Optimize and run your data pipeline with Scramjet
 Fiifi Baidoo
Fiifi Baidoo
No matter how innovative, all businesses need to analyze data to extract insights and make fair decisions. The process starts with the data engineer. Data engineers ensure that collected data is appropriately stored and managed. If information isn’t handled correctly, it can go to waste or be misused.
What is Data Engineering?
Data engineering is the process of transforming data into a format that can be easily consumed by data analysis and data visualization tools. It involves tasks such as data cleaning, data transformation, and data loading. To be a successful data engineer, you must know how to code and have experience working with large quantities of data. It would help if you also had significant experience working with large data sets and optimizing data pipeline performance.
Tasks of a data engineer
Building data pipelines is the primary job of a data engineer, and there are not enough engineers to meet the demand. Data engineers often construct pipelines to enable data to travel from its starting point to its destination, though there are usually a few steps in between. Every data pipeline has four key stages: ingestion, storage, processing, and visualization.
To optimize data pipeline performance, data engineers need to be skilled in data cleaning and transformation, have experience in data analysis and visualization tools, and understand the importance of data management.
Data engineers also need to ensure that data is accurate and adequately stored in data warehouses for later analysis. They must also be able to manage large data sets efficiently. Additionally, they must work closely with other department team members to ensure everyone is aligned on data processing goals and timelines.
Data Pipelines
Data pipelines are a series of transformations that take data from its raw form to a final format easily consumed by data analysis and data visualization tools. Data engineers must understand the importance of pipeline performance optimization.
The example above is rather complex; we can transfer big data into a more comprehensive analytics system. For example, you can import and stream structured and unstructured data into Google Cloud Storage and PubSub.
Multiple logs from different systems can be collected in real-time, aggregated, and analyzed later. Examples of such systems could be medical devices, solar panels, and data from IoT sensors. And data scientists can use data pipelines to run data analysis tasks such as machine learning and data mining on large data sets.
Data warehouses and data lakes
Data warehouses are data storage systems that consolidate data from many sources, providing a single data source for data analysis. A data warehouse contains structured and unstructured data. Structured data has a specific format that is easy to understand, while processed data may have been transformed to be stored in its structured place. Although data warehouses have many benefits, one downside is that their structures can sometimes be very rigid. This can make any data format changes quite tricky and time-consuming.
BigQuery is a data warehouse service that stores and retrieves data quickly and easily. BigQuery can automatically detect schema changes in your data and update the corresponding fields in your data warehouse accordingly.
Data lakes are similar to data warehouses, but they do not act as a central data repository or undergo the same level of processing and cleaning. Data lakes are frequently included in data warehouse solutions. They can store data that is not yet ready for data warehouses, such as data from IoT sensors or data collected in real-time. Data lakes act as storage spaces for large amounts of unrefined data. This is useful for data engineers who must rapidly access various data types for analysis or machine learning processes.
Challenges & benefits of running data pipelines
Data pipelines are a critical part of data engineering, but they can be challenging to set up and manage. They offer many benefits, including improved data processing speed and accuracy.
Running an enterprise data warehouse is a time-consuming process. Data warehouses don't typically support machine learning and AI initiatives directly. To use other services or products, customers must renew licenses and provision new hardware, which is costly and complex. Traditional data warehouses are hard to manage and operate. They were designed for a batch paradigm of data analytics and operational reporting needs.
One of the biggest challenges faced by data engineers is organizing data into a consistent, efficient pipeline that can run smoothly and produce meaningful results. Data needs to be collected from various sources, sorted and cleaned, and then moved into a data warehouse where it can be analyzed using multiple analytical tools. Without proper management, data pipelines can become slow or unreliable, resulting in inaccurate or incomplete data.
But with the right data pipeline management tools and strategies, data engineers can overcome these challenges. They can build data pipelines optimized for speed and accuracy, ensuring that data is always accessible and reliable when needed. Additionally, data engineers can work more efficiently by taking advantage of data processing platforms like Scramjet.
Some Tools for Building and Running Data Pipelines
Cloud Data Fusion makes creating and overseeing data pipelines simple using its code-free, fully managed data integration with a user-friendly interface.
PipelineWise by Transfer Wise is an open-source data pipeline tool that can transfer data from multiple databases to various destinations. Unlike other Extract Transform Load (ETL) tools, PipelineWise focuses on Extract Load Transform (ELT) and strives to keep the data in its original format as much as possible when replicating it from the source to an Analytics-Data-Store. While some minor load time transformations are supported, complex mapping and joins usually have to be done in the Analytics-Data-Store to make sense of the data.
Data Pipeline by Amazon Web Services (AWS) is a fully managed data processing web service that makes it easy to process and move data between different AWS compute and storage services and on-premises data sources at specified intervals. With Data Pipeline, data engineers can regularly access, transform and process data at scale in the cloud without having to provision or manage any infrastructure. The results can be efficiently transferred to AWS services such as Amazon S3, Amazon RDS, Amazon DynamoDB, and Amazon EMR.
Scramjet in data engineering
Some data engineers have computer science, data science, or data analytics backgrounds. However, many data engineers are self-taught and have skills in various data engineering tools and techniques. One data processing platform that can help optimize your data pipeline is Scramjet. With its robust framework and transform hub, Scramjet makes it easy to process and analyze data sets in real time.
Scramjet is a powerful tool that can help data engineers run and streamline their pipelines (Transform as a Service) without wasting time on monotonous integrations. With its robust framework and transform hub, Scramjet makes it easy to process and analyze large data sets in (near) real time. With Scramjet you can choose to Extract Load and Transform or Extract Transform and Load to and from various database sources.
Scramjet allows data engineers to optimize pipelines and extract meaningful insights from data. With Scramjet, data engineers can access features like distributed computing and data storage across multiple environments. Additionally, Scramjet allows data engineers to run programs in various programming languages simultaneously through an API, enabling them to analyze data quickly and extract insights.
Scramjet's cross-native approach to cloud and edge computing provides native efficiency regardless of the environment or programming language. Consequently, Scramjet will allow data transformation services to run uninterrupted between endpoint devices (smartphones, drones, measuring devices) on 5G networks and private servers or between private and public clouds.
You can process data even on a Raspberry Pi, using a self-hosted version of the Scramjet Transform Hub. Scramjet is ideal for local processing, edge and IoT applications. Machine learning on the edge is challenging to do without the proper resources. Data that might be too complex to process locally can be transformed into a suitable format and sent to the cloud, where you can access more computing resources and then be updated and pushed back to the edge.
Using the Scramjet data transformation platform, you can easily connect various parts necessary for constructing a data pipeline. The Scramjet platform makes this process easier and more efficient by consolidating all aspects of the pipeline, like data acquisition from IoT sensors. Google Cloud Platform, for instance, can't process your data until it's already uploaded to a data warehouse like BigQuery; Scramjet can take care of getting it there so you can use all its other capabilities.
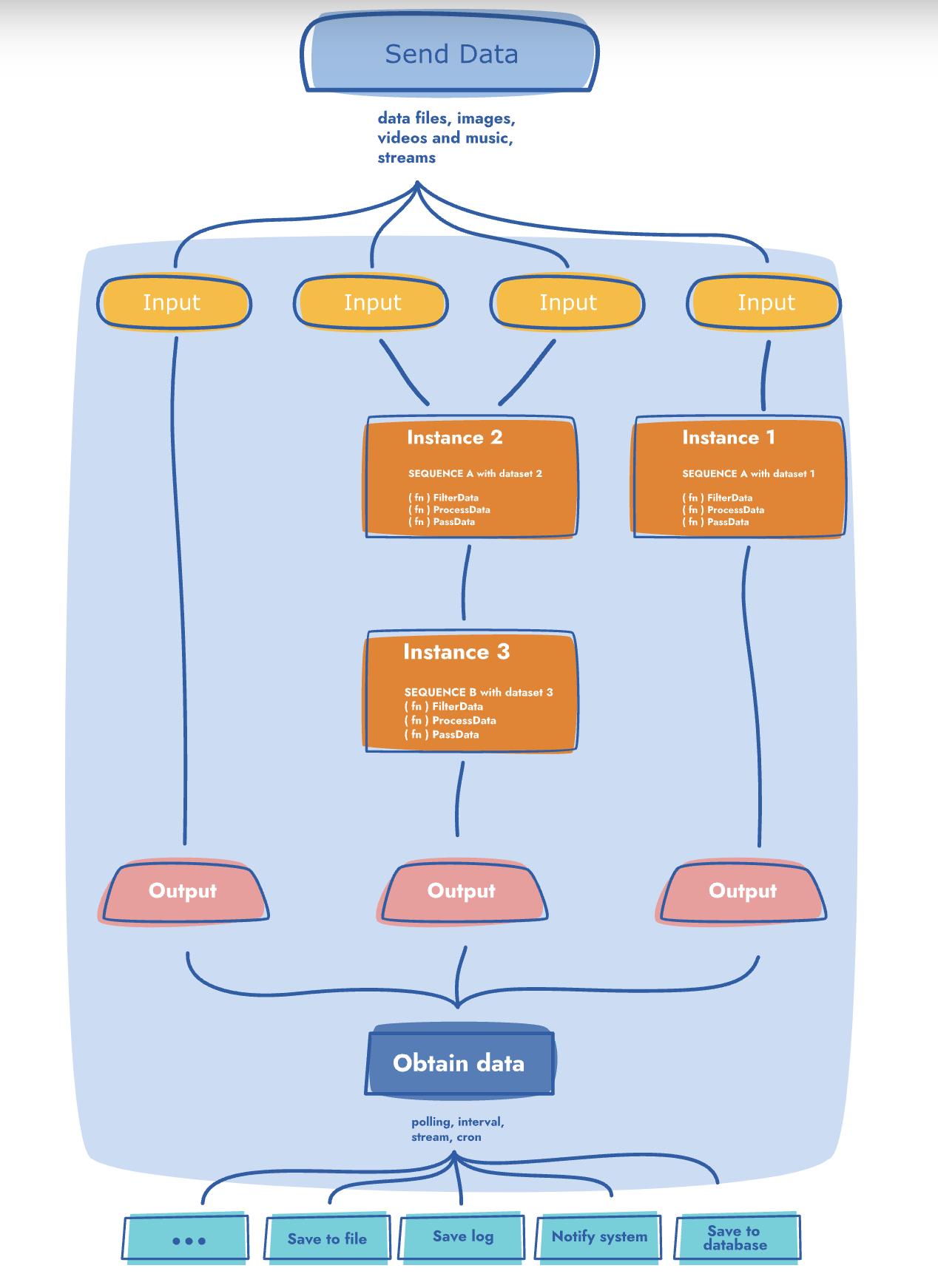
The Scramjet Cloud Platform can handle any data imaginable, as shown in the diagram above. To give you a better idea, here's how it works: anything that goes into the input (file, image, stream, movie) will be processed by an Instance. They have run the same Sequence multiple times, meaning they've started the sequence (labelled "SEQUENCE A" in the diagram) three times, twice with the same dataset.
The fourth Instance was deployed using "SEQUENCE B", which uses an external API for its transformation data input. This can create different containers for each Instance with diverse and secure environments. The scalability feature of Scramjet Transform Hub (STH) is one of its many functional strengths.
The transformed data can be saved to a database or file or passed on to another instance for further transformation. It's up to you what you do with the data. The potential is immeasurable.
Network latency and transport costs can be minimised by ensuring that Scramjet worker instances execute pipeline tasks in the same region as data sources, syncs, and staging locations. The ability to distribute workloads across different geographic regions adds to overall resiliency. It can be an excellent idea if data needs to be processed in near-real-time when data sources are geographically widespread.
Conclusion
First and foremost, practising hands-on data engineering and transformation is how to build your Scramjet skills. You can use the data processing platform to connect various parts necessary for constructing a data transformation pipeline. The Scramjet platform makes this process easier and more.
So if you don't have a Scramjet account yet, go to https://scramjet.org/#join-beta, sign up, and get an account for beta testing. I would suggest getting that account set up immediately.
Subscribe to my newsletter
Read articles from Fiifi Baidoo directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Fiifi Baidoo
Fiifi Baidoo
I am a Google Cloud Certified Professional with many years of experience designing and deploying cloud-native applications. I have worked on projects for companies in different industries, including finance, healthcare, retail, logistics & transport--and more! My favourite part about my job is that each project has its own unique set of challenges which keep me engaged as an architect and engineer all day long