Word embedding in NLP
 Yuvraj Singh
Yuvraj Singh
You have come to the right place if you're looking for a resource that can teach you everything you need to know about word embedding techniques in NLP. After reading this blog post, you will be fully equipped with the knowledge necessary to understand how one of the most crucial word embedding techniques, "Word2Vec," functions.
What is word embedding in NLP?
Word embedding is a method used in natural language processing to give textual data a numerical representation. Word embedding is crucial since ML algorithms and machines cannot comprehend text. Therefore, we must translate words into their corresponding vectors for machines to comprehend data and identify relationships between words using these vectors.
Techniques for creating word embeddings
Word embedding can be classified into two categories: prediction-based and frequency-based word embedding. For tasks that require modeling the relationships between words, such as language translation and text classification, prediction-based techniques may generally be more effective.
| Frequency-based word embedding | Prediction-based word embedding |
| The process of creating these embeddings involves calculating the number of times each word appears in the phrase and utilizing that number as the foundation for a numerical representation of the term. | Prediction-based word embeddings, on the other hand, are generated by training a neural network to predict a word given its context |
| Techniques: Bag of words, TF-IDF and Glove | Techniques: Word2Vec,fastText |
Prediction-based word embedding
To create prediction-based word embeddings, we can employ either of two methods: Word2Vec vs. fastText: It is difficult to tell with certainty which of the two is superior because it depends on the particular task and the dataset being utilized. Both techniques have a long history of use and work well for many different natural language processing (NLP) problems.
Generally speaking, word2vec is a good option if you want to build high-quality word embeddings and have a large enough dataset to support it, whereas fastText is a good option if you want to create word embeddings rapidly and with out-of-vocabulary words that aren't commonly used. Although it is always a good idea to test both methods on your particular goal and dataset and compare how well they perform, today's blog article will focus on word2vec.
Word2vec techniques itself have two distinct designs (CBOW and skip-gram) for producing word embeddings, and each of these two architectures uses neural networks, for this blog post we will discuss the working of CBOW and in the upcoming blog, we will take a look at how skip-gram works.
Intuition behind Word2Vec
The fundamental idea behind the word2vec technique is that it first develops some features based on the vocabulary words and then assigns some values to these features while keeping the values in mind.
The question that now arises is: How can Word2Vec construct features based on vocabulary words?
The answer to this question is that Word2Vec employs its neural network-based designs for constructing features. However, the main drawback of employing neural networks for feature creation is that we are unaware of what those features are because they are internally labeled as f1, f2,...fn Thus, one of the primary issues is the vector's interpretability.
Working of word2vec
The problem is that word2vec is unable to directly represent a word numerically; instead, it attempts to solve a fake problem (i.e., locate the target word based on the context word (CBOW) and vice-versa (Skipgram) ), and as a byproduct of the fake problem's solution it derives the numerical representation of the word.
Let's suppose for the moment that we wish to generate word embeddings for the phrase "I adore data science" by using the continuous bag of words (CBOW) architecture of word2vec." Now, before doing anything else, we must decide how many values each word will have in its vector form ( In short we need to define utilizing how many features the vocabulary word will get the numerical representation ). In our case, we want that every vector must have 3 values in it.
Now that we are aware, word2vec's CBOW architecture initially attempts to resolve a dummy problem, which entails locating the target word based on context words. So let's look at what the data frame for this problem might look like.
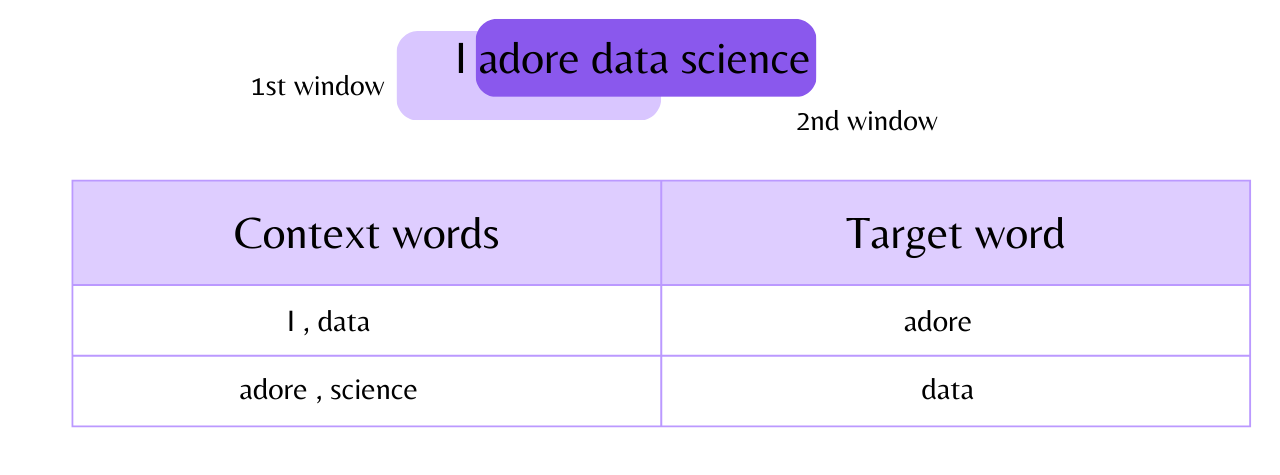
The words are then encoded using the one-hot encoding technique (OHE) after the data frame has been created.

The CBOW neural network-based architecture will now appear as follows after performing one-hot encoding of all the target and context words: the input layer will have 10 nodes, the hidden layer will have 3 nodes (as we decided that we only wanted the vector to have three dimensions), and the output vector will have 5 nodes.
The input layer neurons will receive the one hot encoded value of the words "I" and "data" for the first time, and certain weights will be initialized for each input layer neuron.
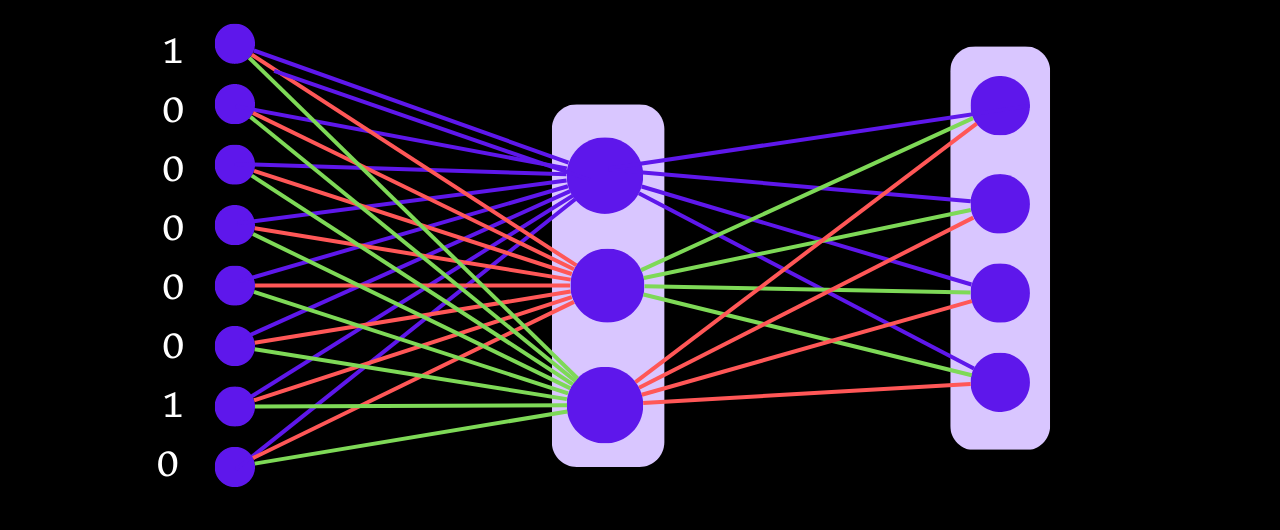
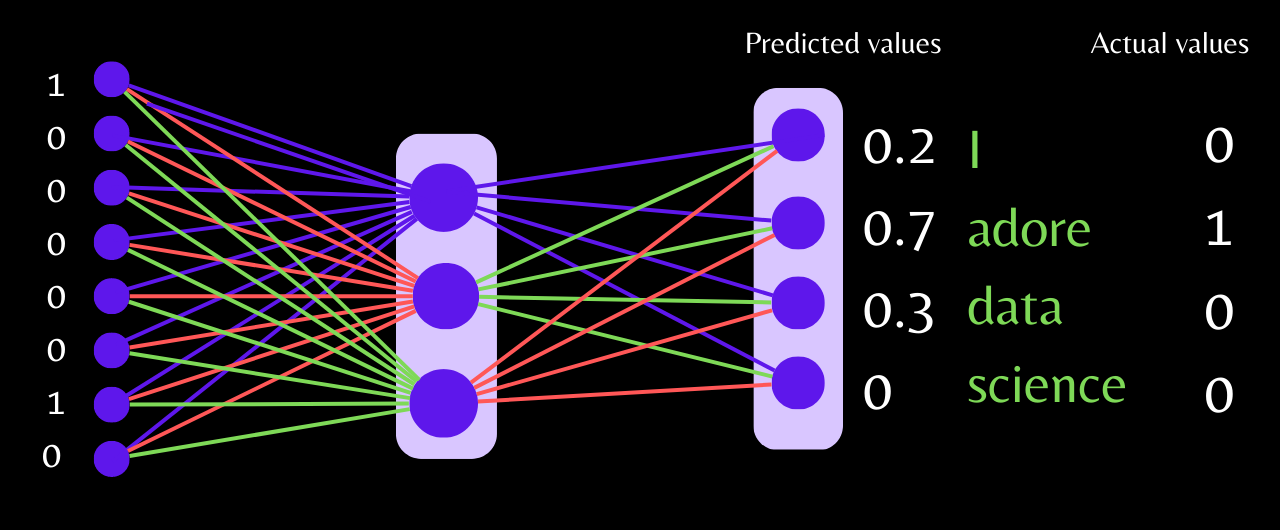
When the data is passed from the input layer to the hidden layer neurons, the linear function performs the sum of the weighted input and bias, and the output is passed to the softmax activation function, which returns a probability value. With this, after forward propagation is complete, the loss will be calculated, and then its value will be minimized through backpropagation.
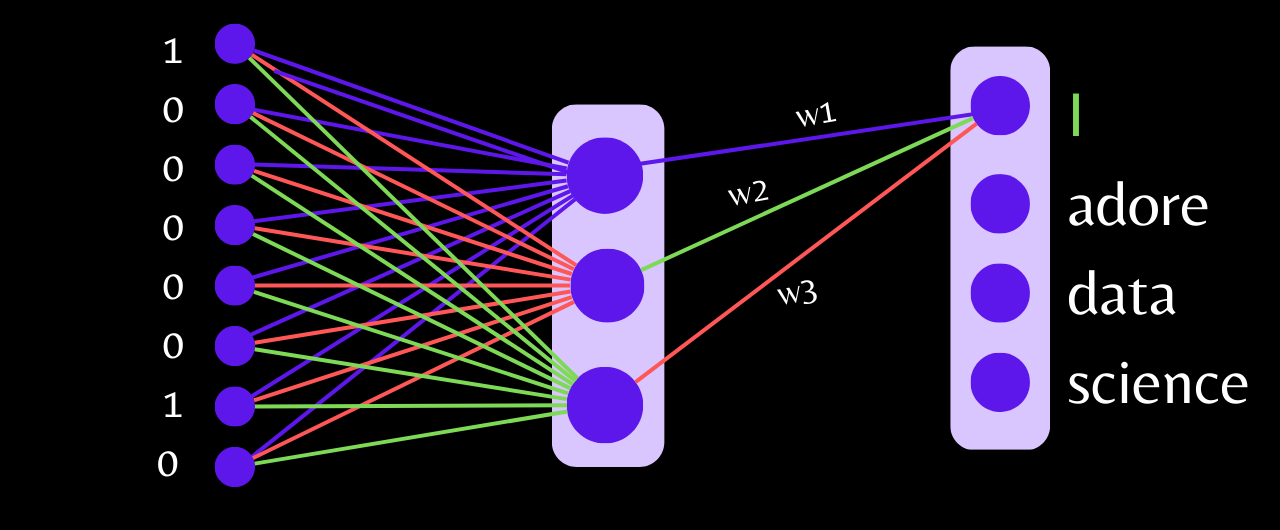
The weights between each hidden layer neuron and output layer neuron in the neural network will be the vector representation of that word once training is complete.
That's all for now, and I hope this blog provided some useful information for you. Additionally, don't forget to check out my 👉 TWITTER handle if you want to receive daily content relating to data science, mathematics for machine learning, Python, and SQL in form of threads.
Subscribe to my newsletter
Read articles from Yuvraj Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Yuvraj Singh
Yuvraj Singh
With hands-on experience from my internships at Samsung R&D and Wictronix, where I worked on innovative algorithms and AI solutions, as well as my role as a Microsoft Learn Student Ambassador teaching over 250 students globally, I bring a wealth of practical knowledge to my Hashnode blog. As a three-time award-winning blogger with over 2400 unique readers, my content spans data science, machine learning, and AI, offering detailed tutorials, practical insights, and the latest research. My goal is to share valuable knowledge, drive innovation, and enhance the understanding of complex technical concepts within the data science community.