😱Ops Horror Stories🧟♂️: The Tale of the Dead NetApp Filer
 Jeremy Hall 🖥️ ⌨️🖱️
Jeremy Hall 🖥️ ⌨️🖱️

DISCLAIMER: The tales told on the Ops Horror Story Blog series here at apt-get ops have been modified to remove former colleagues identities and identifying information. These also remove parts of the story which would give away critical information about past environments I have worked in. The details will be close but not accurate to today. All technical details will be how I remember them, as I wish to respect past NDAs and management.
Business as Usual.
Looking back at my past for a good story to tell you all, I thought about SANs and some of the past horror stories I have around them. Well, this one stands out becuase a routine, regular maintenance activity turned into 28 hours of hell. Just to set up this story before I start: the company I worked for at the time was, and still is one of the larger companies no one has ever heard of becuase they are not known by the legal name of the company, but more so by the names of their acquired sites and products. The company grows by 3rd party acquisition, not by creating and developing new ideas internally. Some of the verticals they are in are: Automotive, Legal, Home/Travel, Health and various media platforms.
This allowed me as a young Windows Engineer (I know, sorry, this is not a Windows Blog but I will explain myself on this) to learn so much about the world of enterprise Linux that I personally was able to use what I was taught and make the swap to the *Nix world from the Windows world. It was honestly one of the best career moves I have ever had, and I am so thankful to the people I worked with (you know who you are, and I know you read this blog) for taking time from their days to show me how things worked on the Linux engineering team. I was hooked from this job on, and it is what led me to love the Linux community, the Open Source community, and even go to my first SCALE which I ended up attending regularly when I lived in Los Angeles. (SCALE is the SoCal Annual Linux Expo - it celebrated 19 years this past July - Congrats!)
So there I was, a young and VERY curious engineer that literally at this point, had 2 jobs in the industry under my belt, and I joined this company for two main reasons. One, I loved the location, as it was closer to home and I was so tired of the commute into downtown Los Angeles, which took 1.5 hours each way, from my house. I also was able to get my foot in the door in an enterprise Linux team with super intelligent folks running it, and I was my boss’s right hand man, and was able to help teach the junior admin on our team. The other thing I loved, was that this position was not a helpdesk role - as I was over and done with Help Desk work and the people that were attached to that work. The last part I loved (loved at the time - today I would be horrified) was that because of the fact each one of the environments was completely different and had its own set of challenges.

At this company, we had scheduled maintenance downtime on the second Tuesday each and every month. During this time we would do all sorts of things such as using my PowerShell scripts to force any uninstalled or stuck Windows Updates across the server farm, install new firmware to TOR switches, run DR tests, add new routes or test failover routes on new network gear. This particular story, we planned to have a smaller team in place as we only wanted to install new NetApp software on the head(s) and update ONTAP so we could use the latest released features. This NetApp was our faster SAN at the time - as we had 3 NetApps at this company. One was used in staging, then two were used in production - one was an a slower SATA based SAN with 7,200 RPM drives which we replicated to Staging in our other datacenter and the second NetApp in production was an Highly Available/HA (two head controllers), SCSI-based, fibre channel SAN which was used on a number of our VMware clusters, and almost all of the Linux hypervisors (also some had NFS mounts to the device as well) had LUNs assigned to them from this SAN.
Anyway, let’s get back to the story.
It Began Like Any Other…
After work, all the involved engineers gathered and hopped over to our datacenter which was very close to the office. We had a conference room booked for our scheduled maintenances, and this time was no different. We came equipped with a 12 port switch and enough power strips to light up Las Vegas. We all sat around with laptops out, external mice in hand, prepping for the upcoming downtime. I began by checking my scripts to ensure they were error free prior to starting. For all the properties that had storage on the SAN, we had to stop IIS/Apache if the www directory was located on the NetApp, especially on the Windows side of the house as they did not handle failover well, and since we had downtime setup, we used it and lowered our chances of technical complications. Once all of our maintenance pages were online and verified externally (thank you Verizon hotspots) we began to prep the environment and SAN for the upgrade.
Before I continue, I want to talk about the process here. This was one NetApp shop in my day I worked at, but the process was literally written up for us by enterprise support. See, the service back then was custom to the SAN you had, or planned to operate on. At the time that this took place, NetApp still was wildly different with directions - it was before they standardized commands/SAN software as well as ONTAP, so literally each customer deployment of ONTAP was 100% custom to that specific customer and model of SAN. We used a 3rd party at this company to facilitate our Enterprise Support contract as well as they would get us custom directions for our updates when we told them we would be upgrading ONTAP, firmware on the heads/controllers, and sometimes NetApp wants you to update drive firmware depending on a large number of factors or if a critical fix was released for the drives in your SAN. This particular update involved all three of these, so we needed a lot of time in order to get back online before our timed window was over. The model we will work on in this story is a older FAS3240 SAN that had 4 or 6 drive shelves at the time, I cannot remember if I did the installation of the additional shelves before this story or after - but regardless, there was a ton of storage (for the time) and a ton of IOPS.
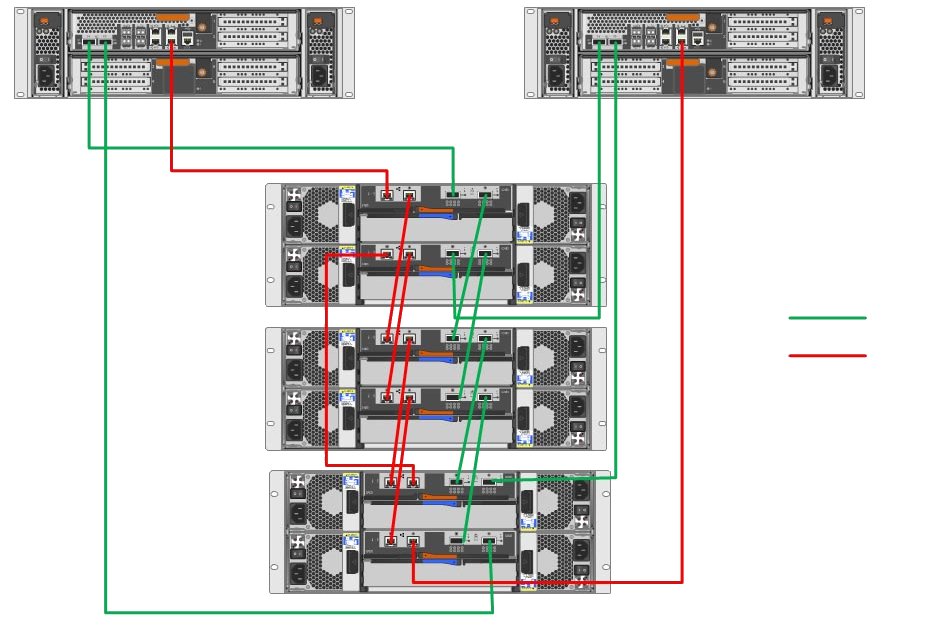
Example HA FAS3240 SAN Cabling for Heads & Three Drive Shelves
After myself and another engineer stopped IIS on the Windows servers, Apache/Tomcat/Nginx on the Linux side of the house, we began to follow the NetApp directions that were sent to us. We began the process of failing the A head out of the HA pair and into maintenance mode so we would be able to update the ONTAP installation. We also staged the HDD firmware package on the head so when that head would take over control of the SAN from head B, it would then be able to update each disk’s firmware package one by one. This process typically took anywhere from 20 minutes to a few hours depending on the disk and firmware. This one was pretty quick, estimated at an hour so we planned to do it at the same time as the ONTAP upgrade as the new version could leverage some small performance gains from the new firmware.
So we were able to run the update of ONTAP on head A, it rebooted and we waited for SSH connectivity to return and allow us to fail the A side into the cluster and take control while we failed the B head out and performed the same ONTAP update. We all confirmed we were ready, and the engineer issuing the commands to the NetApp said he was SSH’d back into the cluster and was ready to fail back to head A so we could initiate the ONTAP upgrade on the B side. Or so we thought.
Unexpectedly, when we tried to fail over control to head A from head B, the SSH session to the head locked up. Okay, we lost connectivity or something. The head has to be online right? We waited and the connection failed to come back. It was not evening pinging, and now, all the open NFS/iSCSI/SMB/Fibre connections that were active on head B, were completely lost, and a torrent of Nagios alerts began to flood our email boxes. Oh joy. What. Just. Happened. 😨 Our early night now just got longer. We are now at 11:30 PM.
💾fsck.
We all took our laptops and began the engineer walk of shame, down the long hallway into the datahall, through the mantrap and the few doors in between us and our cages. We arrived at the cage and we began to check the gear and figure out what in the heck was going on. We followed the directions to the letter, so whatever took place, was just a gift from the tech gods to see how we could handle this pickle🥒 we had ourselves in.
Let me pause for a moment, as it is very, very important to understand what just occurred to the same scope we understood it. One minute we had a fully functional, yet, offline web farm that was waiting to return to normal operations with tens of thousands of open sessions to this SAN in various flavors. All of the prod boxes used this SAN due to the fast storage and it offered the best performance per GB we had at the time. This was before AFAs (all flash array📸) were even an option, you just started to see servers come out with SLC and MLC based SSDs, and even then, you would more often than not, see consumer grade SSDs from now non-existent companies like OCZ and PNY. NetApp at the time did not offer any flash yet, and 3PAR was about 3 years away from having an all flash array. I know this as my next job we used 3PAR heavily and I got to install and try out the first AFA they produced.
Back to the story though - we stopped at the point where we updated the A head unit, and B was the primary controller and we then tried to fail over to A, but the terminal session cut off.
The A-side head that was active actually failed completely, and was found offline in the cage, but all the disks were online, not flashing with updates anymore. Shoot. Shoot. Shoooooooot. This just turned into a massive data restoration project. Let’s talk about why for a minute.
All of the VMwarESXi hypervisors lost the connection to the active head unit but they were setup with two paths - every single hypervisor or server that was on the SAN (keep in mind, a storage area network is its own separate network, typically all fibre channel) was not able to mount any of the assigned LUNs, the OS of those systems was unable to complete any writes and reads they had queued up, and many systems froze entirely due to the severity of the outage. We were in the process of upgrading the Linux server farm, and the newer servers used SD cards or microSD cards (some used a pair for redundancy) so those bare metal servers continued to run but all the mounts listed in fstab needed to have fsck run (File System Consistency Check) to verify there were not and blocks or sectors with errors which would need further maintenance. Oh, this did not even include all the virtual machines on each hypervisor. As I mentioned, we were upgrading servers to be able to be far more dense per rack unit. Unfortunately for us (but thankfully for the bottom line), we did achieve the goal, and maybe a bit too well. IIRC, we had moved from being at ~20 virtual machines per OU to roughly double and sometimes triple that size. 60 VMs per RU at the time of this incident was just bananas - but our Linux team was amazing, and I still know some of the people that will read this were on that team, so I know they are enjoying this return of an old wound! 🤕
The B side head unit was now running the older version of ONTAP and the heads had not yet synced up and processed the changes. Then the A side head had a different version on ONTAP, so neither head would talk to the other, so we were more than slightly worried at this point. Think about yoinking the power cord out of a gaming PC while you are installing Windows or a huge Service Pack. 9/10 times you will recover from it, but at what cost? This just now took place for every single virtual machine and hypervisor in our cages. What does Linux do when the boot volume has a disk failure event? That’s right, it wants to run every single Admin’s least favorite tool - fsck. To run this, first we had to get the NetApp back to working status though, so let’s first finish up what we have to do to get that back up and humming away before we get into how to manage 3,000 VMs that all want to run fsck at the same time. The stress of all of our VMs running fsck on all disks on the NetApp would have brought the poor array to its knees in a hurry. But before we can even begin to come up with a plan of action to get our server farm online, we need to fix the darn thing so we have two heads on the same ONTAP version, with both heads out of maintenance mode and operational as an HA pair.
Thank You for Calling NetApp, This is 🧔🏻♂️Tom, How Can I Help? 🆘
Me and the other engineers went back to the conference room to call NetApp and get through the 2 pages of questions we knew they would ask us to really confirm that the head was dead in the middle of the manual failover to upgrade the OS. Luckily for us (well, not really, but kind of) we had to replace the B side head about 6 months prior to this specific event. It had a failure of the mainboard and it was simpler to just swap the HU out and make sure all the faulty equipment is out of the environment. The engineer at NetApp was super helpful and I cannot say enough about how well he was at keeping calm, and locating the parts for our tech to install. The motherboard and power supply literally were sitting 1 mile from our datacenter, inside of LAX International Airport inside a cargo terminal/warehouse that all types of tech companies contract with to perform laptop/desktop repair right on the airport grounds. In case you had no idea about the world of (insert brand) repair, becuase they can ship all the laptops or whatever they fix right to the airport, and then turn them around in 12 hours or less, it saves the company millions of dollars a year to have these types of facilities close to major cargo terminals.
The engineer from NetApp Support put the parts on hold for us, and called IBM to dispatch a tech to our location. To hurry the process up, we asked if we could just go get the parts and wait to have the tech on-site, which they said was not typical but given our time restraints they would allow it. We sent out our NetEng resource to pick up the parts if I remember correctly, and we proceeded to order pizza and lots of caffeine. I was in charge of communications during the event and was sending out updates each hour so those at home would understand what was going on. Luckily, this only took out prod servers, all of Dev and Stage were safe inside our datacenter in the office building which meant that all of the devs could work just fine.

This is a FAS3240 From Back Then. Baller. It Has 2 Disk Chassis 2HUs.
The tech arrived within the four hour window that we had with NetApp premium support - I cannot remember what exactly they named their support products, but we had a 4 hour parts and tech SLA for any issues we had. By this time, it was 3AM. With about 6 hours of time elapsed, all of us began to slow way down. On this support call, we had a guy come in and do the repair pretty quickly - a bunch of us helped out in the cage so we would be able to get prod back up and running ASAP because those keeping tabs on things, we still need to run fsck against all the data and boot volumes that are located on the filer. The only way to do this without taking too long was to stagger the boot up of all our servers. Not just the hypervisors, but the VMs on the host. We decided that we would go down the list by web property and that would be the best way to get back online the quickest.
We still have a big issue though, we now have a head on our filer on a lower release of ONTAP and a second head that is on a newer version of ONTAP, and they are maintenance mode. Netapp took time on the phone to take us through the process of getting the HA pair back in sync, and once we were able to update ONTAP in almost the same way that the first time we had to update it, we made progress. The heads noticed each other and knew they were a pair of NetApp FAS3240 Heads with 6 drive drawers under them and they were supposed to be in an HA pair, but that showed as broken. After wrestling with the two heads, support was able to give a command they tested in their lab and knew would put things back how they were supposed to be.
Heads Up.🤯
So we ran the command NetApp gave us and we were able to get the heads up and back into HA correctly. All of the machines we had on to monitor pathing on the SAN showed us two active paths, and when we attempted a failover test, it worked perfectly. The last issue was updating the drive firmware on the filer. That was kicked off at around 4AM. It took a good solid hour but once done, we got started on bring sites back to life and checking all volumes. One by one hypervisors came online and would monitor the NetApp’s metrics to ensure we were not maxed out in IOPS and in queue size/depth. Getting all of this back up took us well into 10am, and I got back home 26 hours from when I left. This was one of the longer, single session outages that we dealt with at this company but I learned a ton doing it all. I think having a team that teaches during outages becuase they know what they are doing and are confident in doing their work is key to having a good mentor. I was always with the Linux team, picking up commands, troubleshooting issues, they even let me have a login to help out. It was the first time I was on an ops team that was all Linux based.
All in all, we lost no data, and there were machines that had our largest databases and stores on that filer so even after we all left, the incoming team began to resume our work and get of the machines online. These are the kinds of events that stick out to me and make me remember specific people and how good they were to me and how much I have loved getting to where I am today. The journey starting out was so hard - I had to sell my skills and prove time and time again why I was good at my job when I have no degree to my name from some collage. I do not need one nor do I want one. I am so proud of how hard I have worked since building my first PC when I was six years old. Everyone and everything I have done has been my education. That is why it is hard to find people in ops that are well-trained and have good interpersonal skills. Books are great for black and white scenarios, but out of the land of tech, we all know that every shade in the visible color spectrum exists and likely most of the IR spectrum is needed just to give enough space to allow for all the insane use cases companies have decided is how they want to perform it. No one is the same, so being able to know what DNS means at a super low level makes you the better candidate for the job, 9 out of 10 times. When I hire, I can spot people that have talent a mile away. Unfortunately, the same is true about people I never would recommend to hire. No matter how many times I tell candidates to just say “I don’t know” in an interview, they still try and BS their way through the whole thing. Don’t do that.
Anyway, I hope you enjoyed the first story in this series. I am putting all kinds of stories like this into my kanban board and organizing them. It has been fun to think back to these operational hell moments and really give some thought to them and what I got out of them. If you want to tell us about your hell story, shoot me an email at: ideas@aptgetops.tech
Until next time.
Subscribe to my newsletter
Read articles from Jeremy Hall 🖥️ ⌨️🖱️ directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jeremy Hall 🖥️ ⌨️🖱️
Jeremy Hall 🖥️ ⌨️🖱️
I built my first pc when I was six, and have been working on them ever since. I began a repair and consulting business at age 12, and hired my mother to drive me to each site. When I completed high school I immediately had a constant position in Los Angeles that I used to catapult my career and see all the different datacenters, network types, Linux config, you name it. I have over 20 years of experience in engineering and enterprise operations, devops, and site reliability engineering. Some highlights of the places I've worked are MySpace, Internet Brands, Toyota NA, Toyota Connected, and I am currently at AWS.