Bias and Variance in Machine Learning
 Jay Oza
Jay Oza
Introduction
Bias and variance are two important concepts in machine learning that are closely related to the accuracy of a model. Understanding these concepts and how they influence model performance is crucial for developing effective machine-learning systems.
What is Bias?
Bias refers to the difference between the predicted values of a model and the true values of the data. A model with high bias tends to consistently under or overestimate the true values, leading to poor accuracy. On the other hand, a model with low bias is more accurate, as it is able to more closely predict the true values of the data.
Different Types of Biases
There are several different types of bias that can affect the performance of a machine-learning model. Here are four common types:
Sampling bias: Sampling bias occurs when the data used to train a model is not representative of the entire population. For example, if a model is trained on data from a particular geographic region, it may not generalize well to other regions. Sampling bias can lead to high bias in the model, as it may consistently under or overestimate the true values of the data.
Selection bias: Selection bias occurs when the data used to train a model is not randomly selected from the population. This can happen when the data is self-reported or volunteered, as it may not be representative of the entire population. Selection bias can lead to high bias in the model, as it may not accurately capture the underlying patterns in the data.
Data imbalance: Data imbalance occurs when there is a disproportionate number of examples for different classes in the data. For example, if a model is trained on data with a large number of negative examples and a small number of positive examples, it may be biased towards predicting negative outcomes. Data imbalance can lead to high bias in the model, as it may not accurately capture the underlying patterns in the data.
Overfitting: Overfitting occurs when a model is too complex and sensitive to small changes in the data, leading to poor generalization to new, unseen data. Overfitting can lead to high variance in the model, as it may perform well on the training data but poorly on new data.
What is Variance?
Variance, on the other hand, refers to the variability of a model's predictions. A model with high variance is sensitive to small changes in the data, leading to large fluctuations in its predictions. This can lead to overfitting, where a model performs well on the training data but poorly on new, unseen data. A model with low variance, on the other hand, is more stable and consistent in its predictions.
Different Types of Variances
In machine learning, variance refers to the variability of a model's predictions. High variance can lead to overfitting, where a model performs well on the training data but poorly on new, unseen data. Here are a few different types of variance that can affect the performance of a machine-learning model:
Data variance: Data variance occurs when the data used to train a model is highly variable, leading to large fluctuations in the model's predictions. This can be caused by the presence of noise or outliers in the data, or by the data is highly dependent on the specific context or conditions in which it was collected.
Model variance: Model variance occurs when a model is highly sensitive to small changes in the data, leading to large fluctuations in its predictions. This can be caused by using a complex model with many parameters, or by using a model that is not well suited to the task at hand.
Sampling variance: Sampling variance occurs when the data used to train a model is not representative of the entire population, leading to large fluctuations in the model's predictions. This can be caused by using a small sample of data, or by using data that is not randomly selected from the population.
Selection variance: Selection variance occurs when the data used to train a model is not randomly selected from the population, leading to large fluctuations in the model's predictions. This can be caused by using self-reported or volunteered data, or by using data that is not representative of the entire population.
How to find the right balance between bias and variance?
Finding the right balance between bias and variance is crucial for building accurate machine-learning models. A model with high bias and low variance is known as a "high-bias, low-variance" model, and it tends to be underfitting, meaning that it is too simple to accurately capture the underlying patterns in the data. On the other hand, a model with low bias and high variance is known as a "low-bias, high-variance" model, and it tends to be overfitting, meaning that it is too complex and sensitive to small changes in the data.
Various techniques to understand and adjust bias and variance
There are several techniques that can be used to adjust the bias and variance of a machine-learning model.
One common approach is to adjust the complexity of the model itself. For example, using a more complex model with more parameters may reduce bias but increase variance, while using a simpler model with fewer parameters may increase bias but reduce variance.
Another technique is to use regularization, which is the process of adding constraints to a model to prevent overfitting. This can be done by adding a penalty term to the objective function that is being optimized, which encourages the model to prefer simpler solutions.
Cross-validation is another technique that can be used to evaluate the bias and variance of a model. This involves dividing the data into multiple sets and training the model on one set while testing it on the others. This can help identify the optimal complexity of a model by comparing the performance of the different sets of data.
In addition to the techniques mentioned above, there are also several other strategies that can be used to reduce bias and variance in machine learning models.
One approach is to collect more data. This can help reduce bias by providing a larger and more representative sample of the data, and it can also help reduce variance by providing more examples for the model to learn from. However, it is important to ensure that the additional data is high quality and relevant to the task at hand.
Another strategy is to use ensembling, which is the process of combining the predictions of multiple models to improve the overall accuracy. This can be done by training multiple models on different subsets of the data and then averaging their predictions, or by training a single model on the predictions of multiple other models. Ensembling can help reduce variance by smoothing out the predictions of individual models, but it can also increase bias if the models being combined are biased themselves.
Finally, feature engineering is the process of designing and selecting the input features that are used to train a model. Good feature engineering can help reduce bias by providing the model with relevant and informative input data, and it can also help reduce variance by removing noise and irrelevant information from the data.
What is the bias vs variance trade-off?
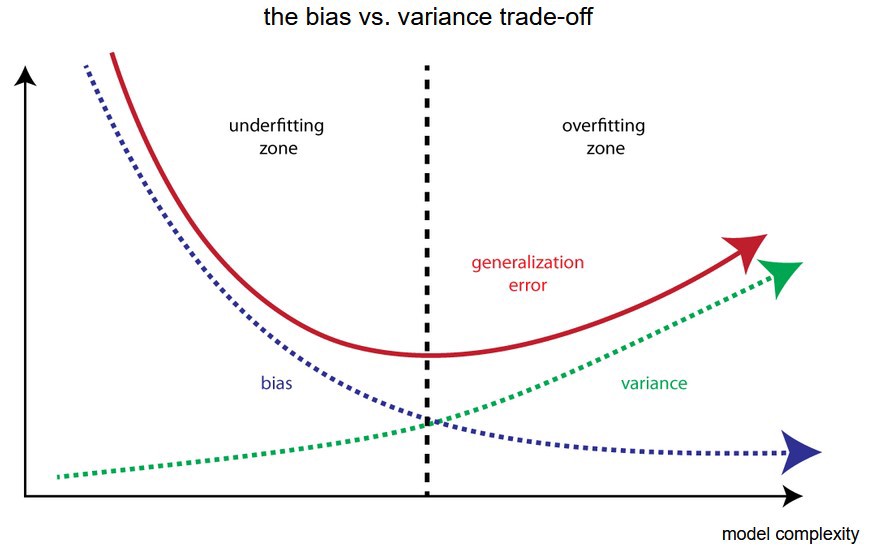
The bias-variance tradeoff is a fundamental concept in machine learning that refers to the tradeoff between the flexibility of a model and its ability to generalize to new data.
A model that is too inflexible, or has too much bias, will underfit the training data and may not accurately capture the underlying relationships in the data. This can lead to high errors in both the training and test data.
On the other hand, a model that is too flexible, or has too much variance, will overfit the training data and perform well on the training data but poorly on new, unseen data. This is because the model is too sensitive to the specific patterns in the training data and is not generalizable to new data.
Finding the right balance between bias and variance is key to building a successful machine-learning model. This is often referred to as the "sweet spot" in the bias-variance tradeoff.
Inference
In conclusion, bias and variance are important considerations in machine learning that can have a significant impact on the accuracy of a model. By using techniques such as model complexity, regularization, cross-validation, collecting more data, ensembling, and feature engineering, it is possible to effectively balance bias and variance and build accurate and reliable machine learning systems.
Thanks for reading ❤️
Subscribe to my newsletter
Read articles from Jay Oza directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jay Oza
Jay Oza
"Data is a problem and a solution" Hi, I am Jay Oza, a Final-year Computer Engineering student and a Data Scientist who has a keen interest in data and infusing it with programming to make a desirable solution for everyone!! As we know "Data is the new Oil". My main aim in pursuing Computer Engineering is inquisitiveness in Artificial Intelligence, Machine Learning and Blockchain. As a tech member of Datazen, we have built multiple projects in the domains of Machine Learning and Deep Learning. We have also hosted multiple sessions where students are being upskilled in the Data Science domain. We have hosted multiple hackathons for students to assist and comfort them with the concept of hackathons.