Custom fake data generator
 André Lademann
André Lademann
In 2019 (and still in 2022), we probably do not need to create data, we just need to print out one of the famous Twitter channels. Just kidding. :) Sometimes we need millions, I mean gigabytes of test data, which are really close to the data we are using later for our new hyper big data application. There is a need for, because you wanna test then the performance of your stack, and you want to omit to use real data because of data privacy and licence restrictions. Thankfully, there is a group of developers out there which have created a creation tool called faker. Or should I say created a concept? Because it is implemented in various programming languages.
In this article, we will try out the faker implementations in NodeJS, Python and Ruby.
Why these languages? To be honest, I am not an expert with these languages, but these languages are known for being able to work on parallel processes and that's what we need! Because faker needs a lot of power for calculations and memory. We also need a fast hard drive, because we will work with files and that produces a lot of IO processes.
How much-falsified data does a man need?
That depends of course on your project. To measure changes in the performance between commit, I suggest using so many items that your test does not run longer than 10 minutes on average. But for a full integration test, you should use nearly the same amount + 10% as like you have later in production. My use case is that I need 20 million users, divided into CSV files with 10 thousand users in each file. That means at least, the outcome is 200 hundred files, 19 GB of test data. So let's get do it!
Parallel processes
Women are known to be capable of multitasking. Developer's best friend can do this too! My lovely Mac has 4 CPUs. That means we can run 4 processes of generating the fake data in parallel without overloading him. Here is an output from HTOP, which is an advanced version of top, the process monitor for the CLI. On the top left, you can see, that my for cores waiting for orders.
output from HTOP
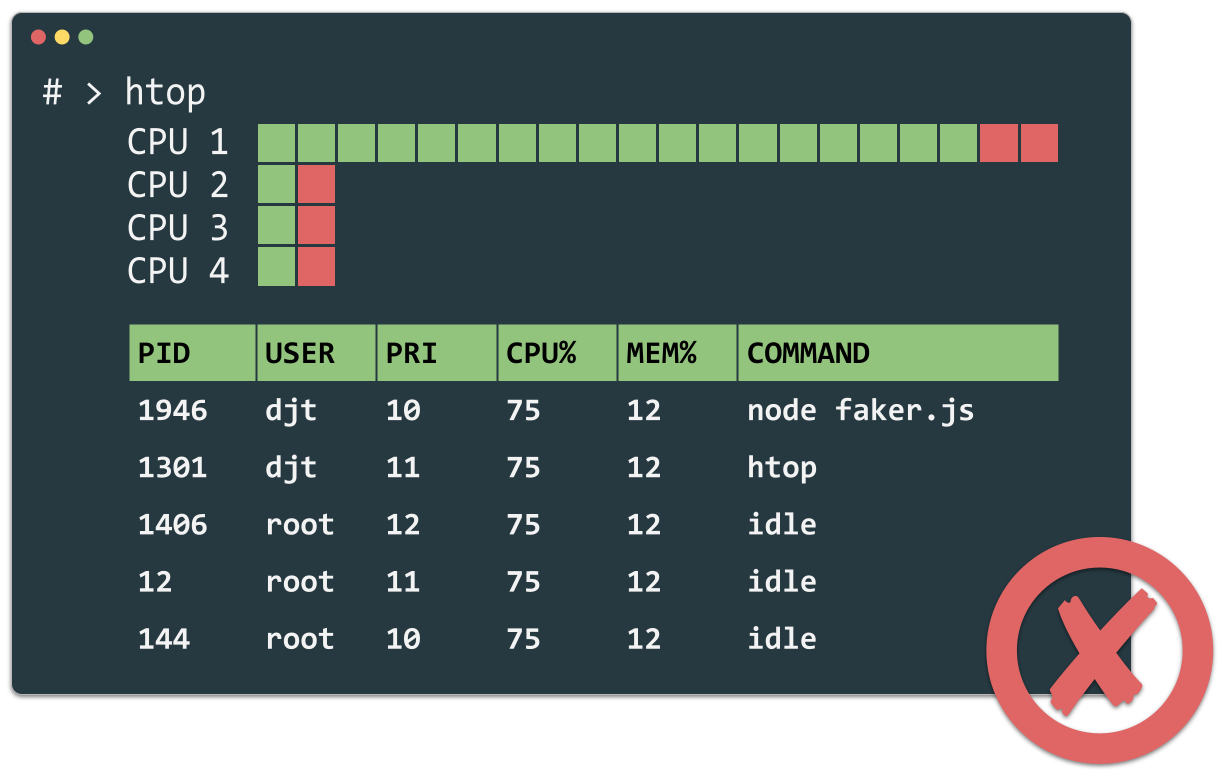 Wai Ting Loooooong!
Wai Ting Loooooong!
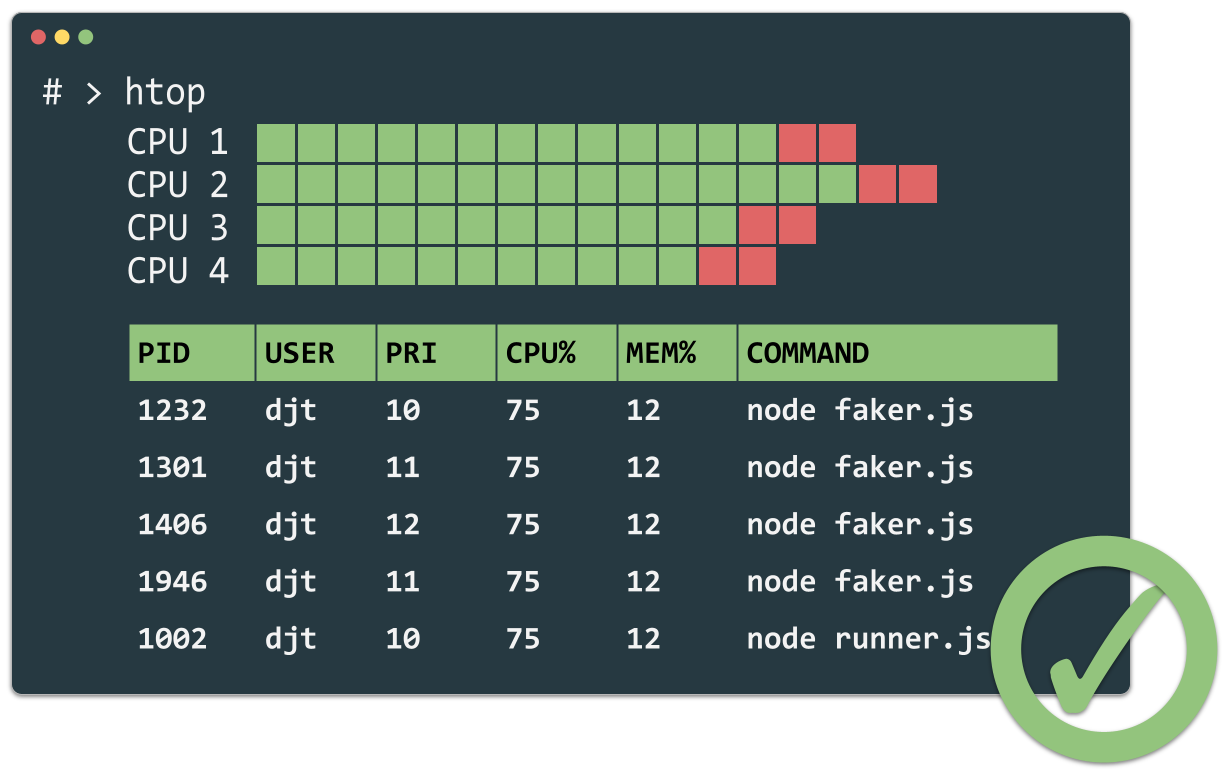 With parallel processes
With parallel processes
NodeJS
… is known to run asynchronously. But unfortunately not truly on parallel processes. In runs all in the same process, but asynchronous. The gives use not the benefit we want, with a high performance 12 core processors on board because JavaScript is a single-threaded language. We can use only one of them, except we work with child processes or workers! I could work with workers or child processes directly, but the library worker pool gives us a nice wrapper API to play around easily with the different techniques.
Worker types
With worker pool, you have the option to choose between the worker types process and thread. In case of 'process', child_process will be used. In case of 'thread', worker_threads will be used. I was curious to find out if child_process or worker_threads is better for generating test data. 1st test: 90,000 test users
In my first test 90000 test users are generated. They are distributed over 18 CSV files. Surprisingly for me, processes are a little bit faster than threads (child processes). But that already counts when you generate gigabytes of test data!
In my second test, I generated larger amounts of data. 5 million test users spread over 50 CSV files. So there are 100,000 test users in each file.
Fake it yourself!
You come so far now it's time to give it a try on your own! Checkout the repository:
Summary
Faker is an awesome concept. It is developed in many programming languages. In that cases, I tested the JavaScript version, and I am pretty happy with the outcome. Now I am curious how faker performs in other languages like Python, Ruby, PHP, Java or go! Sounds like a good contest to me :) Give it a try! With parallel processing, it was almost 4 times faster than on a single process in my tests. And child_processes are up to 5% faster than worker_threads. Download and try Download the example project, and try it on your machine!
Subscribe to my newsletter
Read articles from André Lademann directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
André Lademann
André Lademann
I am a developer from Europe - Germany, and I am interested in JavaScript, IoT and LoraWAN.