Coding challenge Day-7
 Ameh Elijah Uma-Ojo
Ameh Elijah Uma-Ojo
UTF-8 Validation
Today's challenge made me excited and it's not because it was simple to do but the research I had to put in to even understand the question. Generally, the challenge is about checking if a UTF-8 code is valid or not.
Thought process
Today again I was blank for almost 20 minutes just staring at the question trying to understand what was happening on the description page. Truth be told, that description was not it at all. I couldn't get hold of it early enough. After some time, I went to YouTube to check about UTF-8 code generally and I found out it was more.
According to Wikipedia
UTF-8 is a variable-width character encoding used for electronic communication. Defined by the Unicode Standard, the name is derived from Unicode (or Universal Coded Character Set) Transformation Format – 8-bit.
Each character in UTF-8 is represented by one to four bytes, subjected to the following rules:
For a 1-byte character, the first bit is a 0, followed by its Unicode code.
For an n-bytes character, the first n bits are all 1's, the n + 1 bit is 0, followed by n - 1 bytes with the most significant 2 bits being 10.
So my first approach was to use the sample example to understand how the output will look like.
For a valid UTF-8, it will be;
Input: data = [197,130,1]
Output: true
Explanation: data represents the octet sequence: 11000101 10000010 00000001.
It is a valid utf-8 encoding for a 2-bytes character followed by a 1-byte character.
From the result, you can see that it obeys the rules of a valid UTF-8. That is since it's a 2-bytes character for the first integer, the n-1 bytes in this case 2-1 which is the 1, meaning next 1 byte must start with 10.
For an invalid UTF-8 example
Input: data = [235,140,4]
Output: false
Explanation: data represented the octet sequence: 11101011 10001100 00000100.
The first 3 bits are all one's and the 4th bit is 0 means it is a 3-bytes character.
The next byte is a continuation byte which starts with 10 and that's correct.
But the second continuation byte does not start with 10, so it is invalid.
From the result, you can see that it does not obey the rules of a valid UTF-8. That is since it's the first integer of the array is a 3-bytes character, the n-1 bytes in this case 3-1 which is the 2, meaning the next 2 bytes must start with 10 and by checking through the output you could see that only the second byte started with 10, the third didn't and for it to be valid both the second and third has to start with 10.
After breaking it down this way I knew the next part will be to write the codes that will perform the checking.
First, it will be important to convert each of the integers in the array to binary numbers and then auto-fill the front digit with zeros to complete it to 8-bits(8 digits). For example, since 1 is equal to 1 in binary, I will have to auto-fill the first six digits to be zero. It will be 0000000+1 which is 00000001
After this first step, I will then loop through the array and check if the first binary of the array is 1,2,3 or 4 bytes. If it's anything above this, I will return false immediately. If it meets this condition I will then check the byte of the first binary by checking the position of the first 0. After checking this, I will then check the next n-1 bytes where n is the byte of the first binary and confirm if the first two digits are equal to 10, if it's not equal to 10, I will return false, else I will return true.
This was my thought process! Pheww😅
Implementation
In order not to bore you, I implemented exactly how my thought process was and I had some syntax challenges along the way but I was able to clear them with Googling (one of my best skills I guess😂) and my code passed!🔥🔥
What I learnt
I learnt so so much about UTF-8 because I spent so much time trying to first understand the question
Conclusion
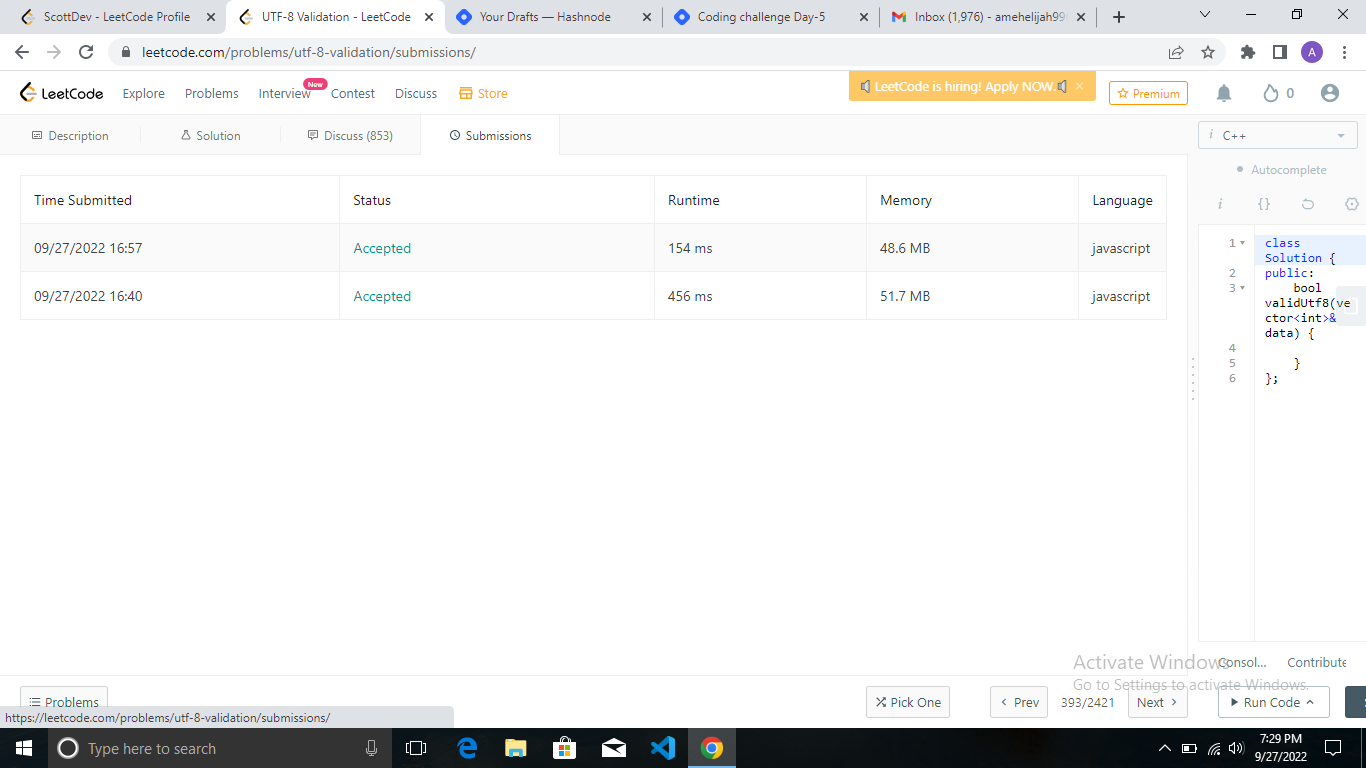
Today's challenge is my best so far because I was proud of the way I was able to navigate my way through the tough question to get a passed code.
My code had a memory usage of 48.6MB with a runtime of 154ms.
Thank you for reading through!
Day seven(7) done, three(3) more days to go!
You can follow me on Twitter
Subscribe to my newsletter
Read articles from Ameh Elijah Uma-Ojo directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ameh Elijah Uma-Ojo
Ameh Elijah Uma-Ojo
I'm a talented frontend developer with expertise in JavaScript, React, Tailwind, Firebase and a lot of other technologies. With a passion for creating intuitive user interfaces and seamless user experiences, I specialize in building modern web applications that are both beautiful and functional. In addition to my development skills, I'm also interested in technical writing. I enjoy sharing their knowledge with others and have a talent for explaining complex technical concepts in a clear and concise manner. When not coding or writing, I enjoy keeping up with the latest trends and advancements in technology. I'm always looking for new and innovative ways to improve my skills and stay on the cutting edge of the industry. Overall, I'm a versatile and driven professional with a bright future in both frontend development and technical writing.