Bias and Variance
 Jay Gala
Jay Gala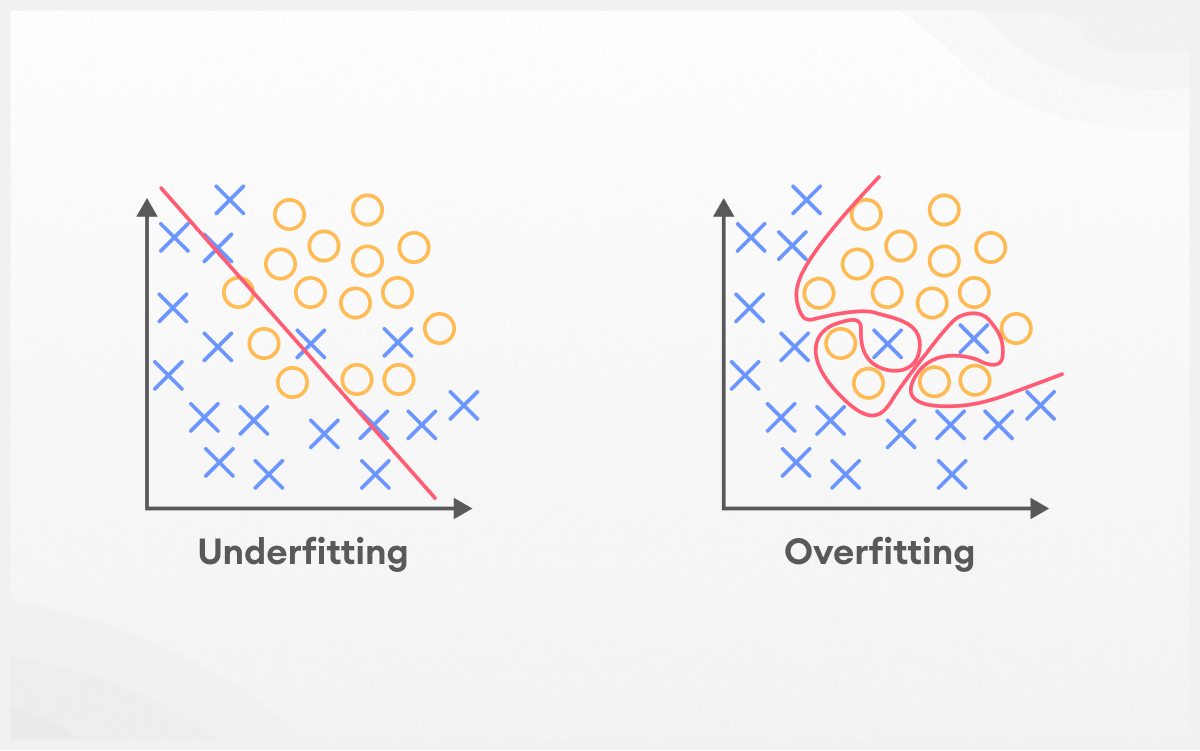
Understanding the different types of errors deeply goes a long way. In-depth knowledge of why they occur and how they can be identified helps to improve model performance significantly.
So what are Bias and Variance?
Bias and Variance are two types of reducible prediction errors in Machine Learning i.e these errors can be reduced with the help of certain techniques and algorithms to better align the predictions with the expected outputs. Let's take a look at both in detail.
Bias
Bias is the difference between the predictions made by the model and the actual/expected values. One of the key indicators of high bias is the training and test/validation dataset accuracy of the model.
Having high Bias is usually associated with high training error and high testing error. This indicates that the model is too simple to learn features from the data. In other words, it describes the inability of the model to understand the relationships between the data points.
High bias hurts the ability of a model to make predictions on unseen data.
High bias problems may be solved by one/more of the following techniques:
Reducing the regularization terms, if any.
Using complex models with higher-degree features
Increasing the number of features
Increasing the depth of the model
Training it for more epochs
Variance
Variance is a measure of how much the predicted values vary from the actual/expected values. High variance can also be identified by taking a look at the training and test/validation dataset accuracies.
Having high Variance is usually associated with low training error and high testing/validation error. What this means is that the model has overfitted to the training dataset (hindi mein kehte hai ratta maarna) thus it fails to generalize well on the test data.
The model essentially learns from the noise (outliers) of the dataset and may mistake unimportant features to be the opposite.
High variance problems may be solved by one/more of the following techniques:
Using regularization techniques like L1, L2, Dropout, etc. (blog post coming soon!)
Get more data (not always possible)
Reduce the number of features
Bias-Variance Trade-off
Now that we have seen Bias and Variance individually, let's talk about them together in a single problem and then about the trade-off (since they're quite opposite and also because everything in engineering is a trade-off right?)
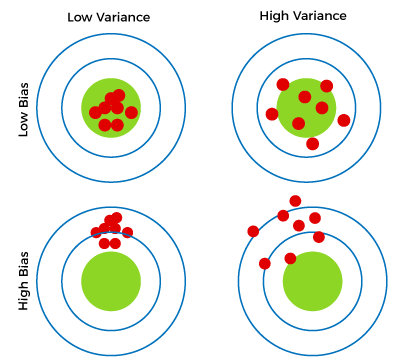
There can be 4 cases with Bias and Variance in a single problem:
High B, High V: Predictions (red dots) are far from the actual/expected value (green dot) a lot and amongst themselves too.
High B, Low V: Predictions are far from the actual/expected value but close to each other. Indicating that the model hasn't learned very well.
Low B, Low V: Predictions are close to actual/expected value and also close to each other. Indicating an ideal case.
Low B, High V: Predictions are close to the actual/expected value but scattered amongst themselves indicating that the model got the complexity of the model right, but the model has overfit to the training data.
Time for Trade-off
We understand from the above cases that having either High Bias or High variance will hurt the performance of a model significantly. If the model is too simple or has high bias then it will never be able to make correct predictions. On the other hand, if it is too complex or has high variance, it will learn the outliers and again not be able to render expected outputs.
Thus a trade-off is required between the complexities of the model. One must find a perfect balance between choosing a model that is too simple and a model that is too complex.
Take a look at the graphs below which show ideal trade-off points.
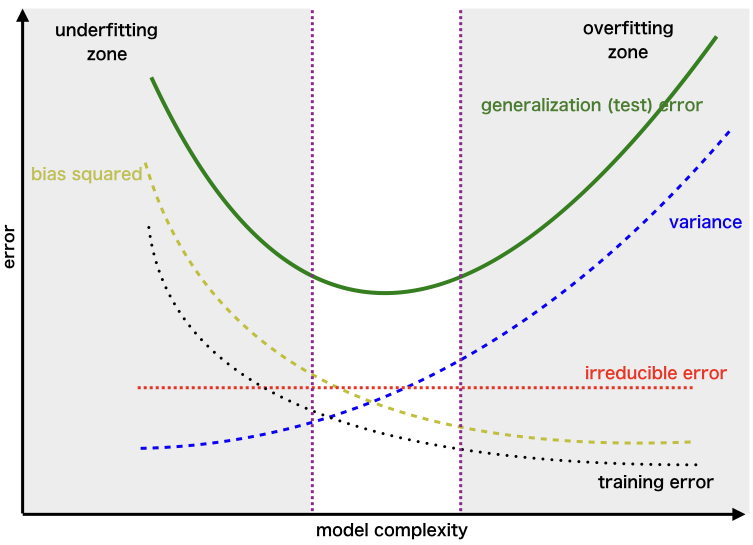
The region in the second graph between the purple lines shows an ideal region for the model complexity.
Subscribe to my newsletter
Read articles from Jay Gala directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jay Gala
Jay Gala
Currently working as an AI Software Engineer at Intel