Testing a classification tree
 Avinash Gupta
Avinash GuptaOutput
Explanation
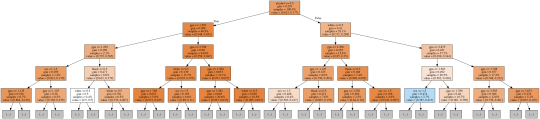
Decision tree analysis was performed to test nonlinear relationships among a series of explanatory variables and a binary, categorical response variable. All possible separations (categorical) or cut points (quantitative) are tested.
This decision tree uses these variables to predict output variable (TREG1) – whether person is a smoker, or not:
BIO_SEX – categorical – gender
GPA1 – numeric – current GPA
ALCEVR1 – binary – alcohol use
WHITE – binary – whether participant is white
BLACK – binary – whether participant is black
To train a decision tree I’ve split given dataset into train and test datasets in proportion 70/30.
After fitting the tree I’ve tested it on test dataset and got accuracy = 0,826. This is a good result for a model, which is based only on three explaining variables.
From decision tree we can observe:
Participants who used alcohol were more likely to be smokers.(up to 5 times more smokers who used alcohol)
Most smokers are white
People with lower GPA are more usual to be regular smokers
Code:
import pandas as pd
import sklearn.metrics
from numpy.lib.format import magic
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
from io import StringIO
from IPython.display import Image
import pydotplus
RND_STATE = 55324
AH_data = pd.read_csv(“data/tree_addhealth.csv”)
data_clean = AH_data.dropna()
data_clean.dtypes
data_clean.describe()
predictors = data_clean[[‘BIO_SEX’,’GPA1′, ‘ALCEVR1’, ‘WHITE’, ‘BLACK’]]
targets = data_clean.TREG1
pred_train, pred_test, tar_train, tar_test = train_test_split(predictors, targets, test_size=0.3)
classifier=DecisionTreeClassifier(random_state=RND_STATE)
classifier=classifier.fit(pred_train, tar_train)
predictions=classifier.predict(pred_test)
print(“Confusion matrix:\n”, sklearn.metrics.confusion_matrix(tar_test,predictions))
print(“Accuracy: “,sklearn.metrics.accuracy_score(tar_test, predictions))
out = StringIO()
tree.export_graphviz(classifier, out_file=out, feature_names=[“sex”, “gpa”, “alcohol”, “white”, “black”],proportion=True, filled=True, max_depth=4)
graph=pydotplus.graph_from_dot_data(out.getvalue())
img = Image(data=graph.create_png())
img
with open(“output” + “.png”, “wb”) as f:
f.write(img.data)
Subscribe to my newsletter
Read articles from Avinash Gupta directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by