Scaling journey - from 16k to 160k users.
 Surbhi Garg
Surbhi Garg
In my previous article, I explained how we are using a queue-based application that uses sidekiq for the management of queues. We were able to process jobs in the background using this architecture but with growing requests, it was difficult to process the prolonged waiting jobs in real-time. The increase in the scale resulted in the increased waiting time for the jobs. In this article, I will explain how we scaled our systems to handle a 10x increase in users.
Old Architecture
The ElasticCache(Redis) maintains all jobs in different queues. The priority of each queue can differ based on the job they perform, for example, some jobs like automatic cleanups and daily schedules are of less priority and can wait until the execution of high-priority jobs such as user-initiated jobs. The user-initiated jobs need immediate attention and should be processed in real-time.
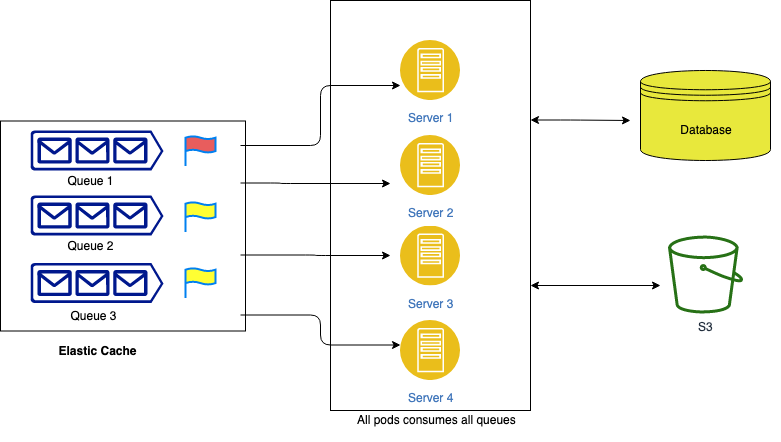
In the image above, we can see that all the servers here consume jobs from all the queues simultaneously based on queue priority. This means at a given instance, any server can process jobs from any of the mentioned queues. However, the resource and time requirements for different jobs aren't the same. Some jobs can take a large amount of time and resources to execute, while others consume minimal resources and finish instantly. This leads to resource contention during peak load.
For example, there are times when all the pods are busy processing the low-priority queues and thus the high-priority jobs have to wait until their execution is finished. This can result in longer waiting times for customers.
A basic solution to this problem can be scaling the servers horizontally in order to consume more jobs. The drawback to this solution is that it does not guarantee the faster pick up of high-priority jobs if there are many low-priority jobs waiting in the queue already.
New Architecture
In order to overcome this, we came up with an approach to distribute the pods in different groups based on the queue types. Servers in each group are responsible for executing jobs of a similar type. Based on the nature of the job, consumption rate and priorities we can divide them into different queues such as slow queue(that contains jobs which take longer to execute), fast queue(that has faster-executing jobs), user-initiated queue(contains jobs that are initiated by a customer and are of utmost priority) or scheduled queue(that contains jobs like scheduled cleanup jobs ). These queues can be divided further into multiple groups of similar characteristics. The server groups can also be divided into multiple pod groups catering to the requirements of specific queues.
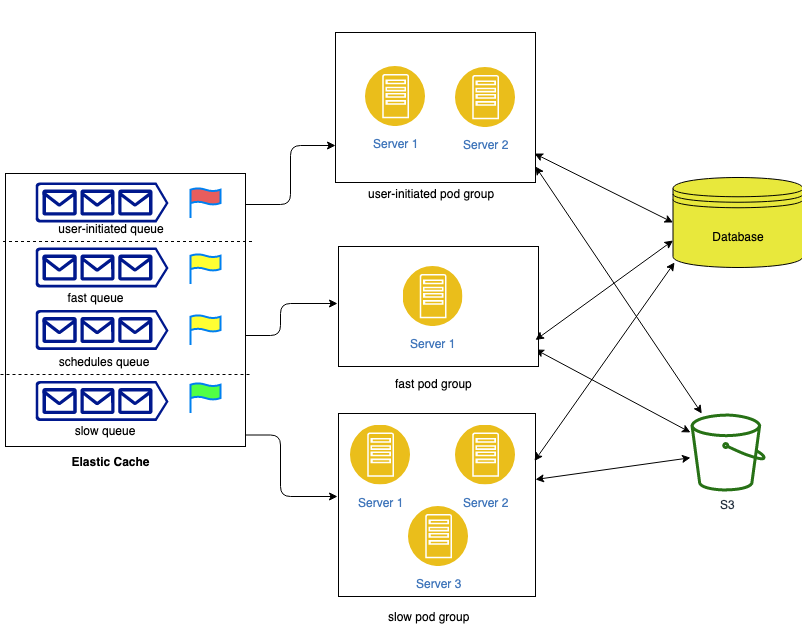
Here, servers in the user-initiated pod group will consume only those jobs that are present in the user-initiated queue. There are two servers attached to this pod group to maintain high availability. In case of high traffic, we can horizontally scale this server group.
Similarly, the fast pod group will consume jobs from fast and scheduled queues. This pod group requires only one pod because the resource consumption is minimal here. But this can also be scaled up or down according to consumption.
The slow pod group, on the other hand, requires more resources and thus has a large number of servers to execute slower jobs.
**How can we achieve this in sidekiq? **
- Create independent config files for each pod group. config/sidekiq-user-initiated-config.yml
:concurrency: 3
:queues:
- user-initiated
config/sidekiq-fast-config.yml
:concurrency: 3
:queues:
- [fast,7]
- [schedules,3] #You can set priorities for each queue
config/sidekiq-slow-config.yml
:concurrency: 3
:queues:
- slow
- Start the sidekiq with the required config file
bundle exec sidekiq -C config/sidekiq-user-initiated-config.yml
With the help of this architecture, the scaling became easier and we further implemented Horizontal Pod Autoscaling based on the queue requirements at a pod group level to utilize resources in an optimal way.
Thank you for reading. Happy coding!
Subscribe to my newsletter
Read articles from Surbhi Garg directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by