Neural Machine Translation using EasyNMT Library
 Kalyan KS
Kalyan KS
Part 2 : Pretrained Models for Neural Machine Translation (NMT) Systems
Part 3 : Neural Machine Translation (NMT) using Hugging Face Pipeline
Part 4 : Neural Machine Translation (NMT) using EasyNMT library
EasyNMT is an easy-to-use python library for SOTA Machine Translation. This library is developed by NLP researchers from UKP Lab, TU Darmstadt. Some of the highlights of this library are
can do SOTA machine translation in just three lines of code.
supports automatic language detection for 170+ languages. So it is optional to specify language code for source sequence during machine translation
supports document translation
supports SOTA machine translation models like OPUS-MT, fine-tuned versions of mBART50 and M2M100.
💡 EasyNMT library supports SOTA machine translation models, which are Pytorch-based. So make sure that PyTorch is installed to use this library.
💥 EasyNMT Library Demo
You can also access the EasyNMT library through an online demo. Here is the screenshot of the EasyNMT online demo. The online Demo is based on the OPUS-MT model only as OPUS-MT models are lightweight compared to other SOTA MT models like mBART50 and M2M100.

EasyNMT library online demo can be accessed at this link
💥 Supported SOTA MT Models
EasyNMT library supports SOTA MT models like OPUS-MT, mBART-50, and M2M100. Here is a brief overview of these models
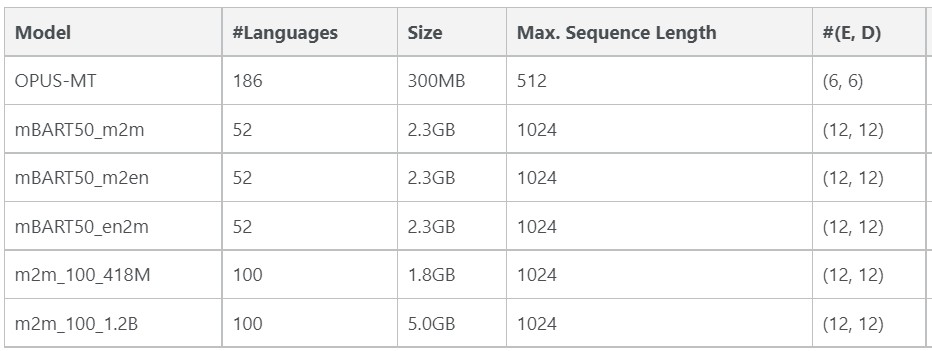
From the above the table, we can observe the following things
OPUS-MT is much lighter in size compared to other models
OPUS-MT models support a maximum sequence length of 512, while all other models support a maximum sequence length of 1024.
In OPUS-MT models, the encoder and decoder consist of 6 layers each, while in all other models, the encoder and decoder consist of 12 layers each.
💡 Except OPUS-MT, all other models support a maximum sequence length of 1024 tokens. If the input text sequence is more than the maximum sequence length, then the input sequence is split into sentences, and then each sentence is translated (this is referred to as document translation).
💥 EasyNMT vs Hugging Face MT Pipeline
In the previous blog post, we have the advantages of using the Hugging Face (HF) MT pipeline over naive model inference, i.e., using the pipeline avoids writing additional lines of code for various steps in model inference. Shortly, we can say Hugging Face MT pipeline simplifies the process of MT. EasyNMT further simplifies the process of MT. Here are the advantages of EasyNMT over the HF pipeline

Here are the advantages of the EasyNMT library over the HF pipeline for machine translation
EasyNMT library supports auto lang detection due to which we need not specify the source language.
There is no need to explicitly load the tokenizer and fine-tuned models. EasyNMT library automatically loads the tokenizer and model for the given model_name.
EasyNMT supports document translation. When the length of the source sequence is more than the maximum sequence length of the model, the source sequence is split into sentences and then each sentence is translated.
By default, the HF pipeline uses a CPU device. If you want to use GPU, we need to explicitly set the device. EasyNMT automatically uses a GPU device if available.
💥 Template for Machine Translation using EasyNMT Library
Now we will see the basic template for using the EasyNMT library for NMT inference.
Step 1: Create a model object by passing the model name to EasyNMT class
model = EasyNMT(model_name)
- Based on the model name given, the model is downloaded and then loaded using AutoModelForSeq2SeqLM class.
Step 2: Translate the source text sequence by invoking translate() using the model object.
#Translate source sentence to English
print(model.translate(text, target_lang='en))
We have to pass the source text sequence and the target language id to the translation (). As the EasyNMT library can do auto-language detection, we need not specify the source language id.
In this way, we can do SOTA machine translation using the EasyNMT library in just a few lines of code. Using the EasyNMT library to do SOTA machine translation is much easier compared to the Hugging Face Pipeline.
💥 Machine Translation using EasyNMT Library
Now we will see how to use the EasyNMT library to translate text sequences using SOTA models like OPUS-MT, mBAR50 and M2M100.
💡 As EasyNMT libraries support automatic language detection, we need not specify the source language during machine translation. EasyNMT library automatically identifies the source language.
💡 The EasyNMT library automatically sets the device i.e, if GPU is available, the models are run on GPU. Otherwise, the models are run on the CPU. So, we need not set the device explicitly.
🔥 Install and import libraries
#First install the libraries like EasyNMT and Sacremoses
!pip install -U easynmt sacremoses
#Import required classes from EasyNMT library
from easynmt import EasyNMT
Consider the following sentence in Hindi. We will see how well the SOTA MT models can translate this sentence from Hindi to English.
text = 'राहुल को उनकी शानदार बल्लेबाजी और क्षेत्ररक्षण के लिए मैन ऑफ द मैच का पुरस्कार दिया गया।'
🔥 OPUS-MT
#Load the model
model = EasyNMT('opus-mt')
#Translate source sentence to English
print(model.translate(text, target_lang='en'))
#output : Rahul was given the award of the Man of the Match to save his grand bat and territory.
🔥 mBART50_m2m
Here we want to translate a sentence in Hindi to English. mBART50-MO model can translate sentences from any of the supported languages to English. So we can use the model mbart50-m2m to translate the sentence from Hindi to English.
#Load the model
model = EasyNMT('mbart50_m2m')
#Translate the sentence to English
print(model.translate(text, target_lang='en'))
#output: Rahul was awarded the Man of the Match for his brilliant batting and fielding.
🔥 mBART50_m2en
Here we want to translate a sentence from Hindi to English. The mBART50-MO model can translate sentences from any of the supported languages to any of the supported languages. So we can use the model mbart50-m2en to translate the sentence from Hindi to English.
#Load the model
model = EasyNMT('mbart50_m2en')
#Translate the sentence to English
print(model.translate(text, target_lang='en'))
#output: Rahul was awarded Man of the Match for his excellent batting and fielding.
🔥 M2M100_418M
Here we want to translate a sentence from Hindi to English. The M2M100 model can translate sentences from any of the supported languages to any of the supported languages. So we can use the model m2m_100_418M to translate the sentence from Hindi to English.
#Load the model
model = EasyNMT('m2m_100_418M')
#Translate the sentence to English
print(model.translate(text, target_lang='en'))
#output: Raul was awarded the Man of the Match Award for his brilliant balloons and territory protection.
🔥 M2M100_1.2B
Here we want to translate a sentence from Hindi to English. The M2M100 model can translate sentences from any of the supported languages to any of the supported languages. So we can use the model m2m_100_1.2B to translate the sentence from Hindi to English.
#Load the model
model = EasyNMT('m2m_100_1.2B')
#Translate the sentence to English
print(model.translate(text, target_lang='en'))
#output : Raúl was awarded the Man of the Match Award for his brilliant battle and territory protection.
💥 Document Translation using EasyNMT Library
In the case of the HF pipeline, when the source sequence length is more than the maximum sequence length, the source sequence is truncated to the maximum sequence length and then the source sequence is translated. However, in the case of the EasyNMT library, when the source sequence is more than the maximum sequence length, the source sequence is split into sentences and then each sentence is translated. This is referred to as document translation.
Consider the following text sequence in English. Now we will use the EasyNMT library to translate this entire text sequence to Hindi.
document = """Albert Einstein (14 March 1879 – 18 April 1955) was a German-born theoretical physicist, widely acknowledged to be one of the greatest and most influential physicists of all time.
Einstein is best known for developing the theory of relativity, but he also made important contributions to the development of the theory of quantum mechanics.
Relativity and quantum mechanics are together the two pillars of modern physics. His mass–energy equivalence formula E = mc2, which arises from relativity theory,
has been dubbed "the world's most famous equation". His work is also known for its influence on the philosophy of science.
He received the 1921 Nobel Prize in Physics "for his services to theoretical physics, and especially for his discovery of the law of the photoelectric effect", a pivotal step in the development of quantum theory.
His intellectual achievements and originality resulted in "Einstein" becoming synonymous with "genius" """
#Load the model
model = EasyNMT('mbart50_m2m')
#Translate the text sequence
print(model.translate(document, target_lang='hi'))
#output: अल्बर्ट आइंस्टाइन (अल्बर्ट आइंस्टाइन, 14 मार्च 1879 – 18 अप्रैल 1955) एक जर्मन मूल सैद्धांतिक भौतिकीविद् थे, जिन्हें सभी समय के सबसे महान और प्रभावशाली भौतिकीविदों में से एक माना जाता था।
# आइंस्टाइन सापेक्षिकता के सिद्धांत के विकास के लिए सबसे अधिक जाना जाता है, लेकिन उन्होंने क्वांटम यांत्रिकी के सिद्धांत के विकास में भी महत्वपूर्ण योगदान दिया है।
# सापेक्षता और क्वांटम यांत्रिकी आधुनिक भौतिकी के दो स्तंभ हैं। उसका द्रव्यमान-ऊर्जा समकक्ष सूत्र E = mc2 है, जो सापेक्षिकता सिद्धांत से उत्पन्न होता है,
# "विश्व के सबसे प्रसिद्ध समीकरण" कहा गया है। उनका कार्य विज्ञान के दर्शन पर अपने प्रभाव के लिए भी जाना जाता है।
# उन्होंने 1921 में भौतिकी में नोबल पुरस्कार प्राप्त किया "अपने सैद्धांतिक भौतिकी के कार्यों के लिए और विशेष रूप से प्रकाश विद्युत प्रभाव के नियम की खोज के लिए", जो क्वांटम सिद्धांत के विकास में एक महत्वपूर्ण कदम था।
# उनकी बौद्धिक उपलब्धियों और मौलिकता के परिणामस्वरूप "Einstein" "genius" के समकक्ष बन गया
We can observe that the entire sequence in English is translated to Hindi without any truncation.
Subscribe to my newsletter
Read articles from Kalyan KS directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Kalyan KS
Kalyan KS
🔸I'm Katikapalli Subramanyam Kalyan (shortly Kalyan KS), NLP researcher with over 5 years of research experience. 🔸I have published research papers in top tier journals in medical informatics and EMNLP, AACL-IJCNLP workshops. 🔸My papers on transformers-based pretrained language models received 60+ citations including the citations from papers published by researchers from top tier institutes like University of Oxford, University of Texas, NTU Singapore, IIT Madras and top companies like Google. 🔸I have been serving as program committee member (as reviewer) for the last three years for ML4H workshop organized by researchers from top institutes like Stanford. 🔸 My broad research interests are natural language processing and deep learning. Specifically, I'm interested in pretrained language models and their application in various NLP tasks, learning with limited labeled data, robustness of NLP models and developing libraries for NLP tasks.