How to query for data in Neo4j
 Anders Kirkeby
Anders Kirkeby
In this post we will explore how to execute queries in Neo4j, the popular graph database, and retrieve nodes and edges to answer a few questions. We will use the default movies database from the Neo4j team as our model, construct Cypher-queries to answer questions about the movies and actors and so forth.
Who is this intended for
This post is aimed at developers who are either just getting their feet wet with Cypher and Neo4j, or already have a good understanding and is looking for some quick tips or code references.
We will go over the basic components of constructing Cypher-queries, and concepts of:
- How to MATCH nodes
- Make queries more flexible using OPTIONAL MATCH
- Filtering results using the WHERE-operator
- Aggregate functions like the COUNT-function
- Sorting results with ORDER BY
- Combining properties in lists using COLLECT
Prerequisites for following along
- Basic knowledge of the Cypher language (though beginners should do fine)
- Basic knowledge on how to interact with Neo4j via the Neo4j Desktop client
- A working instance of Neo4j desktop with Neo4j's movies database installed
First look a the movies graph
To get started, let's have a look at what our vanilla graph looks like. To do this, we will match all nodes and return them.
MATCH (n) return n
This will return all the nodes and relationships in the graph, and should look something like the below screenshot. Here all the movies are represented by the yellow nodes and the people involved are represented by the blue nodes. Between them are directional edges on the describing the relationship.
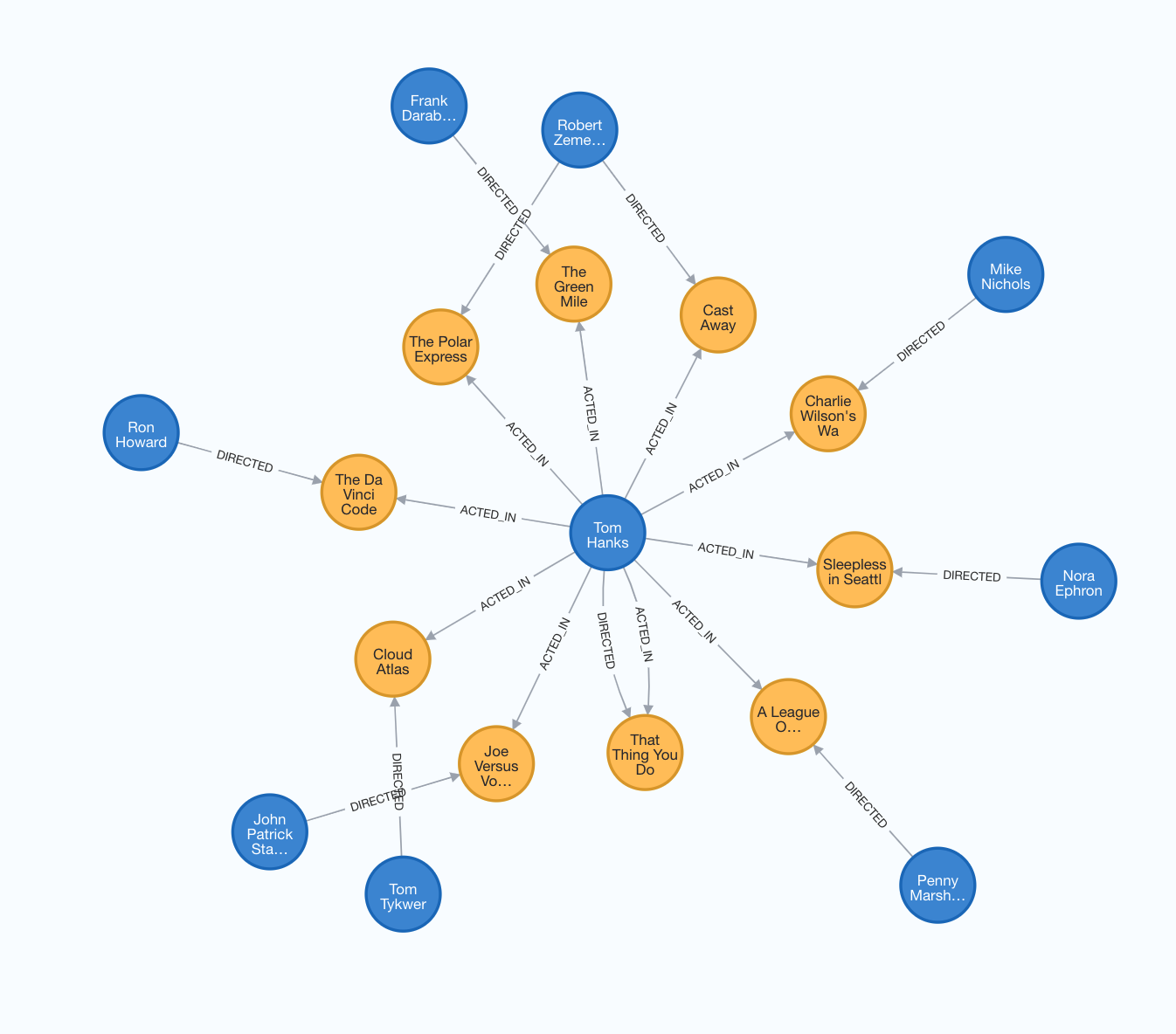
From here we can ask and have answered a few basic questions using Cyphers built-in aggregate and filtering functions. If we would like to get only the movie nodes, we could do:
// Get all movie nodes
MATCH (m:Movie) RETURN m

Now, if we wanted to know how many movies that is, we could use the COUNT function on the same set of nodes, like so:
// Count of movie nodes
MATCH (m:Movie) RETURN COUNT(m)
The result is returned to us in table-format in stead of nodes as before:

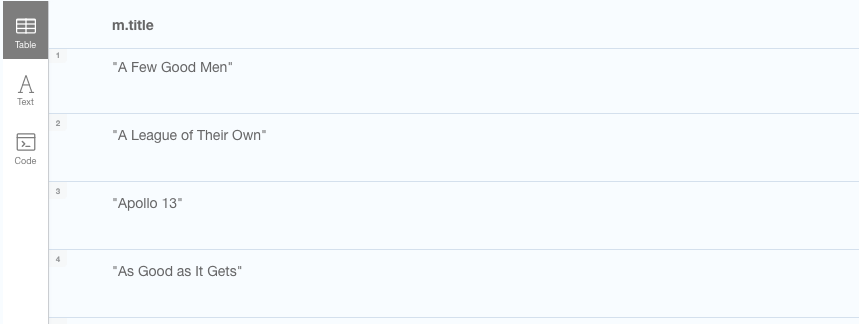
If we instead, wanted to list all the movies titles sorted by title, we would use the ORDER BY function, same as we would in a relations SQL statement:
// Get movie titles sorted alphabetically
MATCH (m:Movie) RETURN m.title ORDER BY m.title
// Or to sort descending
MATCH (m:Movie) RETURN m.title ORDER BY m.title DESC
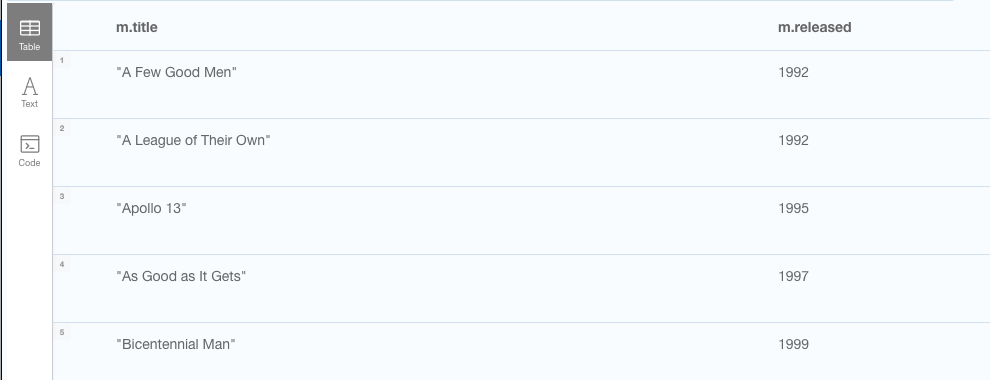
Since moves have properties like released, we might want to also print the year out.
// Get movie with title, tagline and publish year
MATCH (m:Movie)
RETURN m.title, m.released
ORDER BY m.title
 Add as many properties as you need by appending to return statement.
Add as many properties as you need by appending to return statement.
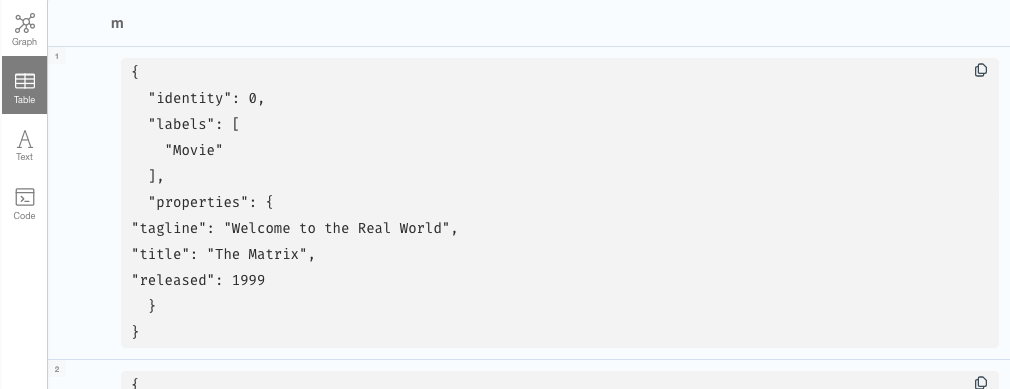
We can get an idea of how may properties a single move has by selecting it a switching to tabular-view:
// Get movie
MATCH (m:Movie) RETURN m
Expanding a bit
Now let's add a bit more information to our queries by combining info about the movies and the people involved in making the movie.
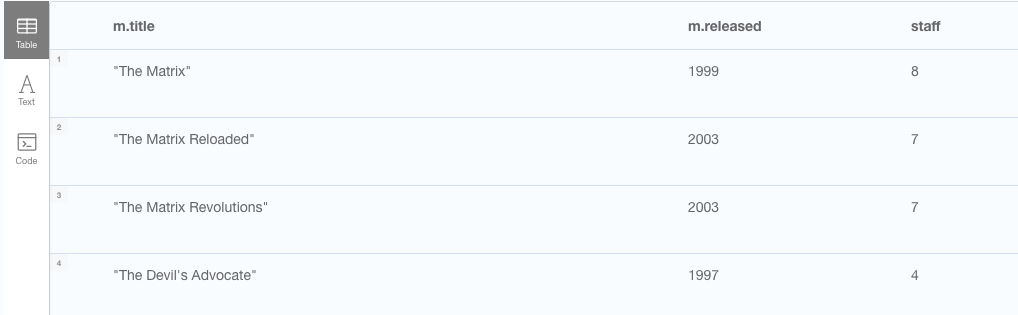
Here we use the directional edge to indicate that we would like nodes directly attached to the movie, and that the connected node must be of label Person, which we assign the letter p. We then use the COUNT function to count the number of p's, or persons, related to any given movie. We are also naming the column with result of count(p) to staff.
// Get movie titles, published year and count of people involved
MATCH (m:Movie)<--(p:Person)
RETURN m.title, m.released, count(p) as staff
Now, in this dataset all movies have people involved, and we can verify this by looking for the non-existence of a pattern
// Get movie without relationships to persons
MATCH (m:Movie)
WHERE NOT EXISTS((m)<--(:Person))
RETURN m

Okay, all movies have persons attached, but not all movies have people reviewing them, so let's use the same query to count the persons reviewing each movie and order the result by number of reviewers. Movies with zero reviewers will be included in the result, made possible by the OPTIONAL keyword
// Get movies and a count of how many reviewers they have
MATCH (m:Movie)-[:REVIEWED]-(p:Person)
RETURN m.title, m.released, count(p) as reviewers
ORDER BY reviewers desc
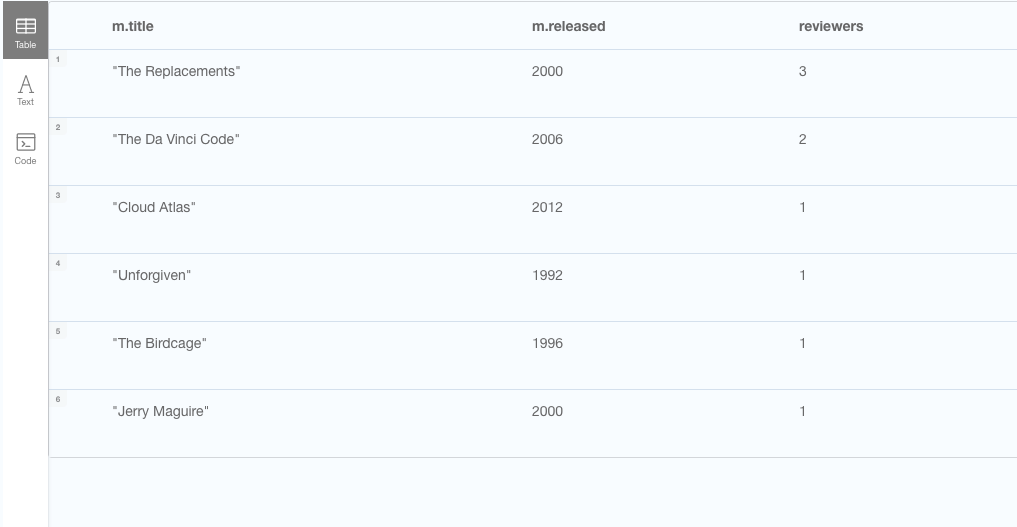 Pretty good, but where are all the movies with no reviews? To include those we need to modify our query a bit and add an OPTIONAL MATCH criterion.
Pretty good, but where are all the movies with no reviews? To include those we need to modify our query a bit and add an OPTIONAL MATCH criterion.
// Make it optional to have any reviewers on record
MATCH (m:Movie)
OPTIONAL MATCH (m)<-[:REVIEWED]-(p:Person)
RETURN m.title, m.released, count(p) as reviewers
ORDER BY reviewers desc
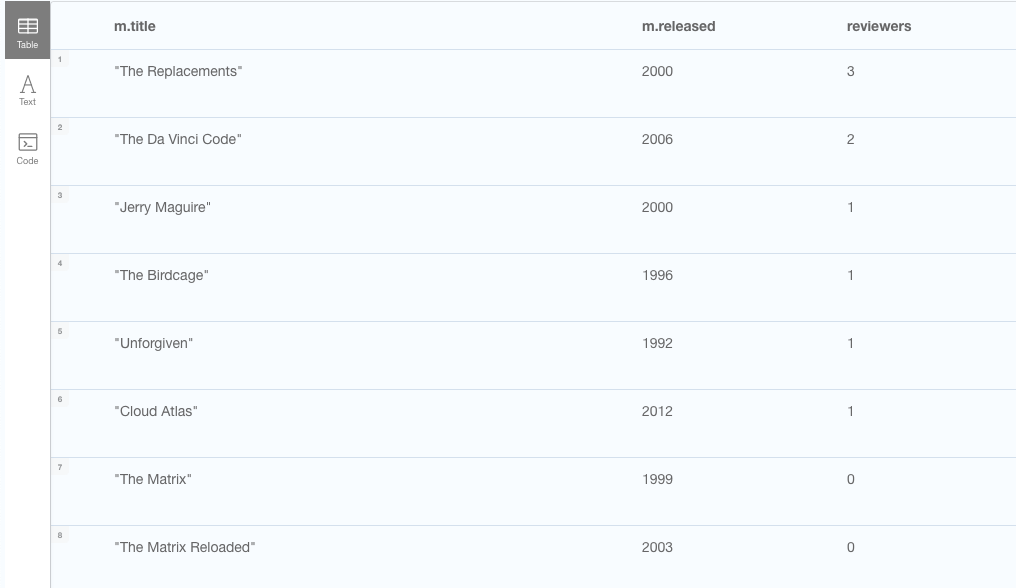 Better, now we have the full liste of movies with a an optional count of how many reviewers each have, allowing for movies with zero reviewers.
Better, now we have the full liste of movies with a an optional count of how many reviewers each have, allowing for movies with zero reviewers.
Before wrapping up, let's do a few searches on titles and published years. Let's see if we can get all the moves published in 1999. For this we use the WHERE clause, same as in plain ol´ relational SQL.
// Get movies published in 1999
MATCH (m:Movie)
WHERE m.released = 1999
RETURN m.title, m.released
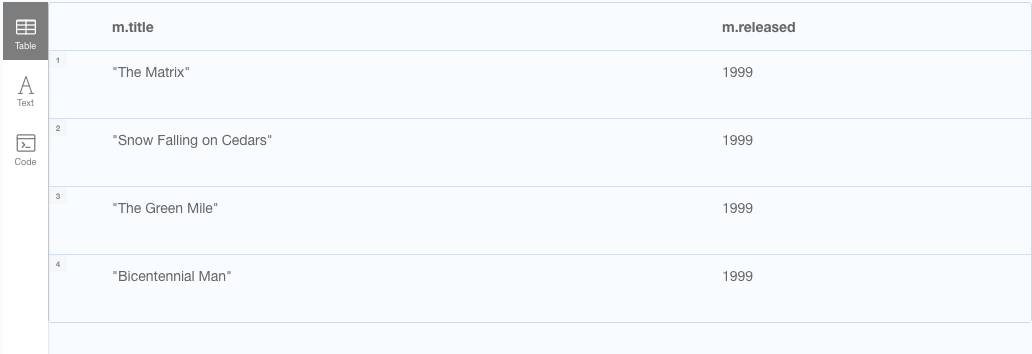
Nice, so what if we need an account of how many movies were released in each year? Again we can turn to the COUNT-function, but instead of selecting the title first, we select the year of the movie and then count the movies for each year.
// How many movies were released in each year?
MATCH (m:Movie)
RETURN m.released, COUNT(m)
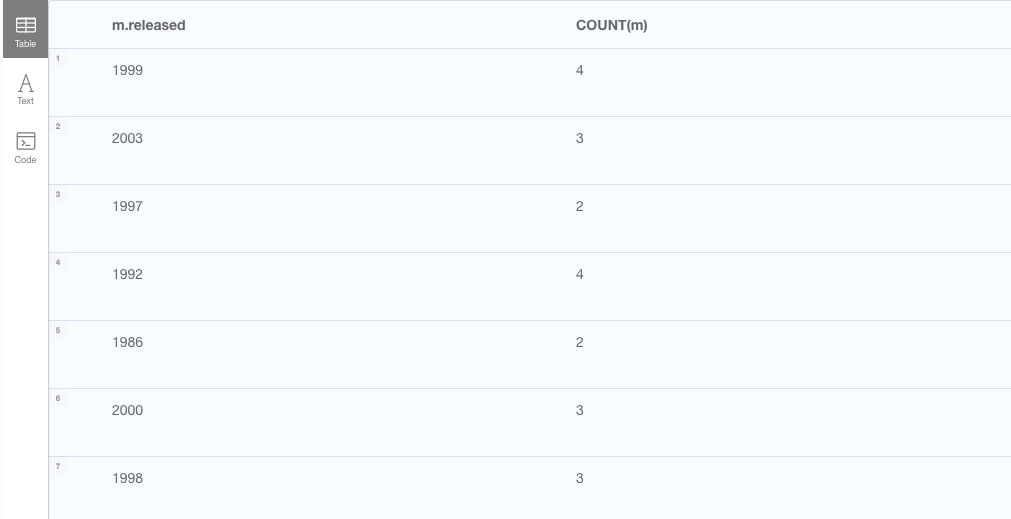 Ok, great, but what if we need the titles of the movies instead of the count? For that we can use the COLLECT-operator, which gathers a property from each node into a list.
Ok, great, but what if we need the titles of the movies instead of the count? For that we can use the COLLECT-operator, which gathers a property from each node into a list.
// Which titles were released in each year
MATCH (m:Movie)
RETURN m.released, COLLECT(m.title)

Again, using the COLLECT-operator we could get a list of actor names which acted in any given year.
// Which titles were released in each year and the actors names
MATCH (m:Movie)<-[:ACTED_IN]-(p:Person)
RETURN m.released, COLLECT(p.name)
 Good, but something is off. On closer inspection Keanu Reeves shows up three times in 2003, where we would only like to have each actor appear once. The reason is simply that Keanu did three movies that year, and to get rid of the duplicates, we must turn the the last operator of this post, the DISTINCT (yes, same as in good ol' relational SQL). So, we will modify our query and include the DISTINCT to our COLLECT, like so. This instructs Cypher to omit any duplicate entries, and we will the white meat of actors for each year.
Good, but something is off. On closer inspection Keanu Reeves shows up three times in 2003, where we would only like to have each actor appear once. The reason is simply that Keanu did three movies that year, and to get rid of the duplicates, we must turn the the last operator of this post, the DISTINCT (yes, same as in good ol' relational SQL). So, we will modify our query and include the DISTINCT to our COLLECT, like so. This instructs Cypher to omit any duplicate entries, and we will the white meat of actors for each year.
// Which titles were released in each year and the actors names
MATCH (m:Movie)<-[:ACTED_IN]-(p:Person)
RETURN m.released, COLLECT(DISTINCT p.name)

Better, and that wraps up for today, so let's sum up.
Summary In this post we have explored the Movies-dataset from the good folks at Neo4j. We have gone over the following concepts:
- Matching all the nodes in the dataset and returning the results
- Sorting the result by a property-value by using ORDER BY
- Counting a number of nodes by using the COUNT-function
- Checking for existence of a pattern using the EXISTS-function
- Filtering by using the WHERE clause
- COLLECTing node properties into a list
- Removing duplicates by using the DISTINCT-operator
Hope you have enjoyed this short little intro to querying Neo4j, and stay tuned for more in future posts, where we dive deeper into some more advanced stuff as well.
/Anders
Subscribe to my newsletter
Read articles from Anders Kirkeby directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Anders Kirkeby
Anders Kirkeby
I am a CTO and Web Architect with an interest in what drives high performing dev teams and how to construct scalable web apps without FAANG-level infrastructure.