Distributed computing framework - MapReduce
 padmanabha reddy
padmanabha reddy
What is MapReduce?
MapReduce is a software framework for processing large data sets that are distributed over several machines.
MapReduce facilitates concurrent processing by splitting petabytes of data into smaller chunks and processing them in parallel on Hadoop commodity servers. In the end, it aggregates all the data from multiple servers to return a consolidated output to the application.
How MapReduce Works?
MapReduce works by breaking the data processing into two phases: Map phase and Reduce phase. The map is the first phase of processing, where we specify all the complex logic/business rules/costly code. Reduce is the second phase of processing, where we specify light-weight processing like aggregation/summation.
The Map task takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key-value pairs).
The Reduce task takes the output from the Map as an input and combines those data tuples (key-value pairs) into a smaller set of tuples.
The reduce task is always performed after the map job. Let us now take a close look at each of the phases and try to understand their significance.
Input Phase − Here we have a Record Reader that translates each record in an input file and sends the parsed data to the mapper in the form of key-value pairs.
Map − Map is a user-defined function, which takes a series of key-value pairs and processes each one of them to generate zero or more key-value pairs.
Intermediate Keys − The key-value pairs generated by the mapper are known as intermediate keys.
Combiner − A combiner is a type of local Reducer that groups similar data from the map phase into identifiable sets. It takes the intermediate keys from the mapper as input and applies a user-defined code to aggregate the values in a small scope of one mapper. It is not a part of the main MapReduce algorithm; it is optional.
Shuffle and Sort − The Reducer task starts with the Shuffle and Sort step. It downloads the grouped key-value pairs onto the local machine, where the Reducer is running. The individual key-value pairs are sorted by key into a larger data list. The data list groups the equivalent keys so that their values can be iterated easily in the Reducer task.
Reducer − The Reducer takes the grouped key-value paired data as input and runs a Reducer function on each one of them. Here, the data can be aggregated, filtered, and combined in a number of ways, and it requires a wide range of processing. Once the execution is over, it gives zero or more key-value pairs to the final step.
Output Phase − In the output phase, we have an output formatter that translates the final key-value pairs from the Reducer function and writes them onto a file using a record writer.
Example:-
Let’s consider a simple use of case word count where we try to find out the number of occurrences for each word. In this scenario, the user program splits the input file into M pairs. If the input is a corpus, each split would be a document, and if the input is one document, each split would be a line, etc…And also it spins up multiple workers, one of them being the master node.
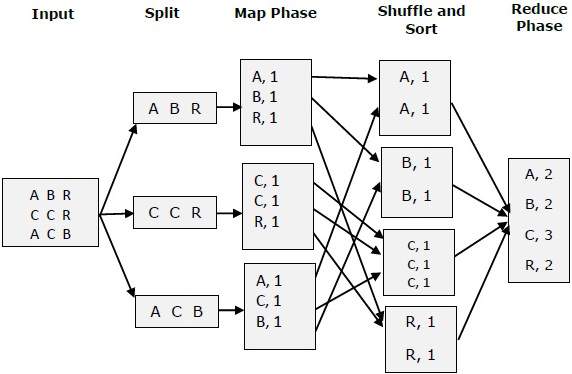
Example:-
Let us consider the following LinkedIn profile views data & we want to compute the number the views each profile had reeived.
LinkedIn profile views:-
ID,From-Member,To-Member
1,sonu,sushmitha
2,madhuri,sushmitha
3,sushmitha,sonu
4,sonu,madhuri
5,madhuri,sonu
6,swetha,sonu
The record reader takes in the above as input and gives the following key-value pairs as output.
(0,[1,sonu,sushmitha])
(1,[2,madhuri,sushmitha])
(2,[3,sushmitha,sonu])
(3,[4,sonu,madhuri])
(4,[5,madhuri,sonu])
(5,[6,swetha,sonu])
The above data is distributed across multiple nodes and Mapper program is executed on each node. Hence multiple mappers would run in parallel and give the following key-value pairs as output.
(sushmitha,1)
(sushmitha,1)
(sonu,1)
(madhuri,1)
(sonu,1)
(sonu,1)
Output from all the mappers is transferred to a reducer machine. This process of transferring the mapper output to the reducer machine is called shuffling. The data is then sorted on the reducer machine. Below is the sorted data.
(madhuri,1)
(sonu,1)
(sonu,1)
(sonu,1)
(sushmitha,1)
(sushmitha,1)
(madhuri,{1})
(sonu, {1,1,1})
(sushmitha,(1,1))
The Reducer progams takes the above data as input and gives the following data as output.
(madhuri,1)
(sonu,3)
(sushmitha,2)
Subscribe to my newsletter
Read articles from padmanabha reddy directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by