Building an ML pipeline with DVC in Five Easy Steps
 Oluwaseyi Ogunnowo
Oluwaseyi Ogunnowo
Machine Learning models are built through an iterative process, whereby feedback from a previous run is considered in the next run. This flow is repeated until the most optimal results are achieved. Oftentimes, these repetitions involve experimenting with different ideas, changing parameters, datasets, etc, just to get the desired outcome. You might as well agree that it takes time, effort, and a lot of grit.
While this isn’t debated, many startups and establishments are not willing to wait long to have an “accurate” model. They see each passing day without model inference as money lost. So the pressure is on the ML Engineers and data scientists to speed up experimentation processes, and get predictive systems up and running.
This might be your situation, and you are probably asking yourself, “how do I make my ML experiments seamless and more efficient?”
Pipelines!!!

Pipelines are like restaurant cooks, who take raw meat, oil, and other ingredients, turning them into hot, sizzling steak. They (the cooks) are aware of all the stages of getting the end product. So if you love to have some steak, all you have to do is simply visit a restaurant and make your order.
Similarly, a pipeline takes in data (raw or processed) and returns a model as the final product by passing that data into a series of stages in a sequential manner.
We would go into the technicalities of these, as we go along in this tutorial.
Prerequisites
As discussed, the knowledge of pipelines is crucial to ML model developments, though this is not intended for a beginner audience, knowledge of the following would help you follow along with this tutorial.
- Python: A high-level and general-purpose programming language, widely used in data science and machine learning.
- Git: is a distributed version control system that can be used in software development projects. It supports free and open source projects, allows developers to work collaboratively, and helps keep track of changes to the code base and associated files. You can learn more about git here
- Argparse: is a Python library that allows you to pass arguments into commands that you input in the Command Line Interface (CLI). You can know more about argparse by reading this medium post
- Command Line Interface (CLI): a program that processes commands to a computer in the form of text. Different Operating systems have their CLIs named differently. For macOS, it is called Terminal while for windows it is termed Command Prompt. You can read more about it here
- The Machine Learning workflow: is a series of activities that when conducted, produce a Machine Learning model. Workflows are heavily dependent on the problem to be solved and as such, can take slightly varying forms.
This list is not exhaustive. As such, I’ll try to simplify the terms I use as much as possible as we go ahead.
Let’s get to it!
What Does an ML Pipeline Mean?
An ML pipeline is an object that helps automate the Machine Learning workflow. It is software that produces a model from a sequence of steps that among other things involve cleaning, preprocessing, and transforming data.
Pipelines are made up of stages, with each stage representing one step in the ML workflow. Typical steps in a pipeline involve data ingestion, preparation (cleaning, feature extraction, etc), model training (training of an algorithm to learn patterns from the data), model evaluation (testing how well the model can generalize with the patterns it has learned) and lastly, deployment (making the model available for predictions post-development), we will see this more in a bit.
Considering how easy it is to build models with a pipeline, it is recommended that you have it as a tool in your arsenal. With it, you can build and rebuild models in less time, compared to running modules (.py files) manually through the CLI, or worse still, re-running cells of code in your jupyter notebook.
ML Pipeline ≠ ML Workflow
Even though you might be led to believe these terms can be used interchangeably, they are not the same.
As mentioned previously, a Machine Learning pipeline is software that helps produce a model, by running a sequence of steps that mirror the steps in the Machine Learning workflow. The Machine Learning workflow simply talks about the stages that are implemented to produce a model, without automation.
Components of a Machine Learning Pipeline
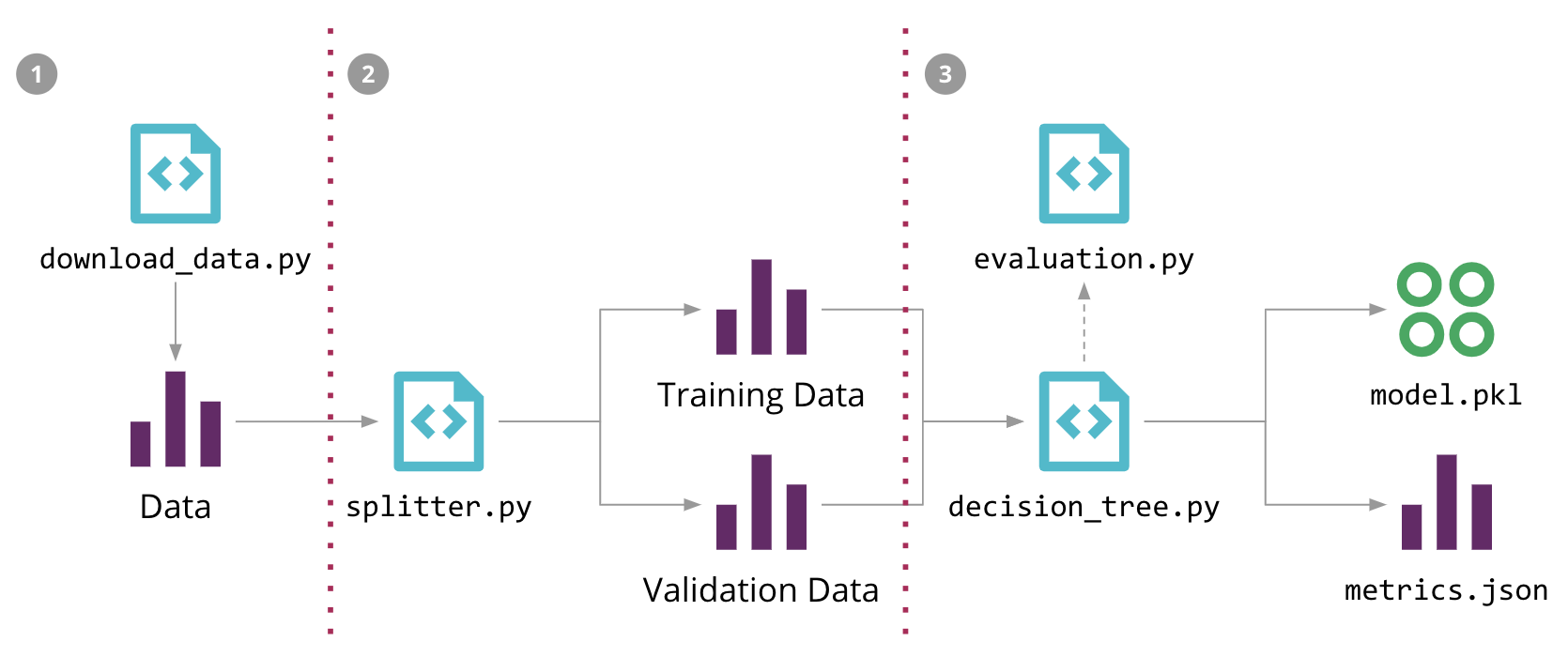
I will be using this image to explain how pipelines are typically built. However, this is just an example, and should not be taken as a standard template.
This image shows a pipeline with three stages namely data collection, data splitting, and training. Data collection operates with a script download_data.py that collects data from storage either on your local or in the cloud. This stage feeds into the splitting stage, with a splitter.py file that splits the data into train and validation sets.
The train set will be used in stage three to train a decision tree with the help of the decision_tree.py while the validation set will be used to test the tree’s accuracy with the help of the evaluation.py script. The final output of this pipeline is a pickled (serialized or saved) model object model.pkl and then metrics stored in a JSON file metrics.json
With this illustration, you understand what a pipeline is, how it works and what it does. But in reality, pipelines aren’t necessarily organized this way.
The typical stages in any ML pipeline include
- Data Ingestion: This stage involves collecting data from a source. More like what the
download.pyfile does in the image above. - Data Cleaning: Data in its raw form is not without some problems. These problems take the form of null values, outliers, duplicated rows, bad values, and so on. Such situations are a direct result of wrong data imputation among other things. The data cleaning stage will help rectify some of these problems. A
cleaning.pymodule containing all your codes will do the trick - Data Exploration: Exploration is part of the model development process. It helps identify the inherent patterns in the data and to some extent, helps validate some hypotheses. For this reason, it is part of the ML pipeline. This stage creates plots, charts, and graphs with the sole aim of summarizing the data. A typical name for code files for this stage is
data_exploration.py - Model Training:One of the core aspects of the Machine Learning workflow is model training, and this is the same for ML Pipelines. This involves selecting a suitable algorithm and fitting it to a section of the cleaned data called the training set. From the image above, the
decision_tree.pyfile trains a tree-based. In your case, you can call the moduletraining.py - Model Validation: At this stage in the pipeline, the model’s ability to generalize after training is tested on unseen data (the validation set). This process has to be measured and so it is custom to use certain evaluation metrics. Depending on the results of these measurements, the model is either retrained or deployed into production. Usually, the module that helps achieve this is named
validation.py - Deployment: Acknowledged by some as the last stage, this step in the pipeline involves pushing the model into a production environment where it will be used to make predictions in real-time or in batches.
While the typical ML pipeline will have these stages, it can be extended to include model monitoring and retraining steps, which are quite essential in the ML workflow. Additional stages that can be included in the pipeline are feature extraction, and feature transformation among others.
It is also important to note that the modules you use in your pipeline can be named differently than the conventions used in this piece.
What is Data Version Control?
Data Version Control or DVC is a tool that conveys its essence by its name. And so, you might view it as a tool or framework that helps version data, and you won’t be wrong, but this isn’t a full picture of what it is.
DVC is a free and open-source tool for Machine Learning projects that makes models, associated data and artifacts shareable and reproducible.
DVC and Pipelines?

As mentioned previously, DVC helps to manage the ML workflow involved in building models. It does this through a mechanism that helps capture and store your modules as stages (more on this in the next section).
This means that as you run your modules with DVC, it (DVC) stores these as stages in a pipeline.
DVC is built to operate in three major spheres:
- Versioning: Among its main functionalities, DVC helps to version model, data, and implementation code, regardless of size. While it does not actually store versioned artifacts, DVC creates metafiles that point to the original files. The Originals on the other hand can be stored in external storage systems like Amazon s3, etc. With this configuration, it’s safe to say that DVC offers a lightweight version control process.
- Workflow management: Another aspect of its functionality is workflow management. Data Version Control facilitates the creation of pipelines that comprise different stages.
- Experiment Management: DVC is built to consider the importance of Machine Learning experimentation. It allows you to display, track and compare metrics across different experiments. You can also exploit its plotting capabilities to visualize the metrics of different experiments.
How do I build a pipeline with DVC?
You can build an ML pipeline by:
Making your code modular: The first step in building any pipeline is to organize your code according to a specified workflow. By doing so, each script/ code in your pipeline carries out one functionality in the pipeline. In a Machine Learning context, this means you must organize your code in line with the ML workflow explained in previous sections.
Ensuring your code is clean and reusable: Ensuring that you have not only organized your code according to the Machine Learning process, but also ensured that it is clean, organized in individual scripts and written in a way to create room for reusability.
Your code needs to be clean becausePipelines are shareable objects, most especially with DVC. This means that you might work with other data scientists and ML engineers. Clean code makes it easy for your colleagues to easily understand code.
You might need to visit the scripts in the future. Rough and untidy code, will make comprehension of what you did previously difficult.
Your code is easily reusable when you organize code into functions and avoid hard-coding parameters and feature names. Argparse to allows you to pass in arguments through CLI commands. This makes the module flexible and reusable. You can use argparse this way:
""" Script to train a Stochastic Gradient Classifier algorithm """ import argparse # initializing argparse library parser = argparse.ArgumentParser(description = "Script to visualize data properties.\ NB: data passed must be saved in .csv format") # creating arguments parser.add_argument("--data_path", type = str, help = 'path to training sample') parser.add_argument("--independent_feature", type = str, help = 'column in dataframe containing texts') parser.add_argument("--dependent_feature", type = str, help = 'column containing encoded target values,\ i.e. the values you want to predict') parser.add_argument("--test_size", type = float, help = "size of test set") args = parser.parse_args() # initializing vectorizer and classifier sgd_clf = SGDClassifier(loss = 'hinge', random_state = 42) tfidf = TfidfVectorizer(sublinear_tf=True, min_df=2, norm='l2', encoding='latin-1', ngram_range=(1, 2), stop_words=stop_words, lowercase = False) # reading data df = pd.read_csv(args.data_path) x = df[args.independent_feature] y = df[args.dependent_feature] # splitting data into train and test set x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = args.test_size, stratify = y) # vectorizing texts x_train_trans = tfidf.fit_transform(x_train) # training classifier sgd_clf.fit(x_train_trans, y_train) constants.logger.info("exporting model pipeline") export_object(sdg_clf, 'model/classifier.pkl')Notice how I did not directly pass in any parameters or hard code feature names? I instead used the
argsobject I instantiated to input arguments through the CLI command. Here's howpython train.py --data_path "data_artifacts/cleaned_data.csv" --independent_feature "column_name" --dependent_feature "column_name" --test_size 0.2Setting Up Folders to store data artifacts, plots, and models: For each stage of the pipeline, there will be inputs and outputs. The output of a stage serves as input to the next stage. This is how the stages link to form a pipeline. For example, data cleaned by the
cleaning.pyscript is fed into thetrain.pyscript.# exporting cleaned data as csv file df.to_csv("data_artifacts/cleaned_data.csv", index = False)This line of code is in a
cleaning.pymodule, and exports thecleaned_data.csvfile into a folderdata_artifacts. The cleaned data is fed into a training module train.py and used to build a model through this command.# command to run training script with input as cleaned data python train.py --data_path "data_artifacts/cleaned_data.csv" --independent_feature "cleaned_short_message" --dependent_feature "interest_id" --test_size 0.2It is important to note that folders do not necessarily have to be on your local machine. You can have the folders in cloud storage services like S3, Google Drive, etc.
Initializing git and DVC in your working directory: Another requirement for using DVC to build ML pipelines is initializing git with the
git initcommand. This is a one-time command you run at the initial stages of the project when you want to create a new git repo. It should only be done if a git repo has not been initialized in that working directory.It is advisable that you initialize git since some functionalities require DVC to run in a git repo. After this, you can initialize DVC with
dvc init. This allows you to use the tool’s functionalities to track data, change to code, and even build pipelines. For more details on this, you can refer to this documentation.Construct the Pipeline with your scripts with DVC commands: Constructing the pipeline is as easy as running your scripts with the necessary DVC command. Each module that you have created will be run with this command:
dvc run -n <name> -d <dependency> -o <output> <command>This command starts with
dvc runto allow DVC keep track of the run, and includes Options (-n, -d, -o) to pass in dependencies and outputs.- Name (-n, --name): Name of the stage you are trying to create. It could be cleaning, training, validation etc. A stage can only have a single name.
- Dependency (-d, --deps): An file or directory that the stage depends on or consumes as an input. You can have more than one dependency.
- Output (-o, --outs): A directory where the result of the stage will be stored. Can be on your local or even on the cloud. This stage heavily depends on the folders you set up in step 3. You can also have more than one output
- Command: The command to run the script as a stage.
By running this command, DVC not only runs your script, but takes note of the dependencies (artifacts required to run the script) and output (the results generated by the script). This information is stored in a dvc.yaml file which shows you the stages of the pipeline. As you repeat similar commands for the different modules in your workflow they get stored in the yaml file.
A typical dvc.yaml file with the different stages looks like this:

Here you see the names of each stage, their corresponding dependencies, outputs and commands that invoke them.
As mentioned earlier, this file is a by-product of running the modules in your workflow. In line with the example command I placed above, let's see how to run a training script with DVC. To run the training script (which trains a Stochastic Gradient Classifier algorithm) shown previously, I simply have to type this command
dvc run-n train -d train.py -d cleaned_data.csv -o model/classifier.pkl python train.py --data_path "data_artifacts/cleaned_data.csv" --independent_feature "column_name" --dependent_feature "column_name" --test_size 0.2
In Conclusion: how does a DVC pipeline aid reproducibility?
MLEs and Data Scientists usually experiment with different ideas to get the right model. So reproducing models and results is not out of place. DVC caters to this by making the pipelines rerunnable. To do this, simply input the command dvc rerpo in the CLI. This command reruns the pipeline to produce the same model and when arguments and parameters in the scripts are changed, it will give a different model.
Should in case you need to rerun a single stage in the pipeline, you use this command dvc repro -s <stage name>. DVC has a way of keeping track of changes made to stages. As such if there are no changes to the stage you want to run, it will know by skipping that stage. See an example.
dvc repro -s test
You get this output or something similar:

This is DVC telling me that there were no changes to the test stage and so it will skip that run.
For the code base that was used for illustrations in this article, you can find it here. You can also contact me via mail: seyiogunnowo@gmail.com for questions and discussions on this or any other aspect of Machine Learning.
Subscribe to my newsletter
Read articles from Oluwaseyi Ogunnowo directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Oluwaseyi Ogunnowo
Oluwaseyi Ogunnowo
I enjoy working on and building complex classification systems, writing how-to pieces to guide new bees in the data science field. In my free time I enjoy learning how to use new technologies and spending time with family