Step-by-step example of creating single-table RELATIONAL data models with DynamoDB
 Luuk
Luuk
Often when creating small web-applications in the past, the burden of having to set up and manage a relational database seemed daunting to me. Even with AWS' managed RDS layer on top of it, I still shuddered at the thought of having to manage this in a production environment myself. And while I've always liked the idea of a completely serverless database like dynamoDB, I never really understood how to utilise it efficiently, especially with highly relational data. That is, until I came across the adjacency list pattern. It took me a while to wrap my head around the logic behind it, so in this blog I'll try to decompose the brain-wrangling documentation AWS provides on this topic by providing a step-by-step example guide on how this pattern works.
Since this is a relatively advanced pattern, I assume you kind-of know the basics on DynamoDB (e.g. what is a partition key and how dynamoDB is queried with the CLI).
What is the adjacancy list pattern
According to the AWS docs:
Adjacency lists are a design pattern that is useful for modeling many-to-many relationships in Amazon DynamoDB. More generally, they provide a way to represent graph data (nodes and edges) in DynamoDB.
In other words, it allows you to model highly relational data in a datastore which requires almost no operational overhead! If you're not excited by now, you probably are much more of a DBA than me 😃.
You can read more on the pattern here, get confused, and then read the sections below to understand what is going on. I can't promise you won't be confused, but hopefully you'll get it faster than me!
Step by step dissection of the adjacency list pattern
To get a better understanding of the adjacency list pattern, we build it up from scratch, supporting more and more access patterns with each step. Eventually we will have a SINGLE TABLE that allows for flexible queries on many-to-many data sets.
The example use-case
Consider the case of a banana delivery service, which ships their containers overseas. These containers are filled with pallets and each pallet contains a number of boxes with delicious bananas in them. These items and their relations are shown schematically below.
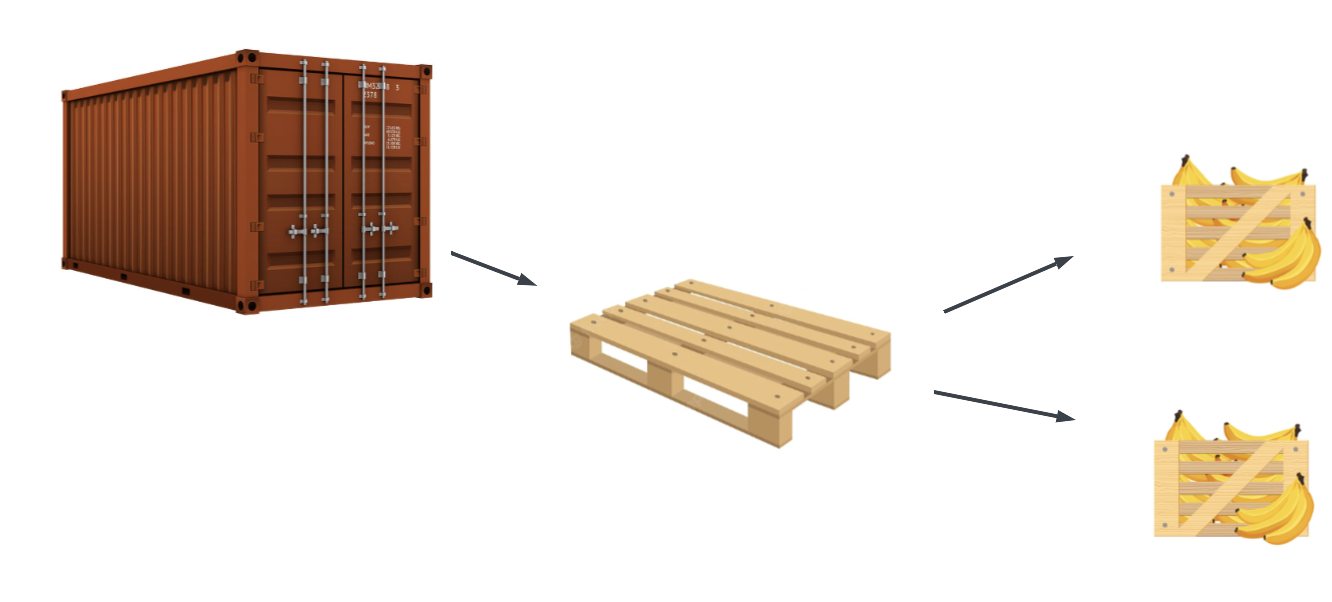
In table form, you can think of the individual items and their properties like this:
| Object Type | Item Identifier | Attributes |
| Container | 009998 | Operator=TheBoatingCompany, ... |
| Pallet | B021002 | Origin=BR, Destination=DE, ... |
| Box | A03828 | WeightInKg=20.56, IsDangerous=false, .... |
| Box | A03829 | WeightInKg=21.20, IsDangerous=false, ... |
| ... | ... | ... |
In the next sections, we'll setup a data model to allows for a flexible range of queries on this dataset in dynamoDB.
Step 1: Querying information about different types of items
If we want to store information about these items in a single table, one trick we can use is concatenating the item type with the identifier, to create a unique ID per item. So for example:
- Container with identifier
009998=>CONTAINER_009998 - Box with identifier
A03828=>BOX_A03828
This allows items with the same unique identifier to exist alongside each other, as well as additional benefits we'll use later on in this blog. We'll call the column containing these fields objectId since it contains identifiers for any type of object.
| objectId (partition key) | Attributes |
| CONTAINER_009998 | Operator=TheBoatingCompany, ... |
| PALLET_B021002 | Origin=BR, Destination=DE, ... |
| BOX_A03828 | WeightInKg=20.56, IsDangerous=false, .... |
| BOX_A03829 | WeightInKg=21.20, IsDangerous=false, ... |
Now you can query for information on a certain item by for example calling:
aws dynamodb get-item \
--table-name my-table-name \
--key '{"objectId":{"S":"CONTAINER_009998"}'
# Returns attributes of container 009998
Step 2: Adding query support to related objects
It's great that we can now store and retrieve data about objects, but often we also want to know attributes of any items related to our object. To support this, we add an extra field called relatedObjectId that we can use to store relations between objects. For example, in the case of the container and the pallets:
| objectId (partition key) | relatedObjectId | Attributes |
| CONTAINER_009998 | PALLET_B021002 | LinkedDatetime=2022-07-19T17:59:58Z, LinkedBy=MyLoadingCompany, LinkedAtLocation=JPA.Docks |
| CONTAINER_009998 | PALLET_B021003 | LinkedDatetime=2022-07-19T18:01:58Z, LinkedBy=MyLoadingCompany, LinkedAtLocation=JPA.Docks |
SIDENOTE: These entries does not contain any attributes about the objects themselves, but rather attributes on the RELATION between the objects (e.g. when or where the relation was made, what type of relation they have).
But now a problem arises! To see why, remember that when querying dynamoDB, each entry must have a unique primary key. The primary key consists of partition key and and optional sort key. In the table above we use the same (❌) partition key, and thus primary key, for both entries (CONTAINER_009998)!
To get rid of this issue, we can make relatedObjectId a sort key:
| objectId (partition key) | relatedObjectId (sort key) | Attributes |
| CONTAINER_009998 | PALLET_B021002 | LinkedDatetime=2022-07-19T17:59:58Z, LinkedBy=MyLoadingCompany, LinkedAtLocation=JPA.Docks |
| CONTAINER_009998 | PALLET_B021003 | LinkedDatetime=2022-07-19T18:01:58Z, LinkedBy=MyLoadingCompany, LinkedAtLocation=JPA.Docks |
| PALLET_B021002 | BOX_A03828 | LinkedDatetime=2022-07-19T10:13:12Z, LinkedBy=MyWarehouseCompany, LinkedAtLocation=TheWarehouseBuilding |
| PALLET_B021002 | BOX_A03829 | LinkedDatetime=2022-07-19T10:13:34Z, LinkedBy=MyWarehouseCompany, LinkedAtLocation=TheWarehouseBuilding |
Now, each entry has a unique primary key (✔️), since the combination of partition key and sort key is unique for each entry: CONTAINER_009998 and PALLET_B021002 is different from CONTAINER_009998 and PALLET_B021003.
To query the information about relations, we can now for example use:
aws dynamodb query \
--table-name my-table-name \
--key-condition-expression "objectId = :objectId and begins_with(relatedObjectId, :prefix)"
--expression-attribute-values '{":objectId":{"S":"CONTAINER_009998"}, ":prefix": {"S": "PALLET"}'
This queries all entries for container 009998 where the related object is a pallet.
Step 3: Fixing the initial query
Now we can query information about relations, let's add back the items containing information about the objects themselves from step 1. As you can see below, we've introduced a problem by making the relatedObjectId a mandatory sort key.
| objectId (partition key) | relatedObjectId (sort key) | Attributes |
| CONTAINER_009998 | ?? | Operator=TheBoatingCompany, ... |
| CONTAINER_009998 | PALLET_B021002 | LinkedDatetime=2022-07-19T17:59:58Z, LinkedBy=MyLoadingCompany,LinkedAtLocation=JPA.Docks |
| CONTAINER_009998 | PALLET_B021003 | LinkedDatetime=2022-07-19T18:01:58Z, LinkedBy=MyLoadingCompany,LinkedAtLocation=JPA.Docks |
| PALLET_B021002 | ?? | Origin=BR, Destination=DE, ... |
| PALLET_B021002 | BOX_A03828 | LinkedDatetime=2022-07-19T10:13:12Z, LinkedBy=MyWarehouseCompany,LinkedAtLocation=TheWarehouseBuilding |
| PALLET_B021002 | BOX_A03829 | LinkedDatetime=2022-07-19T10:13:34Z, LinkedBy=MyWarehouseCompany,LinkedAtLocation=TheWarehouseBuilding |
| BOX_A03828 | ?? | WeightInKg=20.56, IsDangerous=false, .... |
| BOX_A03829 | ?? | WeightInKg=21.20, IsDangerous=false, ... |
Fortunately, this is easily fixed. We simply agree on the fact that for entries that contain attributes of the object itself, the relatedObjectId is the same as the objectId. So the table becomes:
| objectId (partition key) | relatedObjectId (sort key) | Attributes |
| CONTAINER_009998 | CONTAINER_009998 | Operator=TheBoatingCompany, ... |
| CONTAINER_009998 | PALLET_B021002 | LinkedDatetime=2022-07-19T17:59:58Z, LinkedBy=MyLoadingCompany,LinkedAtLocation=JPA.Docks |
| CONTAINER_009998 | PALLET_B021003 | LinkedDatetime=2022-07-19T18:01:58Z, LinkedBy=MyLoadingCompany,LinkedAtLocation=JPA.Docks |
| PALLET_B021002 | PALLET_B021002 | Origin=BR, Destination=DE, ... |
| PALLET_B021002 | BOX_A03828 | LinkedDatetime=2022-07-19T10:13:12Z, LinkedBy=MyWarehouseCompany, LinkedAtLocation=TheWarehouseBuilding |
| PALLET_B021002 | BOX_A03829 | LinkedDatetime=2022-07-19T10:13:34Z, LinkedBy=MyWarehouseCompany, LinkedAtLocation=TheWarehouseBuilding |
| BOX_A03828 | BOX_A03828 | WeightInKg=20.56, IsDangerous=false, .... |
| BOX_A03829 | BOX_A03829 | WeightInKg=21.20, IsDangerous=false, ... |
To query the attributes related to the container itself, we now use
aws dynamodb get-item \
--table-name my-table-name \
--key '{"objectId":{"S":"CONTAINER_009998"}, "relatedObjectId":{"S":"CONTAINER_009998"}}'
# Still returns all attributes of container 009998
It might seem a bit clunky, but computers don't really seem to care about that anyway :).
NOTE: At this point, we could have chosen any value for the
relatedObjectId, but as we'll see in the next step it comes in handy to just duplicate the first column instead.
Step 4: Adding reverse lookups
At this point, we can get data on objects, and on objects related to containers, pallets and boxes. This means that we can get all pallets or boxes related to a container. But what if we want to know the reverse? For example, we have a pallet ID, and we want to know what container it belonged to? Since DynamoDB only supports queries WITHIN a single partition (for good reason), we are limited by which of the two objects we choose for the objectId and which one for the targetObjectId. In other words:
| objectId (partition key) | relatedObjectId (sort key) | Attributes |
| CONTAINER_009998 | PALLET_B021002 | LinkedDatetime=2022-07-19T17:59:58Z, LinkedBy=MyLoadingCompany,LinkedAtLocation=JPA.Docks |
is different from
| objectId (partition key) | relatedObjectId (sort key) | Attributes |
| PALLET_B021002 | CONTAINER_009998 | LinkedDatetime=2022-07-19T17:59:58Z, LinkedBy=MyLoadingCompany,LinkedAtLocation=JPA.Docks |
Even though they contain the same data, the former supports queries GIVEN the container ID, while the latter supports queries GIVEN the pallet ID. To support both you either need to create duplicate rows, or we do something smarter. I propose the latter.
To be able to support both query patterns, we create a global secondary index (GSI) on the table. A GSI is basically a 'copy' of your table with different partition and sort keys. For this GSI, we make the targetObjectId the partition key and the objectId the sort key (so the roles are reversed!). This looks like the following:
Index reverse-lookup-index:
| relatedObjectId (partition key) | objectId (sort key) | Attributes |
| CONTAINER_009998 | CONTAINER_009998 | Operator=TheBoatingCompany, ... |
| PALLET_B021002 | CONTAINER_009998 | LinkedDatetime=2022-07-19T17:59:58Z, LinkedBy=MyLoadingCompany,LinkedAtLocation=JPA.Docks |
| PALLET_B021003 | CONTAINER_009998 | LinkedDatetime=2022-07-19T18:01:58Z, LinkedBy=MyLoadingCompany,LinkedAtLocation=JPA.Docks |
| CONTAINER_009998 | PALLET_B021002 | Origin=BR, Destination=DE, ... |
| BOX_A03828 | PALLET_B021002 | LinkedDatetime=2022-07-19T10:13:12Z, LinkedBy=MyWarehouseCompany, LinkedAtLocation=TheWarehouseBuilding |
| BOX_A03829 | PALLET_B021002 | LinkedDatetime=2022-07-19T10:13:34Z, LinkedBy=MyWarehouseCompany, LinkedAtLocation=TheWarehouseBuilding |
| BOX_A03828 | BOX_A03828 | WeightInKg=20.56, IsDangerous=false, .... |
| BOX_A03829 | BOX_A03829 | WeightInKg=21.20, IsDangerous=false, ... |
And now we are basically in the same situation as before, but now we support queries in both directions! For example, getting the pallets related to a container:
aws dynamodb query \
--table-name my-table-name \
--key-condition-expression "objectId = :objectId and begins_with(relatedObjectId, :prefix)"
--expression-attribute-values '{":objectId":{"S":"CONTAINER_009998"}, ":prefix": {"S": "PALLET"}'
Or getting the containers related to a pallet:
aws dynamodb query \
--table-name my-table-name \
--index reverse-lookup-index \
--key-condition-expression "relatedObjectId = :relatedObjectId and begins_with(objectId, :prefix)"
--expression-attribute-values '{":relatedObjectId":{"S":"PALLET_B021002"}, ":prefix": {"S": "CONTAINER"}'
If you want to fetch more attributes of the related objects, you can first perform a query like above, and then a BatchGetItem with the objectId's returned by the query. If this is too big of an operation, you can choose to store the relevant fields in the entries representing relations instead. This way, you only need to query once.
Summary
So in the last 4 steps we've created a data model for infinite types of objects and infinite types of relations, which all fit in a single table!
We've been able to do so by choosing
- A partition key called
objectId - A sort key called
relatedObjectId - If the entry contains attributes about a single object, use the same value for
objectIdandrelatedObjectId - If the entry contains attributes about the relation between two objects, use one ID for
objectIdand the other forrelatedObjectId. Be consistent in how the object types are handled.
If relations should be bi-directionally queryable, you can create a global secondary index and swapping the partition key and sort key of the original table.
Additional notes about this setup
Cost implications for this pattern
Note that by adding a GSI to your table, you are essentially doubling the cost for data ingestion in your table. If you have a write-heavy database, be mindful that you pay for both the entry inserted in the table, and again for any index that is affected by this insert.
Real life experience using this pattern
For one of my customers, this pattern was implemented to create a highly scalable database. The pattern matched the requirements exceptionally well because database load was highly fluctuating between 1000 writes per hour and 200K writes per hours. This made DynamoDB on-demand mode perfect for our use-case.
We've been able to support this load at an average cost of ±2$ per day for DynamoDB, and throughput scaling incredibly fast to meet our demand. Typical response times were ACTUALLY <5ms latency for queries with just a few items and 50ms latency for queries returning ±300 items in a table with millions of rows.
We were a bit concerned on the lack of flexibility that SQL engines do give, but to our surprise this wasn't a big deal! For a few use-cases where aggregation was required, we implemented the aggregation client-side or implemented other workarounds by keeping aggregate state inside the items themselves or in a separate table instead. The access patterns were a lot more stable than we initially thought!
Furthermore, we found that the access patterns for our GSI weren't used, so we dropped it to decrease cost.
All in all it took some getting used to to create the right queries, but given the absolutely astonishing performance, scalability and low cost, together with the nearly non-existent maintenance it required, this was a trade-off we were happy to make.
Further reading
- AWS Docs on many-to-many relationships: https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-adjacency-graphs.html
- Workshop: https://amazon-dynamodb-labs.com/design-patterns/ex7adjlists.html
- Another example of the adjacency list pattern: https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-modeling-nosql-B.html
Subscribe to my newsletter
Read articles from Luuk directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Luuk
Luuk
Building stuff on AWS! Professional AWS cloud consultant/engineer focussing on innovation for enterprise, SME, and start-ups. 6x AWS certified.