It's All About the IOPS Baby
 Jeremy Hall 🖥️ ⌨️🖱️
Jeremy Hall 🖥️ ⌨️🖱️
Disclaimer: This article is going to have a focus on platter based spinning disk drives. When speaking about flash, it will be called out specifically. Thanks, on with the show.H
Input Output Operations per Second, aka IOPS, is exactly that. When you hear someone say that their application tops out at 1,400 IOPS that means the code they have written and limits they setup (in most cases, did NOT set up) allow the program to generate and process 1,400 input or output operations each second. Examples of an input operation would be saving user data into a SQL table. On the output side, a good example is any operation that generates data and presents it in its raw form, or in a graph. These are extremely simplistic examples, and this is to make sure we are on the same page with each other before moving into complex territory. IOPS tends to be measured by different metrics so making sure we talk about those is very important. Ready to learn about storage? Let’s go.
What’s In a Drive?
For those who may not know how tracks and sectors are split up, or even how they work, here is a breakdown with an infographic (Figure A). Think of a hard disk as a pizza before it is cut. On that pizza, you want to have one slice. A slice of pizza is called a sector. Now, for a track, think about a vinyl record and the music is in a long, long line that slowly but surely wraps around the circumference of the record, and works its way to the center of the record, and then when it reaches the end, the needle is lifted up and put away. A track of data is the same concept - however it does not wrap around and around like a flattened out spring. A hard drive track is one full rotation or circumference of the platter. Figure A shows a visual of this track/sector relationship.
Then you have single blocks. A block is the unit of measure for a literal block of data. Think of a block as a rectangle that is either many smaller rectangles and when put together they equal a photo saved on your drive. Blocks are the logical collection(s) of binary data and typically each block is fixed at 512 bytes in size. This is configurable in most partitioning and drive formatting tools, but 512 bytes is the most used size by far. Before hard drives were multiple terabytes in size, tracks and sectors were pretty much always lined up the same way - cut like a pizza for the sectors and the tracks went the entire circumference of the platter.
These days, there are algorithms used to break up the tracks and sectors to optimize the total number of tracks and sectors a platter can actually hold while improving performance and reliability. The sectors are no longer all lined up nice like a cut pizza but are instead offset from each other to increase performance and the total number of sectors available to write in. If you are interested in learning more low level details about hard drives, check out this link. It will take you down the rabbit hole.
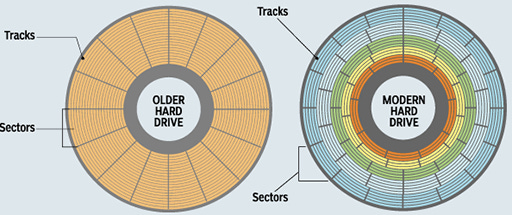
Figure A - Old HDD Platter Sectors Vs. Modern Day Sectors
First we need to break down some of the metrics you would need to know about in order to talk to someone intelligently about this topic. Starting with sequential IOPS values, you can measure sequential read or write. In terms of sequential disk operations, these are the best benchmarks for large, continuous files becuase it allows the on-board cache of the drive you are reading or writing with to fill up and this cache is far quicker than direct disk operations. The other reason sequential operations are so much quicker for reading and writing is the head of the disk can write to a single, continuous track and does not need to keep moving to a new track and back to another track, over and over again, many times per second. When a drive must write or read many small files (~1B-1MB) these files are written all over the platter in different tracks, and different sectors. Due to this random access, we call it random read or write. When you research a drive to put into your own computer, you will see on the small print that the speed of the disk reported on the box or website, is typically always in sequential read and write speeds becuase, these long reads and writes always will be faster than writing a lot of small files. Faster means more better to the consumer who is not aware most operations are random, not sequential. Great marketing move.
How does a hard disk read and write to a metal, magnetized platter anyway? Why are vibrations bad for spinning hard disks? Glad you asked. If you were alive for the early hard drives (talking few hundred megabytes or less!) then you are familiar with how these disks spun up and were very loud when the head was reading or writing to the platter - they make almost a clicking sound but extremely quickly so they are no spaces between the sounds and it ends up sounding like brrrrrrratatatatatatatatat! That noise is actually the magnet sending pulses of electricity into the read/write stacked assembly’s voice coil which is how the drive can precisely target specific tracks, sectors and blocks so quickly. That noise also is the head assembly rapidly moving and changing direction. These days, disks are super quiet and you have to use a stethoscope or place your ear on the cover just to hear them. The magnetic head moving back and forth across the platters (both sides of each platter are used) read the track, sectors, and blocked data to put into system memory. Then the CPU reads the data right out of memory and the returned modified data is once again put into memory and then the drive would receive an instruction by the OS to write the data back to the disk, or to not do anything.
The magnetic head at the end of each arm is actually floating 2nm above the platter’s surface! That is thinner than a fingerprint to put that into perspective. This is why hard disks must spin at 5,400-15,000 RPM so they can create a pillow of air for the head to ride, and the head has been designed to use that pillow of air and flow the remainder of the air it does not need away from the head and out to the drive edge. Hard disks are assembled in clean rooms where there is zero particulate in the air, as even a single flake of dust can cause damage - it could hit the head and make the head drag across the platter or worse yet, get trapped under the magnetic head and cause block/sector/track errors. This pillow of air which is tiny, is also why vibrations are enemy number one for these devices. When you spin a disk this size at 15,000 RPM and then jump on the floor next to it, that pillow is not enough to keep the head from hitting the platters momentarily and you can create read/write errors or leave lasting, bad blocks or sectors. If you jump next to a SAN, you will see a flurry of drive status lights - not becuase someone is using the device, oh no no. You just caused errors on the spinning disks and they have to perform error correction and error checking. Also any reads or writes that were in progress could have been ruined and unrecoverable. It is also possible that you jumped hard enough and the head has come into contact with the platter(s) and a few hundred MB of blocks are dead. Good job.
The other issue you can avoid which can save your drive even further, is to not hold the power button to force your PC off. It is okay in emergencies when you cannot shutdown properly, but yoinking the power cable will remove all the power from the system and spinning disk drives. Luckily, hard drive manufactures understand that things happen, and have a solution that works quite well.
Remember that pillow of air that the heads use to travel just above the platter’s surface? When power is pulled and the disk begins spooling down, the head uses the last bit of moving air to slowly move the head back to the parked position, and it does not leave a massive gash in your platter. If you want to learn more about how a hard disk works, check out this youtube classic. It talks about all of the topics here and more, but at a much lower level.

Photo of Hard Disk Platter with the Read/Write Head Active.
Defrag This, TRIM That
One final topic about hard disk platters and how data is stored: defragmentation. Remember in Windows 98 where you would get the reminder that your disk was heavily fragmented, and to setup a scheduled job to defrag the disk or run it now? What Windows was complaining about was that all the data which used to be in a single track had been split up and now was in multiple tracks and sectors, all over the drive. This fragmentation is like a messy room. You cannot find things when the shelf you put your legos on is on the floor and covered up by clothes. You need to put all the legos and clothes back to their respective spots so that way finding those items is faster and simpler. Also, by performing a defrag, those long tracks become open and ready to write data into them and those writes and reads will perform better than trying to read the individual bytes all over the platter in different tracks, sectors, and blocks.
How come we no longer see the request or reminder to defragment even though hard drives are 10-100x the size there were in the Windows 98 era? The answer to that is quite simple - TRIM and SSDs. Solid state disks are not made to be defragmented at all - in fact, if you defragment SSDs you reduce the life of that disk becuase you are reading and writing data over and over again just to line up the data. However, becuase a solid state disk has no moving heads or spinning platters, you do not see that much loss of performance over time. Instead of using degramentation tooling to line all your data back up, solid state drives use an operation called TRIM. When TRIM is called, the operating system tells the controller on the SSD which blocks of data are no longer considered to be 'in use' and therefore can be erased. This opens up areas that the next write operation can use. This happens all the time as you modify files on your computer, and is done in the background with almost all users unaware of what it is, and why it is important. By using TRIM you extend the life of the memory chips on the device and open long segments of blocks that can be used the next time a write operation is performed.
Back on Track
This began about IOPS, not about how hard disks and SSDs work, but you have to know at least the basics to understand IOPS, and how they are measured, what they mean, etc. In order to solve a puzzle you need every single piece - same with this concept. Let’s now talk about IOPS, how to calculate them, what the heck they mean, and the commonly misused ideas I have seen in the tech industry around IOPS and performance.
First, I am not going to be comparing spinning disks and SSDs - this is all general material. I would have to give two sets of specs, as SSDs can perform thousands more IOPS per second than a spinning disk ever could hope for. You can calculate IOPS and throughput the same way regardless, but we did need to learn about how drives and SSDs function so that IOPS make sense. (Plus it is just a super awesome technology and extremely precise)
IOPS is a metric used to measure the performance of a storage device or storage area network (SAN). The quantity of IOPS indicates how many different input or output operations a device can perform in one second. It may be used along with other metrics, such as latency and throughput, to measure overall performance. One thing to think about when someone asks you for more IOPS or what the IOPS figures are for a LUN off a SAN, local disk, NAS, whatever type of storage that volume is sitting on - is that changing the IOPS value does not always mean they will have better performance. This is one thing I see a lot of in my work with customers on AWS - “We moved that EBS volume to an io2 volume with X number of provisioned IOPS and I do not see any gains!” Sigh. Let’s dive into it.

How Do IOPS Determine Performance?
Great question, but it has a loaded answer.
When someone says “What kind of IOPS are you getting on Drive X?” They actually mean: “What is the total number of input and output operations per second that disk can do?” Well, it depends. What work is the disk performing? Does it host a SQL DB and that DB makes a ton of reports each day, and concurrently replicates (or log ships) to another DB inside another datacenter? Is it a game server, and all it does is load items into memory when assets are used, or does the server perform tasks that use entropy, so disk usage is very small?
The correct way to think about IOPS is to look at the average size of the requests being made, and how many writes and how many reads are getting completed over each second. SSD or NVMe drives will always have thousands of times more operations per second as nand storage operates totally differently and can have faster random read/write than a spinning disk’s sequential read speed (which tends to be the quickest operation for a spinning drive).
Next, we have to talk about a few more metrics. Starting with Average Seek Time. This is the literal time it takes for a disk to get to the file being called for. In a spinning disk, it is the time it takes the head to reach the target file on the platter. On a flash disk, it is the time to recall the file - but just the initial call, not the time to complete the action. That would be a different metric that is called Average Disk Read/sec and Average Disk Write/sec. All of these metrics are in milliseconds (unless something is really, really wrong). The final metric to think about is “back end” IOPS. This relates to the physical constraints of the media itself, and equals 1000 milliseconds / (Average Seek Time + Average Latency). This metric is only really calculated on spinning disks, I have not seen it used with flash much, if ever. You do not need to get the Average Latency from the computer as it is reported, but you can figure it out. Get the time it takes the platter to spin halfway around - you can do this by dividing 60 seconds / rotational disk speed (15,000 RPM) then divide the answer of that by 2 and then multiply by 1,000ms. Bam. Done.
So here is the math to figure out the Avg. Latency for a 15,000 RPM SCSI drive:
60 (seconds) / 15000 (RPM) = 0.004
THEN
0.004/2 = 0.002 * 1000 = 2ms is the Avg. Latency on a 15,000 RPM SCSI Disk.
Simple. For NAND based drives the Avg. Latency is typically set at 0.1ms which accounts for typical network overhead and congestion. Don’t ask me who came up with that but it is pretty spot on if you check your SSD average latency.
But they Rated the Disk at 4500 IOPS!
When you purchase a disk, you will see the IOPS listed on them - but you have to read the small print! The disk manufacturer can run any test with any conditions, with larger or smaller block sizes which will greatly change the IOPS reported. When I need to figure out if I have to provision an EBS volume or SAN LUN with extra IOPS, I first talk to the developer about the average block of the application they are using. So if the application is MSSQL, I know by default Microsoft recommends a 64 Kbyte block size, so no matter how large the total dataset is, my disk will always read the file in 64 Kbyte chunks. I can then use a tool like FIO (Flexible I/O Tester) to simulate 64 Kbyte block size performance over time, and I can also simulate and gather statistics for average throughput, latency, and more. FIO allows you to setup incredibly customized testing and I really recommend learning it if you want to benchmark properly before the developer comes to you and is concerned that throughput is bad on the VM. Also, becuase it is fully open source, you can get tons of community written tests and assistance. You can get your testing perfect with the variables we’ve talked about thus far, and really understand your performance before going into Dev.
Next I want to talk about the one argument I hear a ton - “Just throw more provisioned IOPS at the problem, and it will run better!”
Umm, sadly, it is not that simple.
We just talked about the average block size, but what about if your application is dealing with large sequential reads and writes - 500MB and higher. If you think about a disk as a highway with 10 lanes each direction, and when you read a file that is 500MB, all 10 lanes will fill up to carry that data to the right exit on the highway. That also means that any other call for data must wait for that 500MB call to complete or exit so the next call can use 5 of the 10 lanes. While those 5 lanes are reading a 1TB file, the other 5 lanes are reading tiny 45Kb files as quick as possible. The problem is that you are on a spinning disk, and that means as you are reading that 1TB file, the head must go to the 1TB file location, then back to the smaller 45Kb files, over and over and over again. This is going to slow down both operations. On flash, you see similar slowdowns depending on a number of factors but typically you can saturate the onboard controller which makes the disk queue rise. This will reduce the IOPS able to be generated until the controller has more bandwidth available. This was seen as a limit in newer PCs and even gaming consoles, so as always, someone figured out how to fix that.

When an SSD manufacturer makes a disk - say, Samsung - they custom make a NAND controller which acts like a processor for the device. Today most are ARM-based processors that can perform live encryption and decryption, it has memory onboard to capture the FTL mapping table (basically a map of your file locations), and it acts as a RAID controller for the NAND memory. That’s right - if you read most of the mid to high end SSD materials, they run a RAID controller on board, completely independent from any RAID array the disks may be part of inside your machine. This is becuase it is the most efficient and powerful way to manage what files go where and allowing commands like TRIM to run concurrent of any operation taking place. A Samsung 980 Pro is rated at 500,000 random IOPS! The disclaimer to that metric is that Samsung uses the “TurboWrite” feature on the drive, which takes advantage of the PCI-Express Gen 4 / Gen 3 direct drive access API. Meaning that unlike your current PC that has a 3.5 Inch SSD (or any spinning disk) from 2018 or even a first or second generation M.2 NVMe drive which has to shove data into memory, then the CPU can read the data out of memory, now, just like the Xbox-S/X, the CPU can access the NVMe storage directly and no longer has to wait for system memory read operations to complete. This is what makes them load games like lightning. Microsoft has announced the same feature for Windows 11, and games that can use the feature are expected in early 2023. The API is named “DirectStorage” and touts improved loading times of up to 18 seconds when compared to a spinning disk! This will also be awesome for games that are open world titles, as the world can stream in constantly without causing latency for the player.
(If you have Windows 11 and a 1TB M.2 drive, Windows has the feature enabled but the game must use the API from DirectX12, which is why it has no benefit until games get patches to use the API.)
Back to benchmarking claims - Samsung knows what the drive is going to need benchmark-wise to perform the best on paper. The settings used legally must be printed on the website of the manufacturer and the paper that comes with the drive. If you benchmarked your last disk and was sad when it did not hit the same numbers as the maker of the device stated, most likely you did not use the same settings and therefore, got a different result.
So when I see an email from a developer asking for more IOPS, my first reply to them is always the same. “Let’s run some benchmarks and see if you are even coming close to the performance you expect with more IOPS.”
So we run some benchmarks, and of course, my provisioned LUN has far more IOPS than what the developer is even asking for. I have to then explain that looking at his application and monitoring the average request size, we can run benchmarks again using the average request of their application and the IOPS are almost dead on to what the application is already doing. I then usually go down the list of typical questions:
Does your application operate in 32-bit or 64-bit mode? Have you optimized your application for a 64-bit system?
Does your application use asynchronous calls or does it run multiple threads in parallel? Does the application need to run asynchronously?
What block size are you using? Why?
If the application has a networking component, how are you reading and storing the data coming over the wire? Are you paging to disk (if so what disk is your paging setup on!?) or going direct into system memory?
Typically going through these questions I can get some application improvements and I never have to add IOPS more often than not. However, in AWS environments, you have to know more than just the disk speed as EBS or Elastic Block Storage has limits built into the instance type, burst protection, some instances have no limits until you reach a certain threshold of throughput - there are many factors that most devs never know about until they come to me with a ticket, asking why disk performance spikes, then plummets after 100GB. If they run into an issue like that, I make sure to be using an instance family with a lot of EBS throughput, and then, if I am still hitting a wall and EBS and the application can still keep going, we can add more IOPS, or as EBS calls them, Provisioned IOPS. There are only a few apps that I have done this for in the past, but media workflows that are rendering huge files, huge fluid or other simulations, media transcoding and encoding - these are all huge sequential tasks that can benefit from more IOPS being provisioned and you can use the built in metrics in CloudWatch to make sure you are not maxing out the EBS volume attached to one or more instances (EBS has multi-attach volumes - works great for Oracle RACs for instance). Before I wrap up on EBS/EFS/EC2 - pay close attention to the docs at AWS. If you want to use a specific instance family, use a calculator to figure out the disk performance you need. This is where you can begin. If you want specs alone, go here. Final note for performance best practices in AWS/EC2 - read the guide to best practices. It may be long, but there is so much gold to be mined from the documents. Just follow the link above, and select the compute type your company needs next or uses the most. You should also read up on Nitro Enclaves. Compute is a bit different at each cloud, so these are the AWS links - you should still follow the best practices in a general form no matter the cloud, and read your specific cloud provider’s docs.
The End?
No, this is not the end. I will go deeper into the world of IOPS and media in August, and link the post back to this one. I want to dive into real world metrics on my server and gaming PC to show you how to benchmark correctly, gather metrics and figure out how to tell if you need more performance and what type of performance you need for the types of activities you actually do day to day.
Thank you for reading as always, and I look forward to the next post.
Cheers and stay tuned!

Subscribe to my newsletter
Read articles from Jeremy Hall 🖥️ ⌨️🖱️ directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jeremy Hall 🖥️ ⌨️🖱️
Jeremy Hall 🖥️ ⌨️🖱️
I built my first pc when I was six, and have been working on them ever since. I began a repair and consulting business at age 12, and hired my mother to drive me to each site. When I completed high school I immediately had a constant position in Los Angeles that I used to catapult my career and see all the different datacenters, network types, Linux config, you name it. I have over 20 years of experience in engineering and enterprise operations, devops, and site reliability engineering. Some highlights of the places I've worked are MySpace, Internet Brands, Toyota NA, Toyota Connected, and I am currently at AWS.