Geo-Distributed Microservices and Their Database: Fighting the High Latency
 Denis Magda
Denis Magda
Ahoy, mateys!
My development journey of the first version of the geo-distributed messenger has ended. So in this last article of the series, I’d like to talk about multi-region database deployment options that were validated for the messenger.
The high-level architecture of the geo-messenger is represented below:
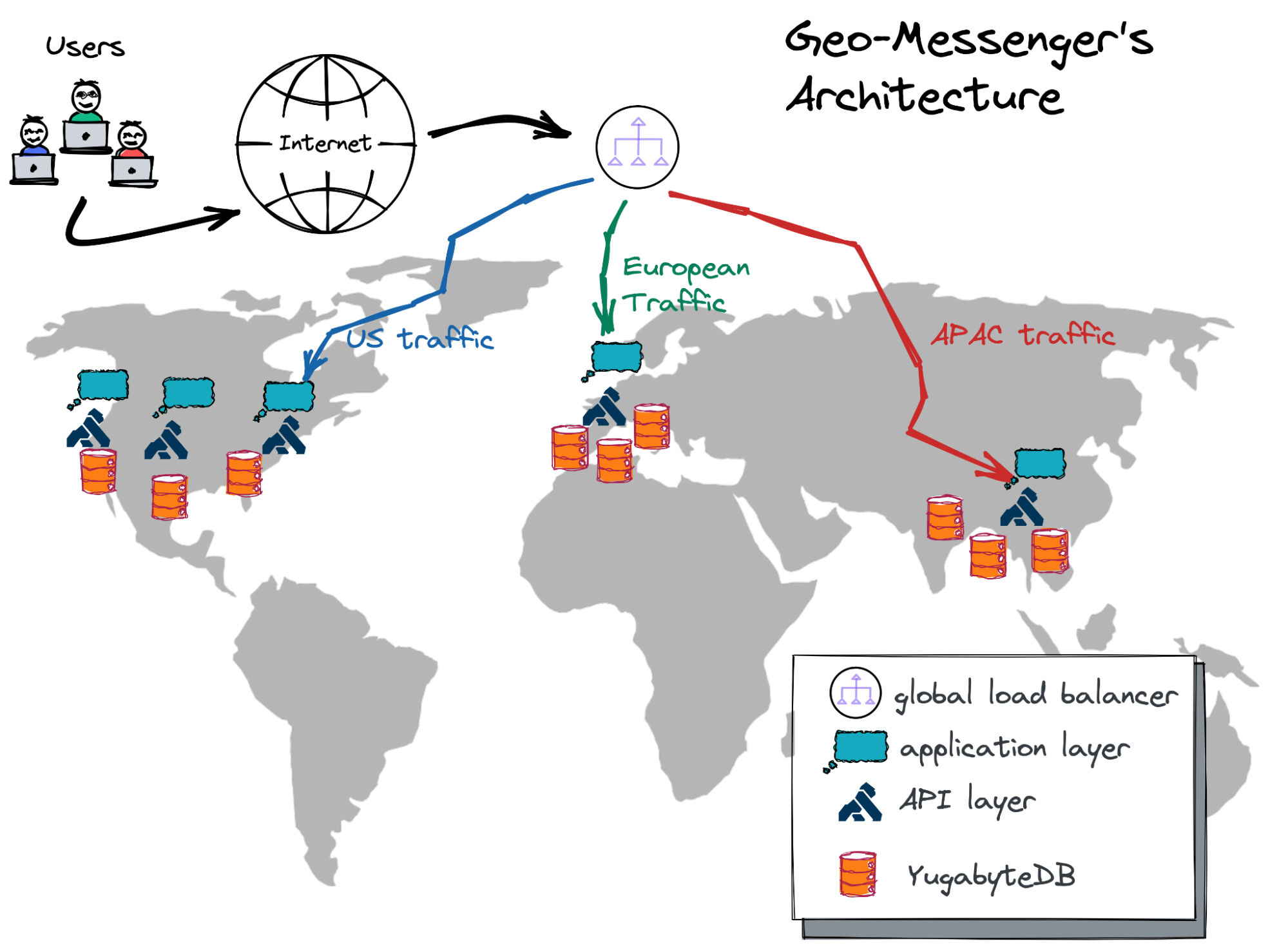
The microservice instances of the application layer are scattered across the globe in cloud regions of choice. The API layer, powered by Kong Gateway, lets the microservices communicate with each other via simple REST endpoints.
The global load balancer intercepts user requests at the nearest PoP (point-of-presence) and forwards the requests to microservice instances that are geographically closest to the user.
Once the microservice instance receives a request from the load balancer, it’s very likely that the service will need to read data from the database or write changes to it. And this step can become a painful bottleneck—an issue that you will need to solve if the data (database) is located far away from the microservice instance and the user.
In this article, I’ll select a few multi-region database deployment options and demonstrate how to keep the read and write latency for database queries low regardless of the user’s location.
So, if you’re still with me on this journey, then, as the pirates used to say, “Weigh anchor and hoist the mizzen!” which means, “Pull up the anchor and get this ship sailing!”
Multi-Region Database Deployment Options
There is no silver bullet for multi-region database deployments. It’s all about tradeoffs. Each option provides advantages, while others cost you something.
YugabyteDB, my distributed SQL database of choice, supports four multi-region database deployment options that are used by geo-distributed applications:
Single Stretched Cluster: The database cluster is “stretched” across multiple regions. The regions are usually located in relatively close proximity (e.g., US Midwest and East regions).
Single Stretched Cluster With Read Replicas: As with the previous option, the cluster is deployed in one geographic location (e.g., North America) across cloud regions in relatively close proximity (e.g., US Midwest and East regions). But with this option, you can add read replica nodes to distant geographic locations (e.g., Europe and Asia) to improve performance for read workloads.
Single Geo-Partitioned Cluster: The database cluster is spread across multiple distant geographic locations (e.g. North America, Europe, and Asia). Each geographic location has its own group of nodes deployed across one or more local regions in close proximity (e.g., US Midwest and East regions). Data is automatically pinned to a specific group of nodes based on the value of a geo-partitioning column. With this deployment option, you achieve low latency for both read and write workloads across the globe.
Multiple Clusters With Async Replication: Multiple standalone clusters are deployed in various regions. The regions can be located in relatively close proximity (e.g., US Midwest and East regions) or in distant locations (e.g., US East and Asia South regions). The changes are replicated asynchronously between the clusters. You will achieve low latency for both read and write workloads across the globe, the same as with the previous option, but you will deal with multiple standalone clusters that exchange changes asynchronously.
Alright, matey, let’s move forward and review the first three deployment options for the geo-messenger’s use case. I will skip the fourth one since it doesn’t fit the messenger’s architecture which requires a single database cluster.
Single Stretched Cluster in the USA
The first cluster spans three regions in the USA—US West, Central, and East.
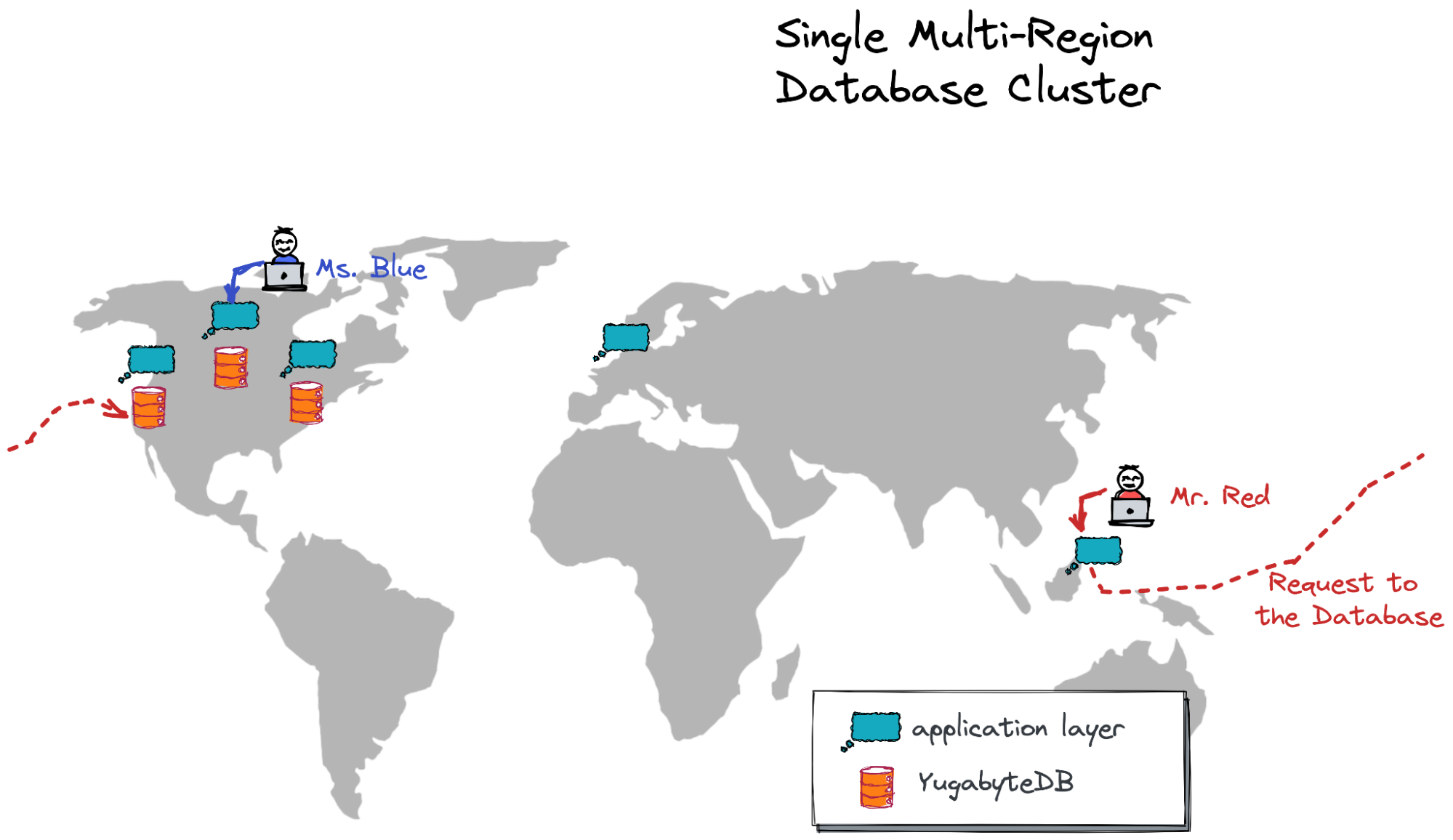
Application/microservice instances and the API servers (not shown in the picture) are running in those same locations plus in the Europe West and Asia East regions.
Database Read/Write Latency for the US Traffic
Suppose Ms. Blue is working from Iowa, US this week. She opens the geo-messenger to send a note to a corporate channel. Her traffic will be processed by the microservice instance deployed in the US Central region.
Before Ms. Blue can send the message, the US Central microservice instance has to load the channel’s message history. Which database node will be serving that read request?
In my case, the US Central region is configured as a preferred one for YugabyteDB, meaning a database node from that region will handle all the read requests from the application layer. It takes 10-15 ms to load the channel’s message history from that US Central database node to the application instance from the same region. Here is the output of my Spring Boot log with the last line showing the query execution time:
Hibernate: select message0_.country_code as country_1_1_, message0_.id as id2_1_, message0_.attachment as attachme3_1_, message0_.channel_id as channel_4_1_, message0_.message as message5_1_, message0_.sender_country_code as sender_c6_1_, message0_.sender_id as sender_i7_1_, message0_.sent_at as sent_at8_1_ from message message0_ where message0_.channel_id=? order by message0_.id asc
INFO 11744 --- [-nio-80-exec-10] i.StatisticalLoggingSessionEventListener : Session Metrics {
1337790 nanoseconds spent acquiring 1 JDBC connections;
0 nanoseconds spent releasing 0 JDBC connections;
1413081 nanoseconds spent preparing 1 JDBC statements;
14788369 nanoseconds spent executing 1 JDBC statements; (14 ms!)
Next, when Ms. Blue sends the message into the channel, the latency between the microservice and database will be around 90 ms. It takes more time than the previous operation because Hibernate generates multiple SQL queries for my JpaRepository.save(message) method call (which certainly can be optimized), and then YugabyteDB needs to store a copy of the message on all nodes running across the US West, Central, and East. Here is what the output and latency look like:
Hibernate: select message0_.country_code as country_1_1_0_, message0_.id as id2_1_0_, message0_.attachment as attachme3_1_0_, message0_.channel_id as channel_4_1_0_, message0_.message as message5_1_0_, message0_.sender_country_code as sender_c6_1_0_, message0_.sender_id as sender_i7_1_0_, message0_.sent_at as sent_at8_1_0_ from message message0_ where message0_.country_code=? and message0_.id=?
Hibernate: select nextval ('message_id_seq')
Hibernate: insert into message (attachment, channel_id, message, sender_country_code, sender_id, sent_at, country_code, id) values (?, ?, ?, ?, ?, ?, ?, ?)
31908 nanoseconds spent acquiring 1 JDBC connections;
0 nanoseconds spent releasing 0 JDBC connections;
461058 nanoseconds spent preparing 3 JDBC statements;
91272173 nanoseconds spent executing 3 JDBC statements; (90 ms)
Database Read/Write Latency for the APAC Traffic
Remember that with every multi-region database deployment there will be some tradeoffs. With the current database deployment, the read/write latency is low for the US-based traffic but high for the traffic originating from other, more distant locations. Let’s look at an example.
Imagine Mr. Red, a colleague of Ms. Blue, receives a push notification about the latest message from Ms. Blue. Since Mr. Red is on a business trip in Taiwan, his traffic will be handled by the instance of the app deployed on that island.
However, there is no database node deployed in or near Taiwan, so the microservice instance has to query the database nodes running in the US. This is why it takes 165 ms on average to load the entire channel’s history before Mr. Red sees the message of Ms. Blue:
Hibernate: select message0_.country_code as country_1_1_, message0_.id as id2_1_, message0_.attachment as attachme3_1_, message0_.channel_id as channel_4_1_, message0_.message as message5_1_, message0_.sender_country_code as sender_c6_1_, message0_.sender_id as sender_i7_1_, message0_.sent_at as sent_at8_1_ from message message0_ where message0_.channel_id=? order by message0_.id asc
[p-nio-80-exec-8] i.StatisticalLoggingSessionEventListener : Session Metrics {
153152267 nanoseconds spent acquiring 1 JDBC connections;
0 nanoseconds spent releasing 0 JDBC connections;
153217915 nanoseconds spent preparing 1 JDBC statements;
165798894 nanoseconds spent executing 1 JDBC statements; (165 ms)
When Mr. Red responds to Ms. Blue in the same channel, it takes about 450 ms for Hibernate to prepare, send, and store the message in the database. Well, thanks to the laws of physics, the packet(s) with the message has to travel through the Pacific Ocean from Taiwan, and then the message copy has to be stored across US West, Central, and East:
Hibernate: select message0_.country_code as country_1_1_0_, message0_.id as id2_1_0_, message0_.attachment as attachme3_1_0_, message0_.channel_id as channel_4_1_0_, message0_.message as message5_1_0_, message0_.sender_country_code as sender_c6_1_0_, message0_.sender_id as sender_i7_1_0_, message0_.sent_at as sent_at8_1_0_ from message message0_ where message0_.country_code=? and message0_.id=?
select nextval ('message_id_seq')
insert into message (attachment, channel_id, message, sender_country_code, sender_id, sent_at, country_code, id) values (?, ?, ?, ?, ?, ?, ?, ?)
i.StatisticalLoggingSessionEventListener : Session Metrics
23488 nanoseconds spent acquiring 1 JDBC connections;
0 nanoseconds spent releasing 0 JDBC connections;
137247 nanoseconds spent preparing 3 JDBC statements;
454281135 nanoseconds spent executing 3 JDBC statements (450 ms);
Now high latency for APAC-based traffic might not be a big deal for applications that don’t target users from the region, but that’s not so in my case. My geo-messenger has to function smoothly across the globe. Let’s fight this high latency, matey! We’ll start with the reads!
Deploying Read Replicas in Distant Locations
The most straightforward way to improve the latency for read workloads in YugabyteDB is by deploying read replica nodes in distant locations. This is a purely operational task that can be performed on a live cluster.
So, I “attached” a replica node to my live US-based database cluster, and that replica was placed in the Asia East region nearby the microservice instance that serves requests for Mr.Red.
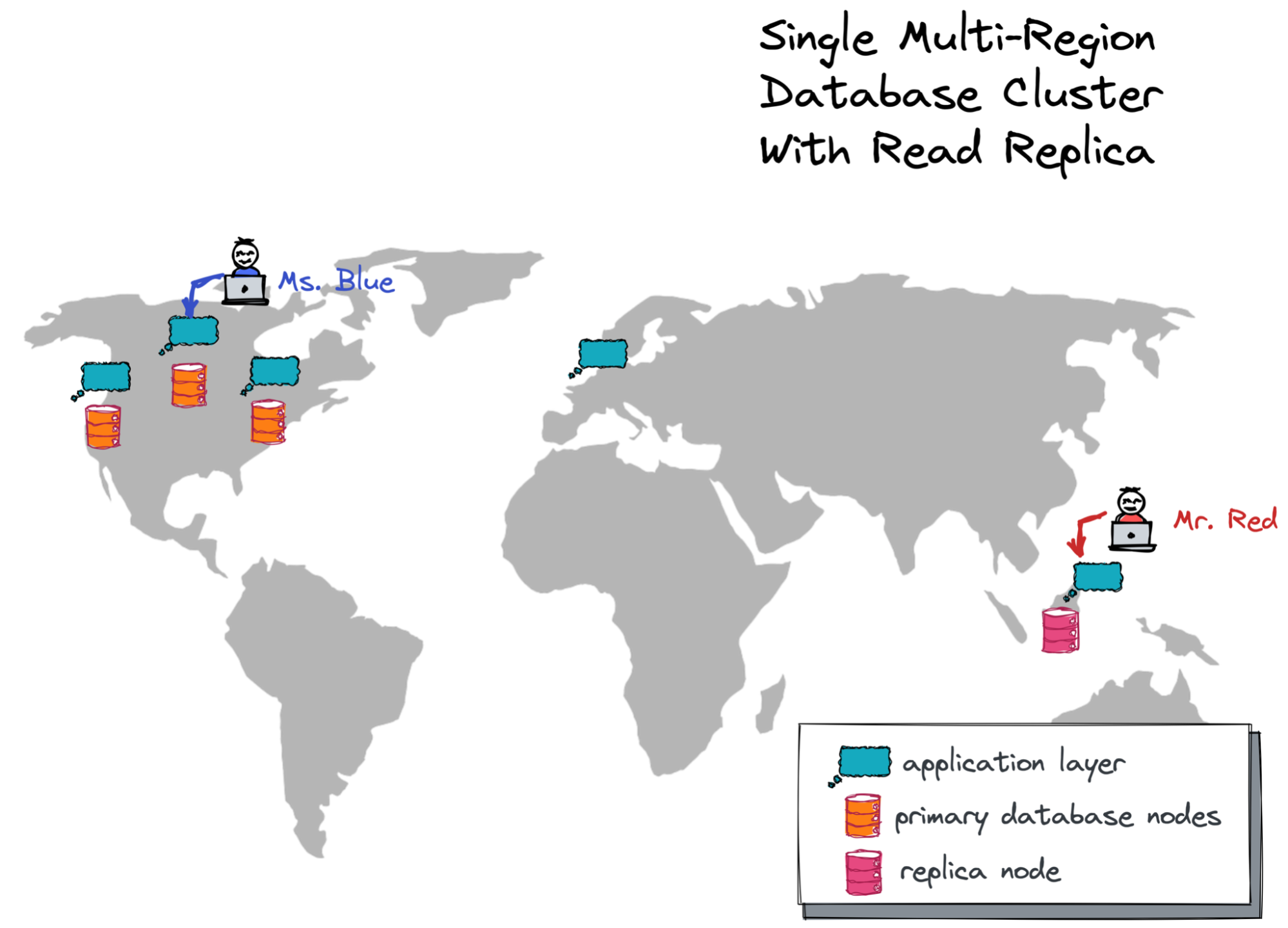
I then requested the application instance from Taiwan to use that replica node for database queries. The latency time for the channel’s history preloading for Mr.Red dropped from 165 ms to 10-15 ms! This is as fast as for Ms. Blue, who is based in the USA.
Hibernate: select message0_.country_code as country_1_1_, message0_.id as id2_1_, message0_.attachment as attachme3_1_, message0_.channel_id as channel_4_1_, message0_.message as message5_1_, message0_.sender_country_code as sender_c6_1_, message0_.sender_id as sender_i7_1_, message0_.sent_at as sent_at8_1_ from message message0_ where message0_.channel_id=? order by message0_.id asc
i.StatisticalLoggingSessionEventListener : Session Metrics
1210615 nanoseconds spent acquiring 1 JDBC connections;
0 nanoseconds spent releasing 0 JDBC connections;
1255989 nanoseconds spent preparing 1 JDBC statements;
12772870 nanoseconds spent executing 1 JDBC statements; (12 mseconds)
As a result, with read replicas, my geo-messenger can serve read requests at low latency regardless of the user’s location!
But it’s too soon for a celebration. The writes are still way too slow.
Imagine that Mr.Red sends another message to the channel. The microservice instance from Taiwan will ask the replica node to execute the query. And the replica will forward almost all requests generated by Hibernate to the US-based nodes that store primary copies of records. Thus, the latency still can be as high as 640 ms for the APAC traffic:
Hibernate: set transaction read write;
Hibernate: select message0_.country_code as country_1_1_0_, message0_.id as id2_1_0_, message0_.attachment as attachme3_1_0_, message0_.channel_id as channel_4_1_0_, message0_.message as message5_1_0_, message0_.sender_country_code as sender_c6_1_0_, message0_.sender_id as sender_i7_1_0_, message0_.sent_at as sent_at8_1_0_ from message message0_ where message0_.country_code=? and message0_.id=?
Hibernate: select nextval ('message_id_seq')
Hibernate: insert into message (attachment, channel_id, message, sender_country_code, sender_id, sent_at, country_code, id) values (?, ?, ?, ?, ?, ?, ?, ?)
i.StatisticalLoggingSessionEventListener : Session Metrics
23215 nanoseconds spent acquiring 1 JDBC connections;
0 nanoseconds spent releasing 0 JDBC connections;
141888 nanoseconds spent preparing 4 JDBC statements;
640199316 nanoseconds spent executing 4 JDBC statements; (640 ms)
At last, matey, let’s solve this issue once and for all!
Switching to Global Geo-Partitioned Cluster
A global geo-partitioned cluster can deliver fast reads and writes across distant locations but requires you to introduce a special geo-partitioning column to the database schema. Based on the value of the column, the database will automatically decide what database node in what geography a record belongs to.
Database Schema Changes
In a nutshell, my tables, such as the Message one, define the country_code column:
CREATE TABLE Message(
id integer NOT NULL DEFAULT nextval('message_id_seq'),
channel_id integer,
sender_id integer NOT NULL,
message text NOT NULL,
attachment boolean NOT NULL DEFAULT FALSE,
sent_at TIMESTAMP NOT NULL DEFAULT NOW(),
country_code varchar(3) NOT NULL
) PARTITION BY LIST (country_code);
Depending on the value of that column, a record can be placed in one of the following database partitions:
CREATE TABLE Message_USA
PARTITION OF Message
(id, channel_id, sender_id, message, sent_at, country_code, sender_country_code,
PRIMARY KEY(id, country_code))
FOR VALUES IN ('USA') TABLESPACE us_central1_ts;
CREATE TABLE Message_EU
PARTITION OF Message
(id, channel_id, sender_id, message, sent_at, country_code, sender_country_code,
PRIMARY KEY(id, country_code))
FOR VALUES IN ('DEU') TABLESPACE europe_west3_ts;
CREATE TABLE Message_APAC
PARTITION OF Message
(id, channel_id, sender_id, message, sent_at, country_code, sender_country_code,
PRIMARY KEY(id, country_code))
FOR VALUES IN ('TWN') TABLESPACE asia_east1_ts;
Each partition is mapped to one of the tablespaces:
CREATE TABLESPACE us_central1_ts WITH (
replica_placement='{"num_replicas": 1, "placement_blocks":
[{"cloud":"gcp","region":"us-central1","zone":"us-central1-b","min_num_replicas":1}]}'
);
CREATE TABLESPACE europe_west3_ts WITH (
replica_placement='{"num_replicas": 1, "placement_blocks":
[{"cloud":"gcp","region":"europe-west3","zone":"europe-west3-b","min_num_replicas":1}]}'
);
CREATE TABLESPACE asia_east1_ts WITH (
replica_placement='{"num_replicas": 1, "placement_blocks":
[{"cloud":"gcp","region":"asia-east1","zone":"asia-east1-b","min_num_replicas":1}]}'
);
And each tablespace belongs to a group of database nodes from a particular geography. For instance, all the records with the country code of Taiwan (country_code=TWN) will be stored on cluster nodes from the Asia East cloud region because those nodes hold the partition and tablespace for the APAC data. Check out the following article if you want to learn the details of geo-partitioning.
Low Read/Write Latency Across Continents
So, I deployed a three-node geo-partitioned cluster across the US Central, Europe West, and Asia East regions.
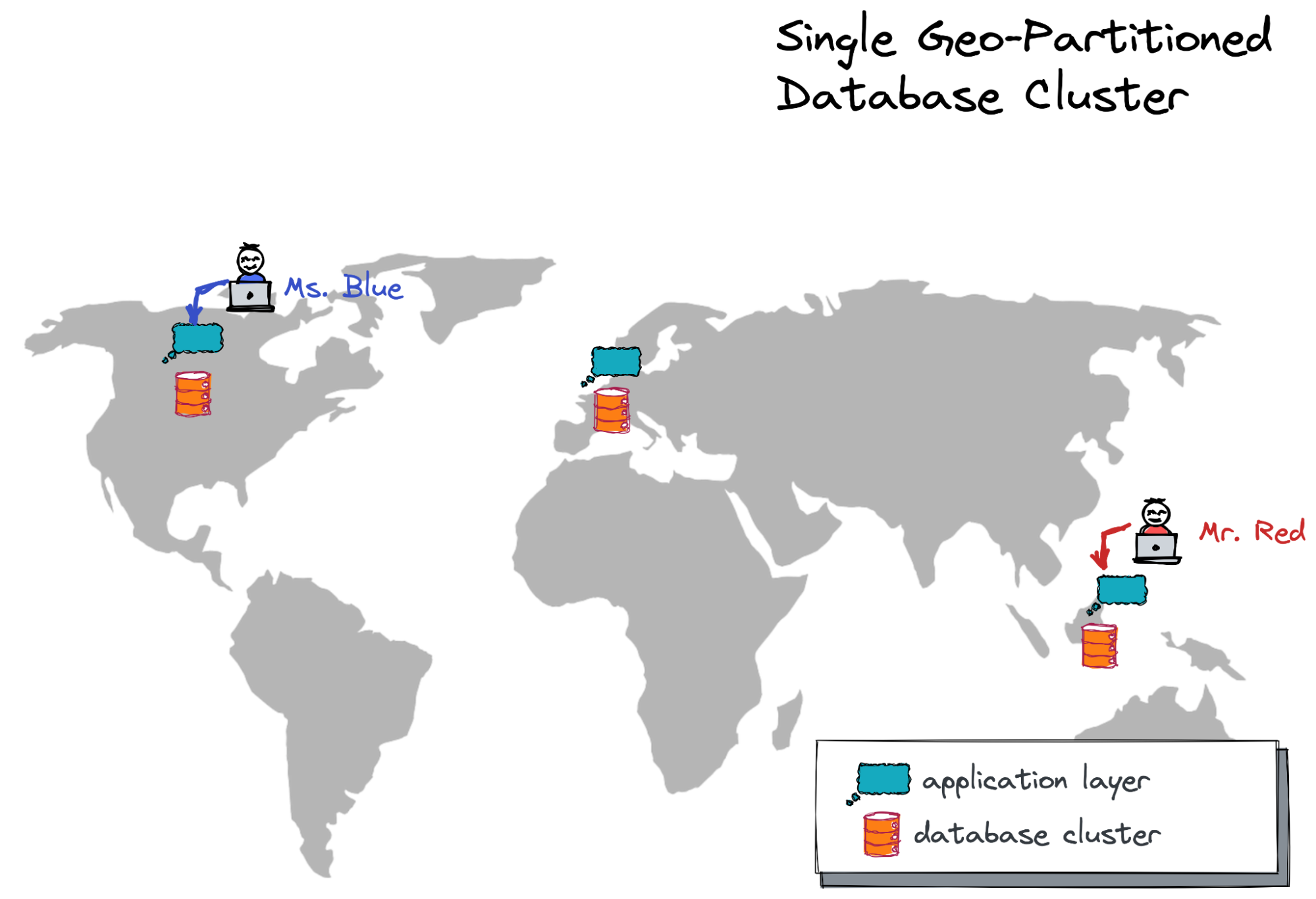
Now, let's ensure that the read latency for Mr. Red's requests remains intact. As with the read replica deployment, it still takes 5-15 ms to load the channel's message history (for the channels and messages belonging to the APAC region):
Hibernate: select message0_.country_code as country_1_1_, message0_.id as id2_1_, message0_.attachment as attachme3_1_, message0_.channel_id as channel_4_1_, message0_.message as message5_1_, message0_.sender_country_code as sender_c6_1_, message0_.sender_id as sender_i7_1_, message0_.sent_at as sent_at8_1_ from message message0_ where message0_.channel_id=? and message0_.country_code=? order by message0_.id asc
i.StatisticalLoggingSessionEventListener : Session Metrics
1516450 nanoseconds spent acquiring 1 JDBC connections;
0 nanoseconds spent releasing 0 JDBC connections;
1640860 nanoseconds spent preparing 1 JDBC statements;
7495719 nanoseconds spent executing 1 JDBC statements; (7 ms)
And…drumroll please….when Mr. Red posts a message into an APAC channel, the writes latency has dropped from 400-650 ms to 6 ms on average!
Hibernate: select message0_.country_code as country_1_1_0_, message0_.id as id2_1_0_, message0_.attachment as attachme3_1_0_, message0_.channel_id as channel_4_1_0_, message0_.message as message5_1_0_, message0_.sender_country_code as sender_c6_1_0_, message0_.sender_id as sender_i7_1_0_, message0_.sent_at as sent_at8_1_0_ from message message0_ where message0_.country_code=? and message0_.id=?
Hibernate: select nextval ('message_id_seq')
Hibernate: insert into message (attachment, channel_id, message, sender_country_code, sender_id, sent_at, country_code, id) values (?, ?, ?, ?, ?, ?, ?, ?)
1123280 nanoseconds spent acquiring 1 JDBC connections;
0 nanoseconds spent releasing 0 JDBC connections;
123249 nanoseconds spent preparing 3 JDBC statements;
6597471 nanoseconds spent executing 3 JDBC statements; (6 ms)
Mission accomplished, matey! Now my geo-messenger’s database can serve reads and writes with low latency across countries and continents. I just need to tell my messenger where to deploy microservice instances and database nodes.
The Case for Cross-Continent Queries
Now for a quick comment on why I skipped the database deployment option with multiple standalone YugabyteDB clusters.
It was important to me to have a single database for the messenger so that:
- Users could join discussion channels belonging to any geography.
- Microservice instances from any location could access data in any location.
For instance, if Mr. Red joins a discussion channel belonging to the US nodes (country_code=’USA') and sends a message there, the microservice instance from Taiwan will send the request to the Taiwan-based database node and that node will forward the request to the US-based counterpart. The latency for this operation is comprised of three SQL requests and will be around 165 ms:
Hibernate: select message0_.country_code as country_1_1_0_, message0_.id as id2_1_0_, message0_.attachment as attachme3_1_0_, message0_.channel_id as channel_4_1_0_, message0_.message as message5_1_0_, message0_.sender_country_code as sender_c6_1_0_, message0_.sender_id as sender_i7_1_0_, message0_.sent_at as sent_at8_1_0_ from message message0_ where message0_.country_code=? and message0_.id=?
Hibernate: select nextval ('message_id_seq')
Hibernate: insert into message (attachment, channel_id, message, sender_country_code, sender_id, sent_at, country_code, id) values (?, ?, ?, ?, ?, ?, ?, ?)
i.StatisticalLoggingSessionEventListener : Session Metrics
1310550 nanoseconds spent acquiring 1 JDBC connections;
0 nanoseconds spent releasing 0 JDBC connections;
159080 nanoseconds spent preparing 3 JDBC statements;
164660288 nanoseconds spent executing 3 JDBC statements; (164 ms)
165 ms is undoubtedly higher than 6 ms (the latency when Mr. Red posts a message into a local APAC-based channel), but what’s important here is the ability to make cross-continent requests via a single database connection when necessary. Plus, as the execution plan shows, there is a lot of room for optimization at the Hibernate level. Presently, Hibernate translates my JpaRepository.save(message) call into 3 JDBC statements. This is what can be optimized further to bring down the latency for the cross-continent requests from 165 ms to a much lower value.
Wrapping Up
Alright, matey!
As you see, distributed databases such as YugabyteDB can function seamlessly across geographies. You need to pick a deployment option that works best for your application. In my case, the geo-partitioned YugabyteDB cluster fits the most for the messenger's requirements.
Well, this article ends the series about my geo-messenger's development journey. The application source code is available on GitHub so that you can explore the logic and run the app in your environment.
Next, I'll take a little break and then start preparing for my upcoming SpringOne session that will feature the geo-messenger's version running on Spring Cloud components. So, if it's relevant to you, follow me to get notified about future articles related to Spring Cloud and geo-distributed apps.
Subscribe to my newsletter
Read articles from Denis Magda directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Denis Magda
Denis Magda
Learned Java from the inside while developing JVM & JDK for years. Then joined the world of distributed systems and databases, where remained ever since.