Text Paraphrasing Using Parrot
 cicada
cicada
Introduction
As writers, we often seek out tools to help us become more efficient or productive. Tools such as Grammarly can help with language editing. Text generation tools can help to rapidly generate original contents by just giving the AI a few keyword ideas to work with. Paraphrasing content is also another great way to take existing content (either from your own or from others) and add your own spin to it. Wouldn’t it be great if we could paraphrase text automatically?
In this article we will go step-by-step how to perform paraphrasing in python for free. The main engine of our code will be a pre-trained model called Parrot. Its a NLU model originally developed by Google. We will download it from Hugging face and using it in our code. You will see we can paraphrase sentences with just few lines of code.
Anyone who have basic understanding of python can refer the hugging face website and write these quick start code to initiate the model, but my intention here is to give you some extra valuable information on setting up the environment first, because from my experience I have seen people spent lots of time just to build the compatible environment before running first line of code.
What is Parrot?
Parrot is a paraphrase based utterance augmentation framework purpose built to accelerate training NLU models. A paraphrase framework is more than just a paraphrasing model.Particularly, under the hood PARROT’s paraphrasing technology is based on the T5 algorithm (an acronym for Text-To-Text Transfer Transformer) that was originally developed by Google (for more information refer to the T5 resource at Papers with Code).
I am putting here few reference links if anyone want to deep dive into it
Installing the Parrot Library
Before installing the parrot, make sure you have these prerequisites on your system
- Python (V3)
- Pytorch
- jupyter notebook (optional)
- huggingface token (Need to create an account in hugging face)
- protobuf
- Git
- pandas
Once above setup is ready we can proceed for installing the Parrot by running below git command on terminal
pip install git+https://github.com/PrithivirajDamodaran/Parrot_Paraphraser.git
Working with Code
Once parrot installed we can start working on code development either on a Vscode or Jupyter Notebook. I would suggest to go with notebook as we can process the code individually by running the respective cell. It gives huge flexibility during debugging.
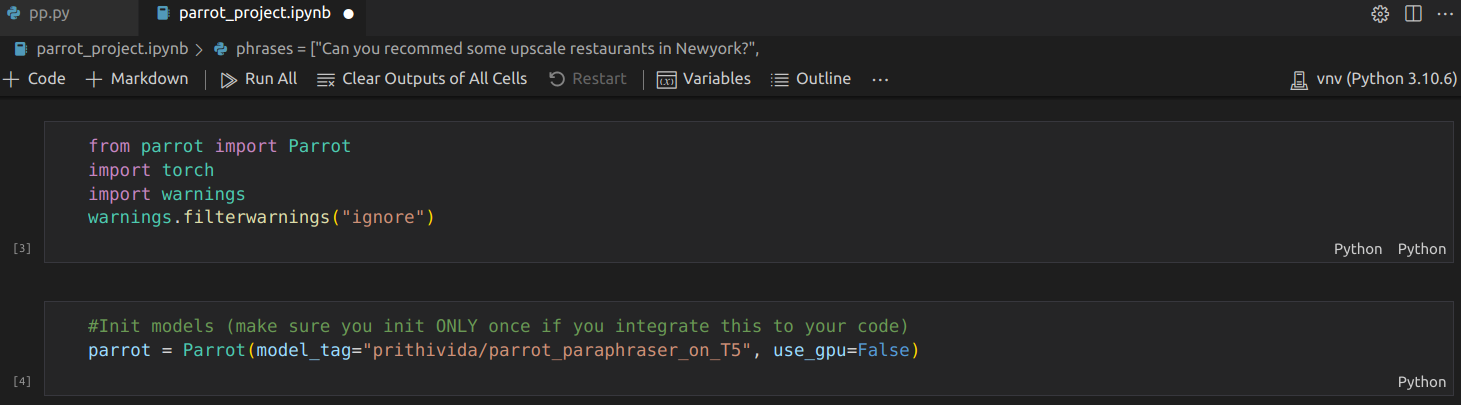
The parrot library contains the pre-trained text paraphrasing model that we will use to perform the paraphrasing task. Under the hood, the pre-trained text paraphrasing model was created using PyTorch (torch) and thus we’re importing it here in order to run the model. This model is called parrot_paraphraser_on_T5 and is listed on the Hugging Face website. It should be noted that Hugging Face is the company that develops the transformer library which hosts the parrot_paraphraser_on_T5 model.
There are chances it will through below OS error while initialising the model
OSError: Token is required (
token=True), but no token found. You need to provide a token or be logged in to Hugging Face withhuggingface-cli loginorhuggingface_hub.login. See https://huggingface.co/settings/tokens.
this is a bug in the huggingface model where we cant pass the access token directly from code so we have to add our token manually to the Parrot source code.
Try below options:
Option-1
Manually add the token to parrot class
- open the below path on your editor and apply the below changes
~/.local/lib/python3.10/site-packages/parrot/parrot.py
- Update the token
self.tokenizer = AutoTokenizer.from_pretrained(model_tag, use_auth_token = ) self.model = AutoModelForSeq2SeqLM.from_pretrained(model_tag, use_auth_token = )
You can get the token from here (Login with your credentials)
Option-2
For most of the people option-1 does the work but if you still receive the same OS error then try this approach.
Install huggingface_hub
pip install huggingface_hubRun below command from your terminal
python -c "from huggingface_hub.hf_api import HfFolder; HfFolder.save_token('YOUR_TOKEN_HERE')"
Now retry the failed cell. Download should work but in my case it failed again with below import error
ImportError: T5Converter requires the protobuf library but it was not found in your environment. Checkout the instructions on the installation page of its repo: https://github.com/protocolbuffers/protobuf/tree/master/python#installation and follow the ones that match your environment. Please note that you may need to restart your runtime after installation.
Solution to this problem is to install the portobuf module
pip install protobuf
Retry the model initiation. In my case download started but got failed in midway with below type error
TypeError: Descriptors cannot not be created directly. If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0. If you cannot immediately regenerate your protos, some other possible workarounds are:
- Downgrade the protobuf package to 3.20.x or lower.
- Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower). TypeError: Descriptors cannot not be created directly. If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
Solution to this is downgrading your portobuf module to a version closer to 3.20.x.
pip install --upgrade "protobuf<=3.20.1"
Now retry the download and it should work fine now. Library installation will take approximately 5-10 mins.
The initialisation will take time based on your system configuration. Its taking average 5 mins to initialise on a 8 GB system. Hence make sure to initialise it only once if you are integrating it to some frequent calling code.
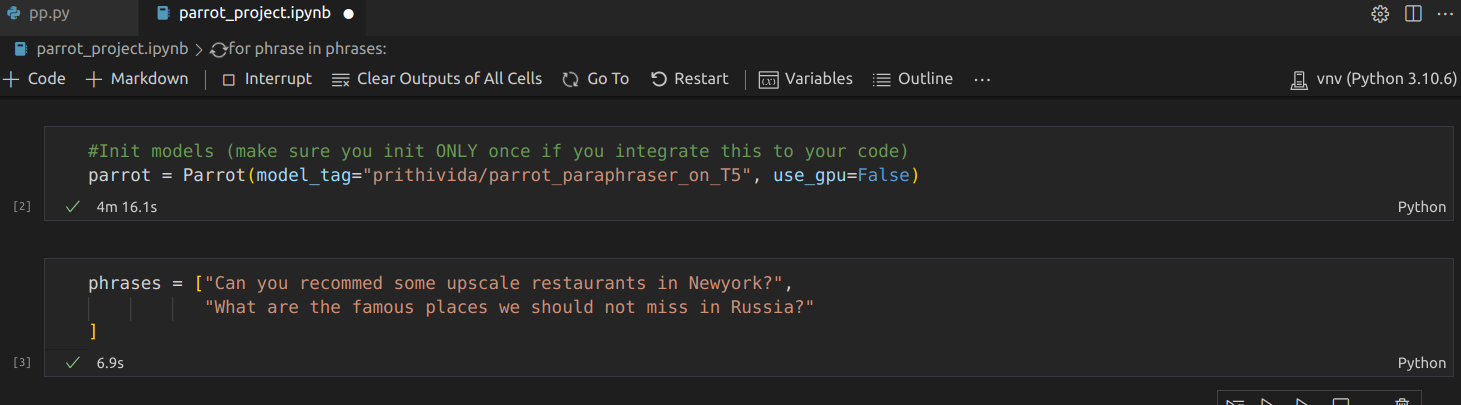
Now lets pass the phrases to the parrot to generate the paraphrases.
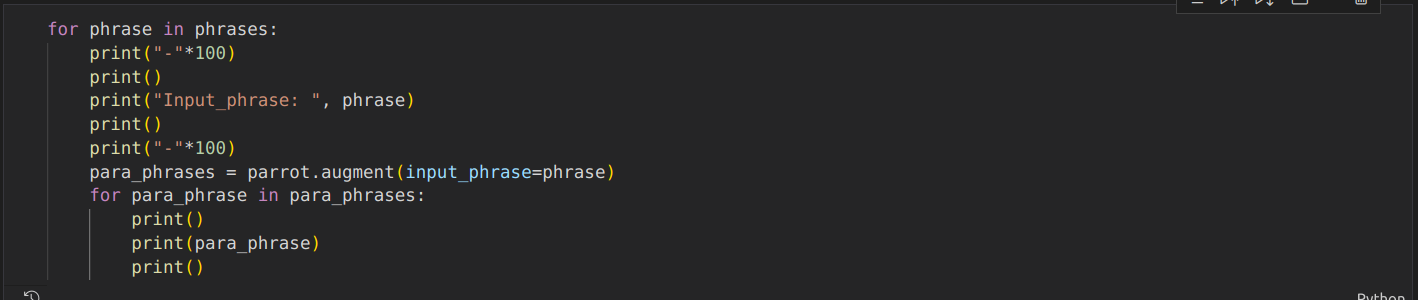
Outputs
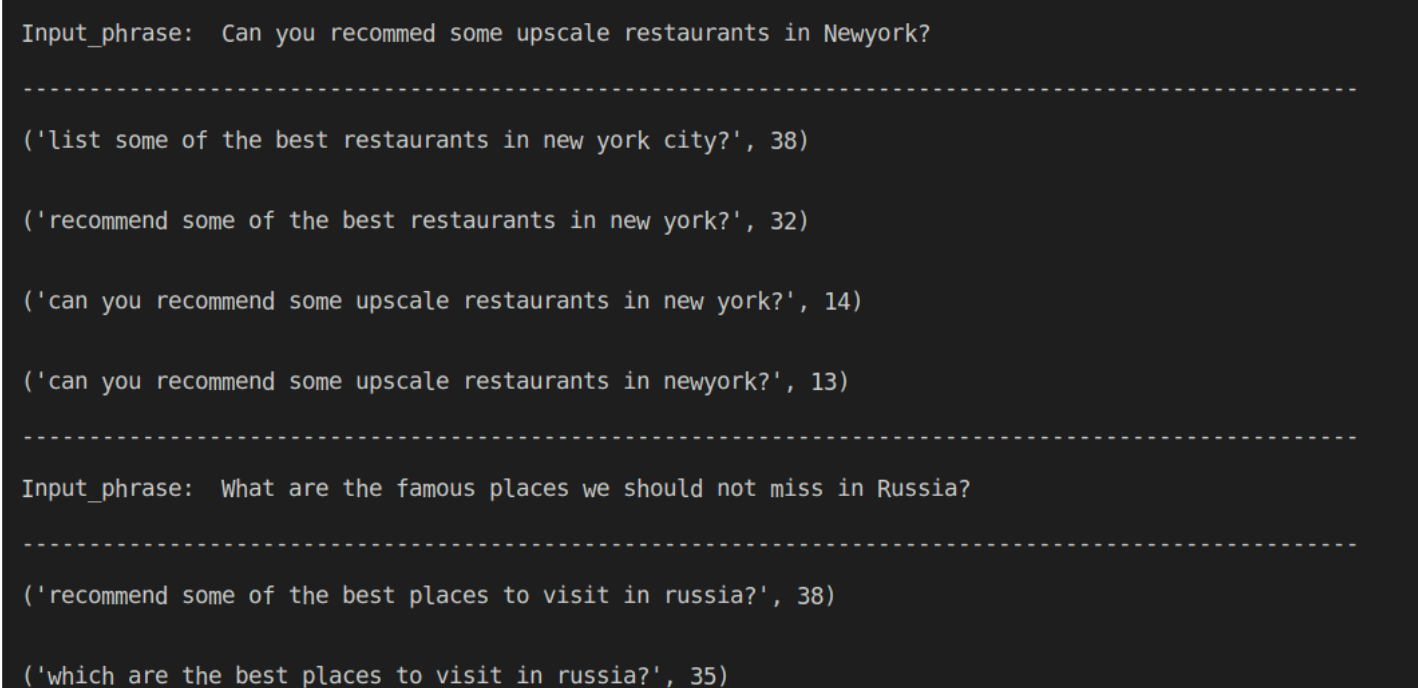
Here, we can see that PARROT produces 4 paraphrased text and you can choose any of these for further usage.
Conclusion
We have successfully produced paraphrased text using AI! Hugging face as off now have total 12 paraphrase models like versions from RapidAI, Rasa and NLPAug. While these model are great at paraphrasing, there are still some gaps and paraphrasing is NOT yet a mainstream option for text augmentation in building NLU models. Parrot is a humble attempt to fill some of these gaps. I think what makes Parrot more superior among its circle is providing flexibility to easy adjust the knobs for 3 key metrics (Adequency, Fluency & Diversity(Lexical/Phrasal/Syntactical)) used to generate high qulaity paraphrases.
I hope you have liked this post and learned something new today. Happy Learning!!
Subscribe to my newsletter
Read articles from cicada directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
cicada
cicada
Hi! 👋 I'm Cicada(my digital name), welcome to my blog! I’m a Software Engineer based in India. I have 8+ years of professional experience, 4 of them working with Database, 3 of them as DevOps engineer and 1+ as Automation/ML Eng. Over these years, I’ve been developing and releasing different software and tools. I write about Machine Learning/AI, but anything related to my area of expertise is a great candidate for a tutorial. I’m interested in Machine Learning/AI and Python.