One hot encoding technique
 Yuvraj Singh
Yuvraj Singh
Are you trying to find a resource that can teach you everything you need to know about a popular machine-learning encoding technique? If so, allow me to say that you have come to the correct spot, as today's blog will cover one hot encoding operation as well as its benefits and drawbacks. Without further ado, let's get going.
What is one hot encoding?
One hot encoding is essentially a technique for representing textual data or categorical values numerically in form of a vector because machines, or more precisely, machine learning algorithms, cannot comprehend text.
The process of giving a numerical representation to the text is known as feature extraction from text or text vectorization
Some important terms that you must know !
Before diving deep into the working of the one hot encoding technique, there are few terms about which you must be completely clear because further in this blog I will be frequently using it .
Corpus : Collection of all the words present in the text/dataset
Vocabulary : Set of all unique words present in corpus
Document : A single sentence, a paragraph or any other unit of text.
Working of One hot encoding technique
One Hot Encoding functions by first identifying all the unique words in the corpus and then converting each word in each document into a vector with a dimension equal to vocabulary size, where 1 indicates that the document word mat
To better understand this let us assume that we have a data frame having only 1 column and 3 rows


Each word in the document will eventually receive its numerical representation after repeating the same method.

Advantage of using one hot encoding
The only major advantage of using one hot encoding technique is that it is very much easy to implement and understand, even for people with limited knowledge of machine learning.
Drawbacks of using one hot encoding technique
In comparison to other text vectorization techniques that we will cover in the next few blogs, one hot encoding technique has a lot of disadvantages, which is why it is not as popular.
It can create a lot of sparse data, where most of the values are zero and a few values are non-zero. This can lead to problems such as overfitting.
We have to deal with the curse of dimensionality.
It doesn't capture the semantic information between the words, like the vector representation of the words "run", "walk" and "shoe" will not represent any relationship between the words even though they are somewhat associated.
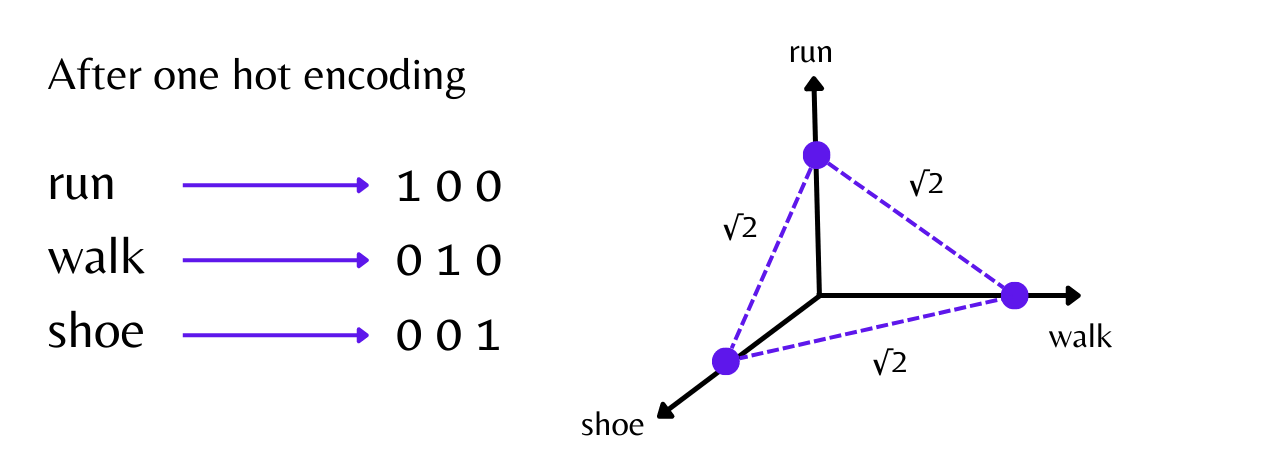
That's all for now, and I hope this blog provided some useful information for you. Additionally, don't forget to check out my 👉 TWITTER handle if you want to receive daily content relating to data science, mathematics for machine learning, Python, and SQL in form of threads.
Subscribe to my newsletter
Read articles from Yuvraj Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Yuvraj Singh
Yuvraj Singh
With hands-on experience from my internships at Samsung R&D and Wictronix, where I worked on innovative algorithms and AI solutions, as well as my role as a Microsoft Learn Student Ambassador teaching over 250 students globally, I bring a wealth of practical knowledge to my Hashnode blog. As a three-time award-winning blogger with over 2400 unique readers, my content spans data science, machine learning, and AI, offering detailed tutorials, practical insights, and the latest research. My goal is to share valuable knowledge, drive innovation, and enhance the understanding of complex technical concepts within the data science community.