K-Nearest Neighbors algorithm(KNN)
 Robin kumar
Robin kumar
Hey again! we’ll start learning about Machine Learning algorithms. And in this blog, we will be talking about one of the commonly used classification algorithms, KNN algorithm.
K-Nearest Neighbors is one of the easiest to understand, yet very important to know, classification algorithms in Machine Learning. It’s even called the laziest algorithm, and you’ll know why it is called so, by reading this article.
Let’s get started;
Given some training vectors, KNN algorithm is able to identify the K nearest neighbors of the element we want to class, regardless of labels.
Hold on, I know that definition is absolutely very boring and won’t help you understand KNN. Actually, it was just stuck in my head, after reading it somewhere on the internet and I had to add it to my blog. Sorry for that😅. Just keep reading, I’ll make things easier and fun for you to get. That’s my mission 😊. So, let’s take our first example:
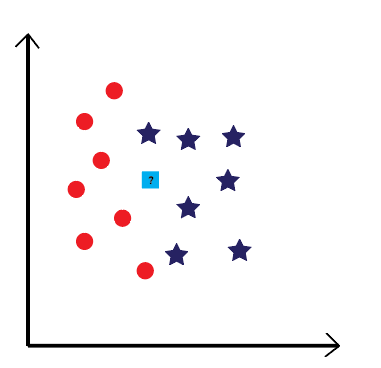
The illustration above shows a number of training vectors that are grouped into two classes: orange circles and blue stars. But there’s also a light-blue square, with a question mark on it, what’s that for? The square is the element we want to class, using the KNN algorithm.
Without further ado, let’s help our lonely square to join one of the two classes, following some easy steps:
— The first thing we have to do, is to choose the “K” number. In this case, let’s work for example with K=5.
— The second thing to do, is to select the K nearest neighbors to our square. In other words, select the 5 elements that are the nearest to the square, regardless of their class (they may be stars or circles, it doesn’t really matter for now).
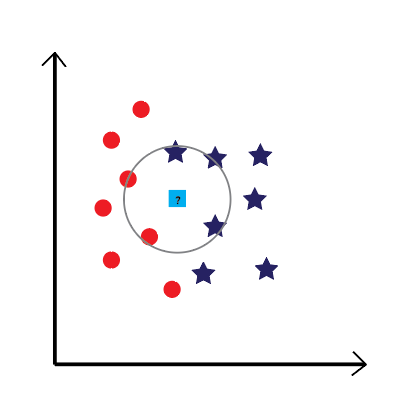
Now, let’s count the number of the nearest neighbors from each class. As you can see in the above illustration, there are 3 blue stars selected VS 2 orange circles. Which, obviously, makes the stars win. Poor orange circles 😢.
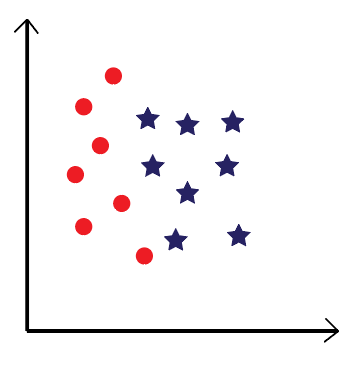
— Finally, our square will be joining the blue stars class. Let’s congratulate him for, finally, having a family.
You know what, let’s give our orange circles another chance, maybe this time they will get to win a new member, too. For that, let’s make ou K=3, and see what’s going to happen.
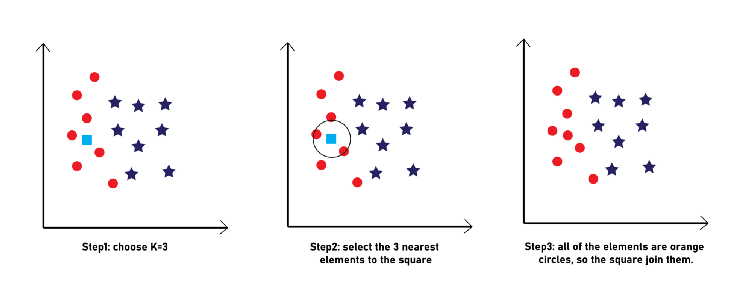 Now, that you got to understand the KNN algorithm through an easy example, let’s make things a bit harder (don’t worry, it won’t be so difficult to get), by working on some real data (not just circles, squares and other shapes).
Now, that you got to understand the KNN algorithm through an easy example, let’s make things a bit harder (don’t worry, it won’t be so difficult to get), by working on some real data (not just circles, squares and other shapes).
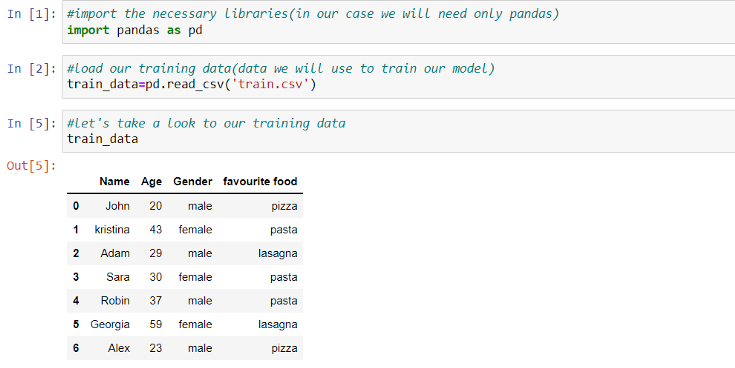
Let’s take this small data, as an example:
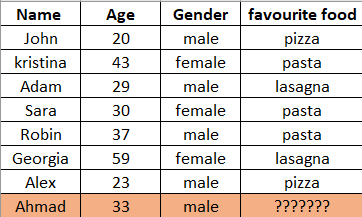
The above data shows the age, the gender and the favorite food for 8 different people. What we’re asked to do, is to predict the favorite food for one other person “Ahmad”, using KNN algorithm.
Let’s do that.
First of all, let’s determine our “K”. let it be 3. After that, we have to determine the 3 nearest neighbors to “Ahmad”. To do so, we have to calculate the Euclidian distance between Ahmad and all the other people in our data(our data points).
For those who don’t know, the Euclidian distance between two points A(x1,y1) and B(x2, y2) is:
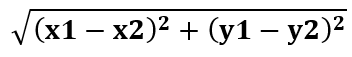 In our case the A is, in each time, one of our data points(John, Kristina,…) and the B is “Ahmad”. The x and y are the age and the gender.
In our case the A is, in each time, one of our data points(John, Kristina,…) and the B is “Ahmad”. The x and y are the age and the gender.
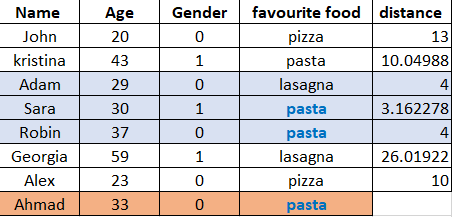
After calculating all the distances between each person and “Ahmad”, we can see that Adam, Sara, Robin are the 3 nearest neighbors to him, and both Sara and Robin likes “pasta”, so Ahmad’s favorite food would be, also “pasta”.
This seems very easy, but also so exhausting! Imagine having a data with +100 rows, it will be so painful to calculate, manually, all the 100 distances and then select the 3 nearest ones. Fortunately, Python makes it easy, for us. Let’s try and implement the previous example in python.
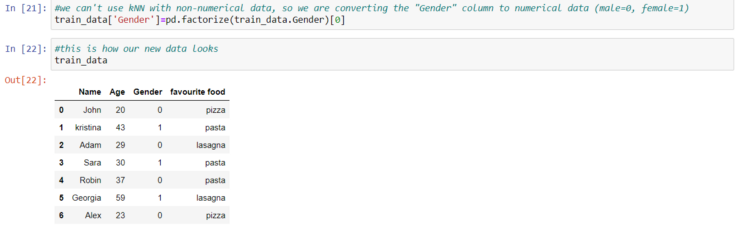
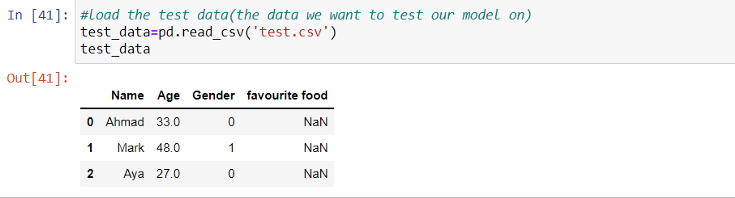
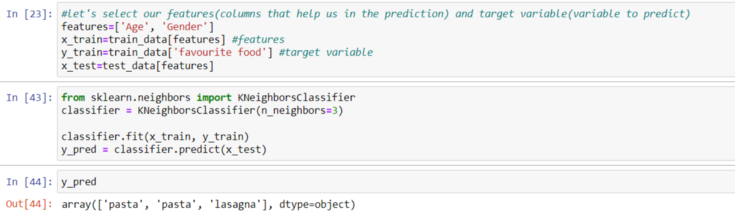
As you can see, Python makes things much easier. The result we get is the same that we got when we’ve calculated the distance manually. And that’s a good sign, that our model works correctly.
Finally, we’re done. Easy? Right? See now why do we call KNN a lazy algorithm? Because there’s nothing easier than this. Just make sure you select your features properly and carefully.
See you in the next blogs, where we will keep learning about ML algorithms in a fun way.
Subscribe to my newsletter
Read articles from Robin kumar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Robin kumar
Robin kumar
I am a Post grad in Bioinformatics . My field of interest and expertise lies mainly in Data Analytics, Machine Learning & Bioinformatics.