Understanding hash indexes
 Samuel Sorial
Samuel Sorial
Why database indexes?
When it comes to querying databases, one of the most time-consuming and performance-intensive operations is to do a linear scan of the entire table. This requires the database management system (DBMS) to retrieve all of the pages from the disk (which is a slow and expensive operation) and then scan through them one by one to find the specific data that is being queried. In large databases with millions or billions of records, this can be a major bottleneck and can cause queries to take a long time to complete.
To improve the performance of database queries, database indexes are used to provide faster access to the data stored in the database. An index is a data structure that is used to organize and store the data in the database in a way that makes it easy to locate the specific data that is being queried. There are different types of indexes, such as hash tables and B+ trees, that use different techniques to organize and store the data.
Hash Indexes
In this type of index, a hash table is used to store the index data. Like any other hash table, it requires two main components to function properly:
Hash function: This is a mathematical function that is used to convert the key of each piece of data into an index in the hash table. The specific hash function that is used depends on the context and the characteristics of the data being stored. In this case, we are not concerned with cryptography, so we choose a hash function that has a low rate of collisions, or situations where two pieces of data have the same key and need to be stored in the same index of the hash table. We simply seek the state of the art which achieves our goal, so we are not going to discuss it here.
Hashing scheme: This is the algorithm or strategy that is used to handle collisions and determine what to do when the hash table becomes full. Different hashing schemes can be used, depending on the specific requirements of the index and the trade-offs between performance and memory usage.
Hashing schemes
Hashing schemes can be divided into two categories: static hashing and dynamic hashing. In static hashing, the size of the hash table is fixed, which means that when the table is full, the database management system (DBMS) must create a new, larger table and move all of the data from the old table to the new one. This can be expensive and time-consuming. In contrast, dynamic hashing schemes allow the hash table to grow and shrink on demand, without the need to create a new table when the old one becomes full. This can provide more flexibility and improve the performance of the index.
Static hashing
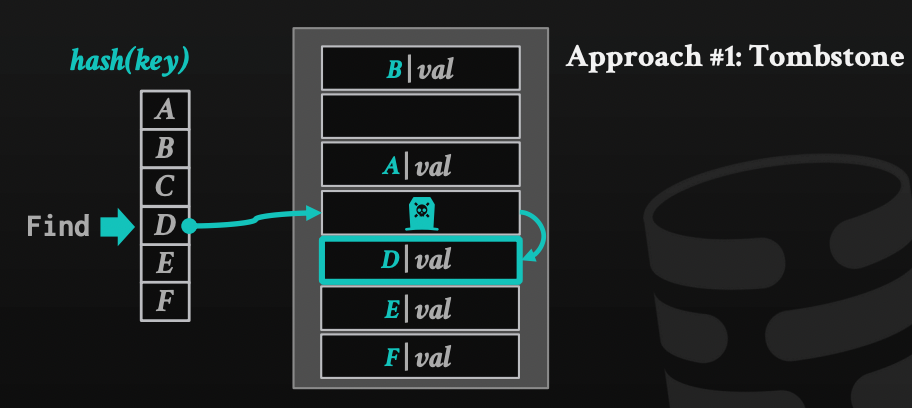
- Linear probe hashing: When a new piece of data is added to the hash table, the key is used to calculate an index in the array where the data should be stored. If the calculated index is already occupied, linear probing is used to find the next available empty index in the array where the new data can be stored. The algorithm looks for the next empty slot in the array in a linear fashion, starting from the calculated index. In case of deletes, the element can be marked as deleted (tombstone) and treated as an empty slot when inserting new data. We can move other elements beneath this deleted one, but it hurts performance, so tombstone is more common.
- Rubin hood: an extension of linear probe hashing, a variation of this approach that "steals" slots from rich keys (keys that have many collisions) and gives them to poor keys (keys that have few collisions) to improve the performance of the hash table. It reduces the number of collisions and makes the data more evenly distributed in the array. By stealing slots from rich keys and giving them to poor keys, Rubin hood can help to prevent the performance issues that can arise when the table becomes too full and the algorithm has to search through a large portion of the array to find an empty slot.
Dynamic hashing
One of the main disadvantages of static hashing is that the size of the hash table must be known in advance. Dynamic hashing allows the hash table to grow and shrink on demand, depending on the needs of the application. This provides more flexibility and can improve the performance of the index by avoiding the need to create new tables and move the data from the old table to the new one. Different techniques can be used to optimize the performance of dynamic hashing for different scenarios, such as read-intensive or write-intensive applications.
- Chained hashing: it's the most common dynamic hashing technique, in which the DBMS uses a lined list of buckets for each slot in the hash table. When it needs to insert a new record, it appends it to the linked list at the slot of the hashed key. It's a simple technique and improves performance, however, it requires more memory than other techniques. As we store a linked list instead of a single entry in each slot.
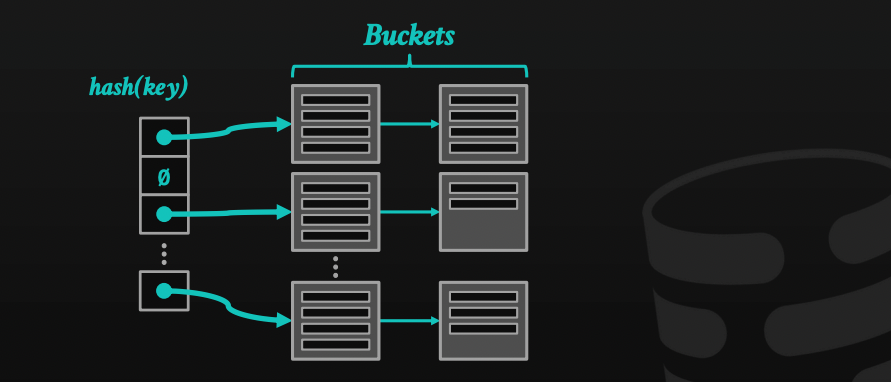
Extendible hashing: a variant of chained hashing that continuously rebalance the table, instead of letting it grow forever. It maintains a global and local depth bit count determining the number of bits needed to find buckets on the slots array. When a bucket is full, it splits the bucket and reshuffles it.
Linear hashing: another variant of chained hashing, but in this case, instead of splitting immediately at the overflow, it maintains a split pointer to know which bucket to split, no matter which bucket overflowed, the DBMS will split the bucket pointed at with the split pointer.
When to use hash indexes
Hash indexes are particularly useful when the key of the record being queried is known exactly. Its time complexity depends on the exact implementation and chosen hashing schemes that we already discussed, but it can be thought of as O(1) on average for inserts, lookups, and deletes. It may become O(n) in rare cases too. Its performance becomes really bad in case we have high collision rates. That's why you need to be careful when deciding to build a hash index.
Examples of when it is useful:
If you have a large database of cities and you want to quickly find the city with a given postal code, you can use a hash index on the postal code field to quickly look up the city.
If you have a database of user accounts and you want to quickly find the password associated with a given email address, you can use a hash index on the email field to quickly look up the password.
If you have a database of products and you want to quickly find the product with a given product code, you can use a hash index on the product code field to quickly look up the product.
References
CMU15-445/645 Database Systems lecture notes. Retrieved from: 15445.courses.cs.cmu.edu/fall2022
Note: ChatGPT was used to help me refine and make this post more concise, and readable, and provided some examples. So huge thanks to OpenAI!
Subscribe to my newsletter
Read articles from Samuel Sorial directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Samuel Sorial
Samuel Sorial
A software engineer who is enthusiast about back-end engineering and system design with a flexible mindset. I love playing with frameworks and moving between the languages just like an artist playing