Feature Scaling In Machine Learning
 Yuvraj Singh
Yuvraj Singh
If you are one who is struggling to get the basic understanding of feature scaling in machine learning, then let me tell you that you are at the correct place, because after reading this blog post you will be greatly equipped with the knowledge related to feature scaling and will understand why and when we do feature scaling in machine learning , so without further due let's jump straight into the content .
Basic introduction about feature engineering
Before knowing feature scaling , you must also be aware about to which branch of machine learning does feature scaling is attached to , so basically if you would take a look at the overall life cycle of machine learning model then you would realize that before building any machine learning model first we need to do the processing of the raw data , so that it becomes easy for our machine learning algorithm to learn .
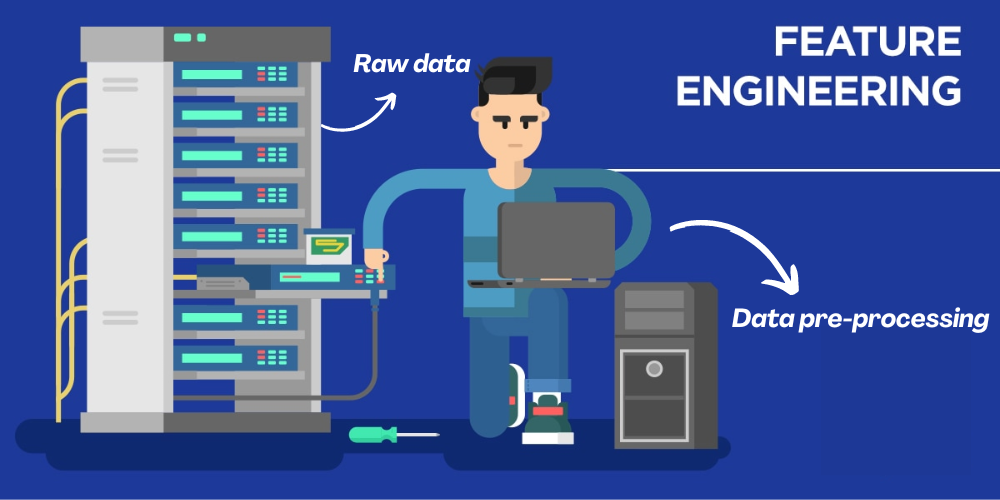
During the data preprocessing , as per need sometime we need to do feature engineering which is just a data - processing technique used in machine learning in which we use our domain knowledge to select , manipulate or transform the raw data to make some useful features , which would increase which could increase the accuracy of machine learning , because with good features machine learning algorithms would learn efficiently .
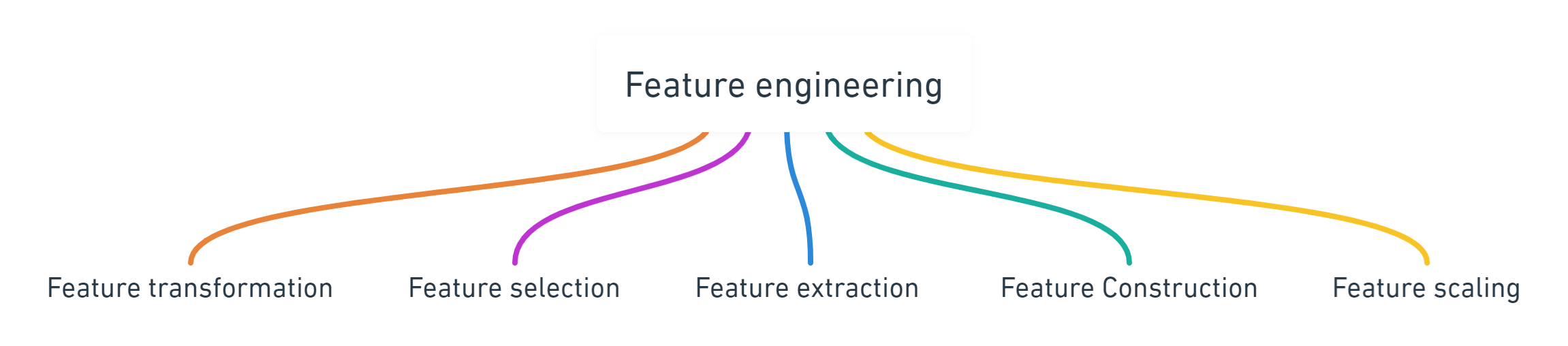
In feature engineering itself there are roughly 5 steps which we can perform to make useful features , but the thing to consider is that it is not compulory to all the steps on our dataset , instead decide that whether this step is important or not . Down below is a mindmap which will help you to remember different steps of feature engineering .
In this blog post our main focus will be on feature scaling and some questions related to it , some of which are ⬇️
- What is feature scaling ?
- Why we need it ?
- Techniques for doing feature scaling ?
What is feature scaling and why we need it ?
 Now let's us deeply understand this definition using an example
Let us assume that we want to make a machine learning model which will help us to predict the salary of the individual based on the years of experience in some tech company . For training our model let us assume that we are using the (KNN ) k-Nearest Neighbor algorithm in which we have to find the euclidian distance between the data points .
Now let's us deeply understand this definition using an example
Let us assume that we want to make a machine learning model which will help us to predict the salary of the individual based on the years of experience in some tech company . For training our model let us assume that we are using the (KNN ) k-Nearest Neighbor algorithm in which we have to find the euclidian distance between the data points .
 Here just for simplicity, I am considering 2 dimensions, there can be more than 2 dimensions also ( like 3 , 4 ) . Since only variables ( x1, y1, and x2 , y2 )are present on graph so let us assign some values to these variables
Here just for simplicity, I am considering 2 dimensions, there can be more than 2 dimensions also ( like 3 , 4 ) . Since only variables ( x1, y1, and x2 , y2 )are present on graph so let us assign some values to these variables
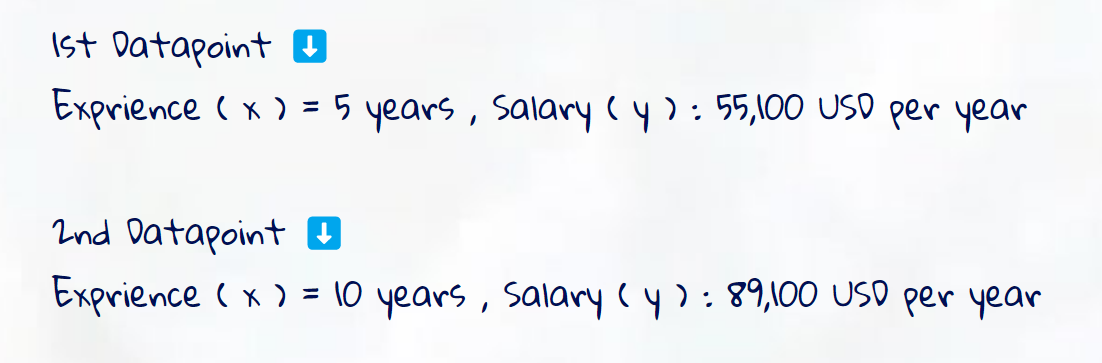 By using the formula for finding the euclidian distance between these 2 data points we will get ( x2 - x1 ) ^ 2 = 25 , whereas the ( y2 - y1 ) ^ 2 = 1,156,000,000
By using the formula for finding the euclidian distance between these 2 data points we will get ( x2 - x1 ) ^ 2 = 25 , whereas the ( y2 - y1 ) ^ 2 = 1,156,000,000
Here as you can easily see that when we will add both the values and take a root of the result the salary feature will overpower the experience feature, thus our KNN algorithm will not give us accurate results, thus we need to scale these value to common scale so that it becomes easy for our machine learning algorithm to learn and give better results .
Techniques to do Feature scaling
In order to do feature scaling we have 2 different techniques , and both of these techniques are quite different from each other so we must first understand our data fully to figure out which technqiue to apply for feature scaling ,
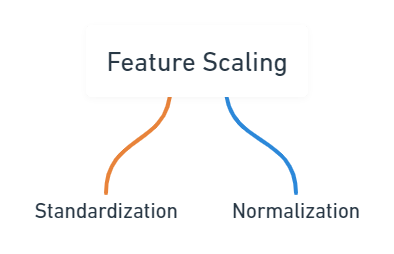
What is standardization and how it works ?
Most of the time as per my experience we use the standardization technique for doing feature scaling , so must be totally clear with how this technique works . First of all take a look at the definition of the standardization in machine learning
 Now after you are aware of the general definition about standardization , let us now see the mathematics behind the standardization
Now after you are aware of the general definition about standardization , let us now see the mathematics behind the standardization
Mathematics behind the standardizaiton
When we apply standardization on the feature present in our dataset , then no magic happens which make the mean and standard deviation of that feature as 0 and 1 , instead there is a mathematical formula behind this transformation .
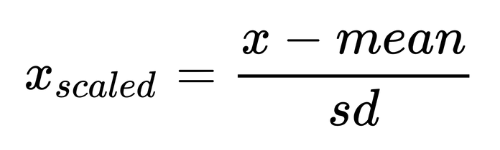 In this formula for simple understanding mean (μ) and standard deviation (σ) are written in the text form instead of the mathematical symbol .
In this formula for simple understanding mean (μ) and standard deviation (σ) are written in the text form instead of the mathematical symbol .
Practical Implementation of standardization technique
Now after taking a look at the mathematical formula behind the standardization in machine learning, now it's time to make your hands dirty with the actual implementation of standardization in machine learning using the python code. The dataset and the python code used for this blog you can access the whole of the content from ➡️ here ⬅️, but right now in this blog post I will show you the effect of doing feature scaling ( Standardization ) on the accuracy of machine learnig algorithm like Logistic Regression
Before And After results
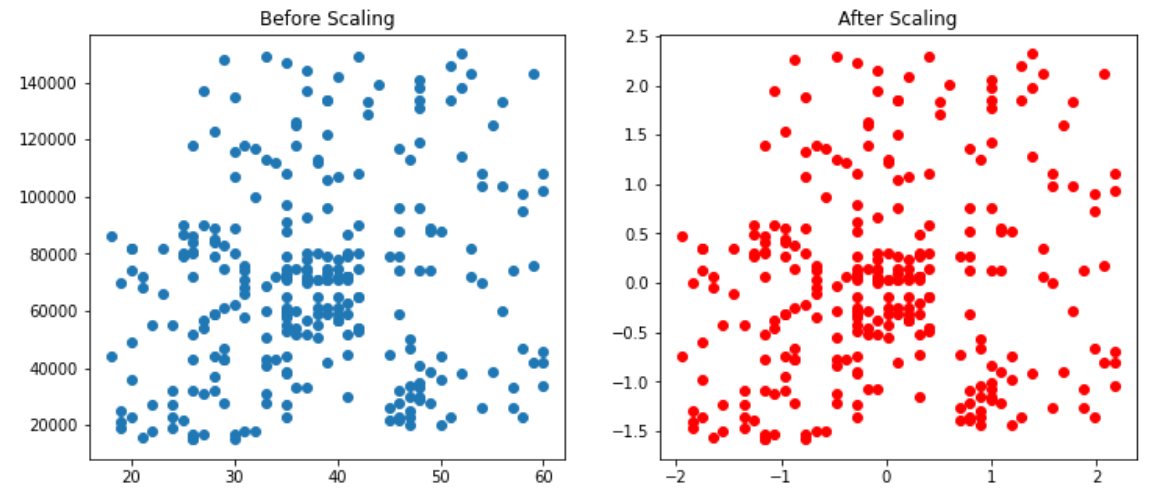 At the first glance it seems that nothing happened as all the plotted values are looking same in both the scenarios , but if you would look carefully at the x and y axis values of both the graphs then you would see the actual effect of standardization , as after standardization there is no change in the distance between the data points but the concentration of data points have changed as you can see the concentration of data points after standardization have shifted towards origin ( see the x axis ) .
At the first glance it seems that nothing happened as all the plotted values are looking same in both the scenarios , but if you would look carefully at the x and y axis values of both the graphs then you would see the actual effect of standardization , as after standardization there is no change in the distance between the data points but the concentration of data points have changed as you can see the concentration of data points after standardization have shifted towards origin ( see the x axis ) .
 Here as you can clearly see that mean and standard deviation of both Age and Estimated Salary has became 0 and 1 after standardization . Not only this there is also a significant difference in the overall accuracy of the machine learning model trained using Logistic Regression algorithm ⬇️
Here as you can clearly see that mean and standard deviation of both Age and Estimated Salary has became 0 and 1 after standardization . Not only this there is also a significant difference in the overall accuracy of the machine learning model trained using Logistic Regression algorithm ⬇️
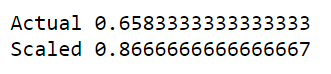
What is normalization and how it works ?
Normalization is a technique used for doing feature scaling , and when we apply normalization on feature present in our dataset , the values present in that feature get transformed within the range from 0 to 1 .
In case of normalization itself there are different techniques of doing normalization , some of which are shown in the figure below
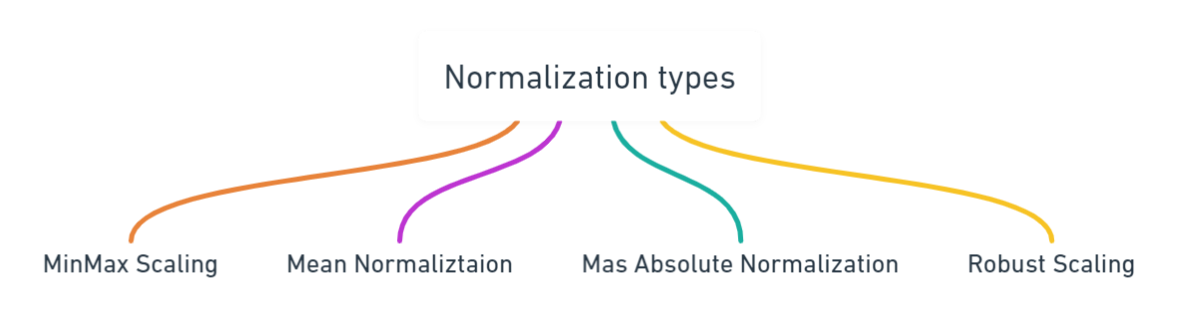 Out of these mentioned normalization techniques, MinMax Scaling is the most popular one and most effectively in 95% scenarios, thus in the next section regarding mathematics behind normalization we will actually discuss the mathematics behind the MinMax scaling
Out of these mentioned normalization techniques, MinMax Scaling is the most popular one and most effectively in 95% scenarios, thus in the next section regarding mathematics behind normalization we will actually discuss the mathematics behind the MinMax scaling
Mathematics behind normalization
Just like there was a mathematical formula behind the standardization technique for feature scaling, in normalization also there is a mathematical formula that helps us to transform the feature values so that they lie within the range from 0 to 1
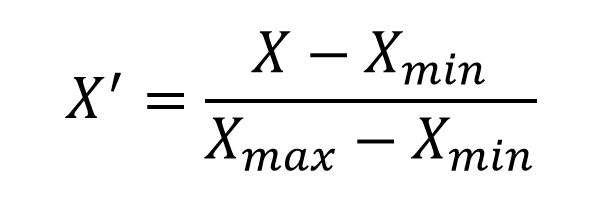 While doing normalization using MinMax scaling technique our main aim is to find the minimum value and maximum value out of all feature values and then use them in the formula .
While doing normalization using MinMax scaling technique our main aim is to find the minimum value and maximum value out of all feature values and then use them in the formula .
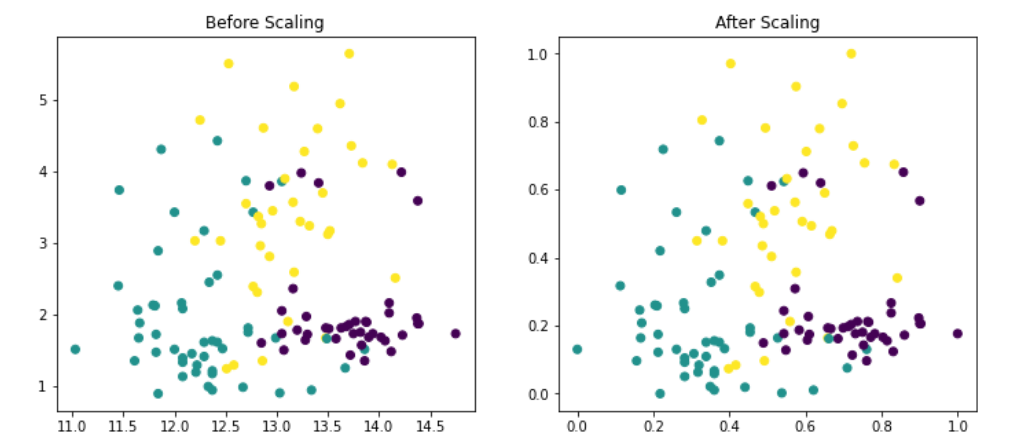
Practical Implementation of Normalization
Since till now you are aware about normalization , different techniques to do normalization and the mathematical formula behind the MinMax scaling technique so now let's us write some python code to see how it works in real world scenario . Just like standardization , the dataset and python code regarding noramlization in machine learning are present in my git-hub repository , which you can access from ➡️ here ⬅️
Subscribe to my newsletter
Read articles from Yuvraj Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Yuvraj Singh
Yuvraj Singh
With hands-on experience from my internships at Samsung R&D and Wictronix, where I worked on innovative algorithms and AI solutions, as well as my role as a Microsoft Learn Student Ambassador teaching over 250 students globally, I bring a wealth of practical knowledge to my Hashnode blog. As a three-time award-winning blogger with over 2400 unique readers, my content spans data science, machine learning, and AI, offering detailed tutorials, practical insights, and the latest research. My goal is to share valuable knowledge, drive innovation, and enhance the understanding of complex technical concepts within the data science community.