A Kilobyte of Data Exploration with Arrow
 Kae Suarez
Kae Suarez
When you're starting to work with a brand new platform, you want something simple to help get a feel for how it works. Something small and approachable. Not a voyage unto new horizons for science, but a small swim for yourself to settle in.
So, here's a small first blog on Hashnode, about my first use of Apache Arrow. For the sake of being something quickly approachable, I'll work with something I know: a dataset from a tabletop role-playing game (TTRPG) I know how to talk about (And haven’t played for most of the last decade – but more on that later).
This is not a massive achievement of data science, but a cute microcosm of working with data in general, so I'm going to talk about it.
I'm not just going to waste work by not talking about it, right?
Exactly.
Hashnode
That you can read this is proof I figured out Hashnode.
Apache Arrow
Now for the interesting part: Apache Arrow. Lots of people have talked about this, and I'll shamelessly link to an article of someone I know that includes an explanation.
I'll include a quick glance here regardless.
Arrow is a polyglot library with a C++ interface , that implements a columnar in-memory data format accompanied with a suite of data manipulation and analysis functions. The data manipulation functions are optimized for the server they are running on, but, for such small data, much more important is that they save me time I would have to spend implementing them to handle my problems anyways..
Why columnar? The columnar format is efficient for packing data and making operations over columns faster. Packing a column is nice for dodging cache misses. This data is too small to get large real-time gains from this. At scale, however, this optimization is a critical one, as cache misses take up valuable CPU time. Also, the format is also well-suited for parallelization. Consider a situation in which a transform must be applied to multiple columns in data. By splitting our data into columns, we can let a different thread handle each column, or even split up columns internally.
Okay, background done on my tools.
Now for data.
Data
I once tried to make a calculator for how hard a monster is to fight as per the esoteric numbers made up in Dungeons and Dragons Fifth Edition (5e). However, it used knowledge from a book, which not only costs money, but also contains content difficult to use due to license.
Another option is the game's Source Reference Document (SRD).

The SRD is a blessed land where us software developers (and writers, game developers, etc.) can take whatever we want. The licensing is very permissive for any content in this specific document for a given game, and it is generally hosted online.
However, making a game’s mechanics available for free is not incredibly profitable. Thus, 5e has a decidedly empty SRD, to ensure books are sold instead of an online document being the main source of information. It simply does not have the numbers necessary to write this blog (or that old calculator, a younger me was begging for an attack from Hasbro, owners of Dungeons and Dragons).
Well, pack it up, go ho-
Oh, there's a another game with a more full SRD? With free and accessible data? I just have to work with Pathfinder, a game I left behind half a decade ago?
Fine.
We'll use that.
Pathfinder is a different TTRPG, in the same genre as Dungeons and Dragons. Fantasy monsters, too many numbers, the works. Most importantly for us, it has a very full SRD, (read: free data!) as pictured above.
This means it has the numbers to write this article.
Now, while this is a non-code step, I mention it because it's an important part of my journey with data. I learned that getting data can be a legal mess, and figuring out the problems before collecting the dataset for use is good. Lesson learned.
Anyways, onto the SRD that has what we need.
Pathfinder has the following table offered on the SRD:
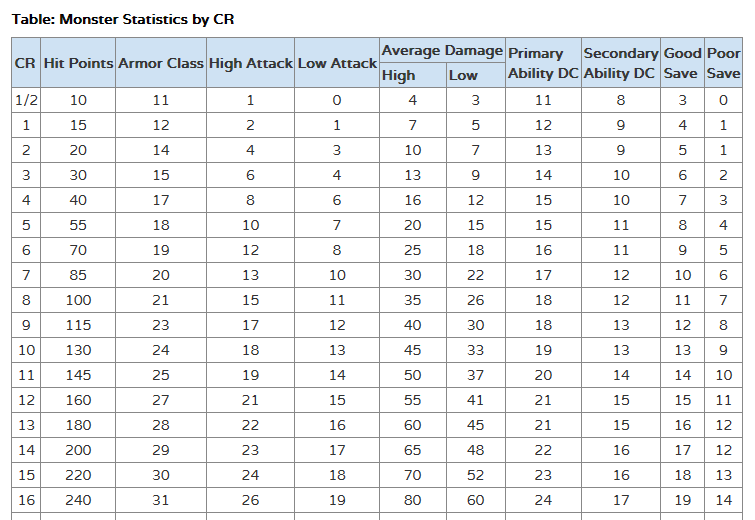
If this looks like a cloud of meaningless numbers, you are one step closer to understanding the game. For this article, you only have to know the following:
CR means "Challenge Rating," and is our target value. It symbolizes how hard a monster is to fight.
Every other number is a game-relevant value (commonly known as a statistic, or stat) a monster has. In other contexts, this is where we would have population of a city, for example.
This table is meant to be read row-by-row, in which all the values in a row correspond to a given CR. CR is the really important value.
When used by hand, you find each stat a monster has, look for what row the corresponding value fits in, and get the CR for that stat. Get the average of all these searched values, and you get the monster's overall CR. With that, you'd have a number symbolizing difficulty.
For example, let's take a Satyr, whose stats are as follows:

And the monster creation table, which I'll repeat here:
A Satyr's health points (hp) are 44, which, if we refer to the table, correlates to a CR of 4. Then, its armor class (AC) is 18, which correlates to a CR of 5.
Repeat this for every stat in the table. (Don't actually do that. I am simply saying what would need to be done.)
Eventually, we learn a Satyr has a CR of 4. This is after a lot of referring to values corresponding to the Satyr and comparing them to those in the table, and finally getting a sum, then an average.
Wow, this seems annoying, and like it could be done with a computer! If only someone did tha-
The Actual Example, Finally
So, what's our goal, with our table? For now, it'll be to retrieve values from a monster, except for its CR, and see if plugging those through the table gets the CR provided with the monster. Basically, check the authors' work, by mimicking the by-hand method.
But faster, because we're using a computer and a nice library.
First, I turned the table into a CSV.
It was painful. I do not provide code for it, because I did not use C++, I found a converter from HTML tables to CSV.
Then, I had to clean it up, from there. For one, the nested columns just do not mesh well with a CSV, and 1/2 is a string, not a number, so that had to be changed to 0.5. Another problem was that some columns are nested. These had to be turned into single columns. I didn’t make a program, because these were small processes I could handle by hand, and faster than making a program for it.
Lots of unfun cleaning, which I will not lay out in detail. Here's the file.
Everything from here on is more fun.
Next, I read the cleaned CSV with Arrow! For CSV reading, I have a helper function I like to keep on hand:
Status read_csv(std::string path, arrow::Result<std::shared_ptr<arrow::Table> > &out){
arrow::io::IOContext io_context = arrow::io::default_io_context();
// This opens up the file at the supplied path.
std::shared_ptr<arrow::io::ReadableFile> infile;
ARROW_ASSIGN_OR_RAISE(infile, arrow::io::ReadableFile::Open(path))
// This section makes a reader to do reading, using default options.
arrow::Result<std::shared_ptr<arrow::csv::TableReader> > maybe_reader;
ARROW_ASSIGN_OR_RAISE(maybe_reader, arrow::csv::TableReader::Make(io_context, infile, arrow::csv::ReadOptions::Defaults(),
arrow::csv::ParseOptions::Defaults(), arrow::csv::ConvertOptions::Defaults()));
std::shared_ptr<arrow::csv::TableReader> reader = *maybe_reader;
// Finally, we just read -- we're returning by reference, here.
ARROW_ASSIGN_OR_RAISE(out, reader->Read());
return Status::OK();
}
To read this CSV in particular, which I called Basic_CR.csv, I call the function like so:
arrow::Result<std::shared_ptr<arrow::Table> > basic_cr_ret;
ARROW_RETURN_NOT_OK(read_csv("data/Basic_CR.csv", basic_cr_ret));
std::shared_ptr<arrow::Table> basic_cr = *basic_cr_ret;
This is the moment I was sold on Arrow. C slowly killed me when it came to reading in tabular data, and this feels like doing it for free, in comparison. However, sold or not, this is also a learning experience. There's more to write!
Now we have columns of stats, and a column with CR values. What we need is a set of CR's to get an average of, like we would by hand. Thus, we'll need to get all these outputs in an array, which we'll prepare before getting down to business:
arrow::Int64Builder builder;
std::shared_ptr<arrow::Array> CR_vals;
A Builder is an Arrow class which is used to build up Arrays. You fill it with values, then flush it to your final object. We'll need to append CR values as we'll calculate them.
Though, there's something else to deal with first, as always.
Now, the way the data's formatted, a given stat gives some CR...in theory. However, in reality, our data has approximate values per CR. Take this column, for example, where there are clear gaps between each value:
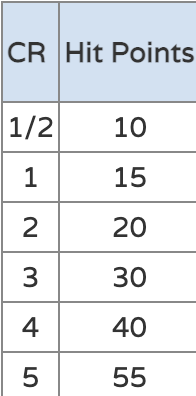
This means that, for a given target value, there is a range of acceptable stats. Normally, we eyeball this.
Computers are notoriously lacking in eyeballing capability, without some implementation.
So, how do we implement that? Just figure out which CR is closest! Just for the sake of ease, we'll do the naive route.
- Get the distance from our target value to each value in the column via subtraction.
- Find the minimum of these distances.
- Return the index of this minimum, as to fetch the corresponding CR.
We'll let Arrow handle tie-breakers, we don't need to be too careful here. This function implements this generically, since we'll need to do this for every stat:
Status calc_cr(std::shared_ptr<arrow::ChunkedArray> arr, int64_t in, int64_t &out){
// Set up input to function as an Arrow Scalar.
std::shared_ptr<arrow::Scalar> m_val;
ARROW_ASSIGN_OR_RAISE(m_val, arrow::MakeScalar(arrow::int64(), in));
arrow::compute::IndexOptions index_options;
arrow::Datum datum;
// Perform subtraction from each value in array from our input value.
ARROW_ASSIGN_OR_RAISE(datum, arrow::compute::Subtract(arr, m_val));
arrow::Datum abs;
// Get absolute value (distance) for each difference.
ARROW_ASSIGN_OR_RAISE(abs, arrow::compute::AbsoluteValue({datum}));
arrow::Datum min;
// Find minimum distance.
ARROW_ASSIGN_OR_RAISE(min, arrow::compute::CallFunction("min", {abs}))
arrow::Datum ind;
index_options.value = min.scalar();
// Get index of minimum distance, then return.
ARROW_ASSIGN_OR_RAISE(ind, arrow::compute::CallFunction("index", {abs}, &index_options));
out = ind.scalar_as<arrow::Int64Scalar>().value;
return Status::OK();
}
Here's how that's called for a given stat (note that we append to our Builder here):
int64_t hp_cr;
// Call our CR finder for the "Hit Points" column, with a hard-coded 44 from Satyr.
ARROW_RETURN_NOT_OK(calc_cr(basic_cr->GetColumnByName("Hit Points"), 44, hp_cr));
builder.Append(hp_cr);
Now, there's another case to handle. In our table, there's a concept in which you may end up having different values that map to the same CR (remember, this is danger level).
From a fictional standpoint, consider the danger of a hyper-poisonous spider that always hits, and a giant that'll miss pretty often. Both hurt a lot, but they clearly are dangerous in different ways. Our table chooses to represent that by allowing high and low attack bonus, which just means high accuracy and low accuracy. This section is pictured below -- notice the gap in values, even though it's the same row and same statistic.
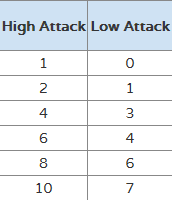
I have no idea why they do this, when they could simply let the averaging process at the end handle it, but this is what we have to work with.
Luckily, mapping to the average of these two columns mostly handles it. We are less resilient to edge cases via this method, but testing has had successes so far regardless. We'll just get the average of these two columns, with Arrow, then use our searching helper function on the new array:
arrow::Datum two_col_add;
// Add together every value across the Low and High Attack columns.
ARROW_ASSIGN_OR_RAISE(two_col_add, arrow::compute::Add(basic_cr->GetColumnByName("Low Attack"), basic_cr->GetColumnByName("High Attack")));
arrow::Datum two_col_avg;
std::shared_ptr<arrow::Scalar> two;
// Divide by two to get the average -- have to use an Arrow Scalar holding 2.
ARROW_ASSIGN_OR_RAISE(two, arrow::MakeScalar(arrow::int64(), 2));
ARROW_ASSIGN_OR_RAISE(two_col_avg, arrow::compute::Divide(two_col_add, two));
int64_t atk_cr;
ARROW_RETURN_NOT_OK(calc_cr(two_col_avg.chunked_array(), 6, atk_cr));
"Average Damage" also has a high/low section, so we apply the same method there.
Okay, so, after calling these over and over, for every variable, we get a bunch of CR values: one per stat. All of these are in an Arrow Builder...which means more Arrow usage! We finally get to flush that Builder to an Array:
ARROW_ASSIGN_OR_RAISE(CR_vals, builder.Finish());
Then, we can get the average of the integers in that array, and call it our output:
arrow::Datum final_val;
// Compute mean of column.
ARROW_ASSIGN_OR_RAISE(final_val, arrow::compute::Mean(CR_vals));
// Round mean to nearest integer.
ARROW_ASSIGN_OR_RAISE(final_val, arrow::compute::Round(final_val));
std::cout << "Final CR: " << final_val.scalar()->ToString() << std::endl;
This is hard-coded right now, for a monster called a Satyr. It could be modified to take arguments if I wanted a more full-fledged application. I am not currently trying to enter this space, though, and am enjoying my current job and hobbies.
Regardless, as is, we can run it, and get the actual output for a Satyr's CR! And it matches (Just pay attention to how the circled value matches. That's what we calculated.)!
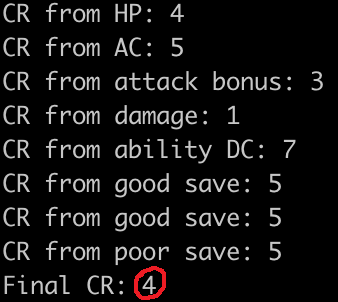
Neat!
Conclusion
In hopes of preventing a hard stop on the word "neat," I wanted to add this little conclusion, to also wrap up some ideas.
I am from an HPC background, not data science, so this project was actually a very sweet little introduction to my new data-focused life. It gave me experience with legality of datasets, it gave me experience getting data into an operable format, it was all just very neat. Coming up with a problem to explore with the data was fun!
Then, there's Arrow. In general, doing all of this would have taken me a while, by hand. I would have had to handle the memory myself. Reading in from a CSV would have had the usual pain points in C++, and I would have had to cook up a good method to work column by column. In fact, I probably wouldn't have thought to work column by column, and would have gone over all the rows nice n' slowly without Arrow. Arrow let my programmer efficiency skyrocket, and I really enjoyed that.
The data was only a kilobyte, leaving us with little in the way of performance comparison. Also, I don't have a baseline code. However, where Arrow performs best is at scale -- all those optimizations in the format and functions really shine when you have a lot of data. The programmer efficiency is the bow on top that'll let me easily handle larger data in the near future.
I came away from this with a better understanding of how working with data works, and how Arrow'll enable me to do it.
Neat.
Acknowledgements
I may have left academia, but I still think acknowledgements are nice. Thanks to my friend Emilia for still enjoying Pathfinder and helping me understand things without relearning all of it. Thank you to Keith Britt, Fernanda Foertter, and François Michonneau for helping me get the words right for my first blog. Finally, thank you to Marisa Harriston and Maura Hollebeek for helping me navigate the wild world of actually putting a nice picture at the top of a blog.
Subscribe to my newsletter
Read articles from Kae Suarez directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by