoughts
PL/SQL Application Locking is a free and functional framework. You can download it and integrate it freely in your application or translate it for other databases. It will help you to decrease the load on the database and improve the stability and performance of the application.
For a custom implementation with high concurency that needs high performance and stability we can extend its functionality with advanced features like:
extended acquire lock mechanism with serializing access to resources, retry modes and exception handling
upgrade and downgrade lock mechanism
extended release orphan locks mechanism with exception handling, performance tweaks and more possible release conditions
release all orphan locks mechanism included in a clean-up process ran in case of database recovery.
Contact me on my website www.lucianlazar.com and we can collaborate to tailor the framework to your specific needs.
If you have any comments or questions about this paper, please post them in the comments section below or message me directly.
Subscribe to my newsletter
Read articles from Lucian Lazar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Lucian Lazar
Lucian Lazar
I have over 15 years experience in consulting and teaching. I work as software developer for Optymyze, teach at Alexandru Ioan Cuza University, create video courses for Pluralsight and share code projects on Github. Find out more at: https://www.lucianlazar.com/