Git Advanced-2
 Ritesh Kumar Nayak
Ritesh Kumar Nayak
Git Revert & Reset
Git Revert
What is Git Revert?
$ git revert commitID : As the name suggests it is something like going back. In the context of Git, revert works as an undo mechanism. It helps to go back or undo a step if made wrong however, it is not a traditional undo.
What's so special about Revert?
Revert is a step ahead of traditional undo operation. Instead of removing the commit from the history, it finds out how to invert the changes introduced by the commit.
It requires the commit id which we can get from the git log by the command $ git log --oneline .
Illustration
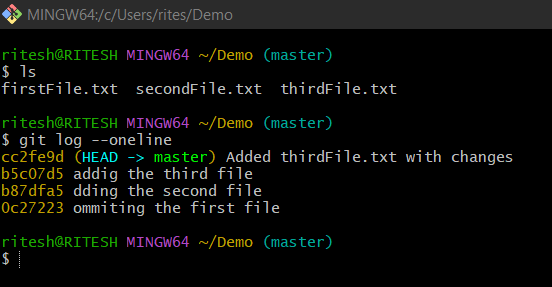
In the above picture, you can see we have 3 files and 4 commits. The last commit was some changes to the thirdFile.txt with the commit id cc2fe9d
Suppose, unknowingly we have made some mistakes while making changes to thirdFile.txt and we want to undo that mistake by revert operation.
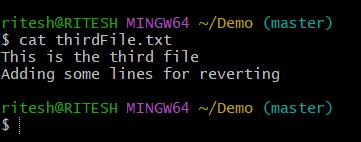
The content of thirdFile.txt before the revert was as below:
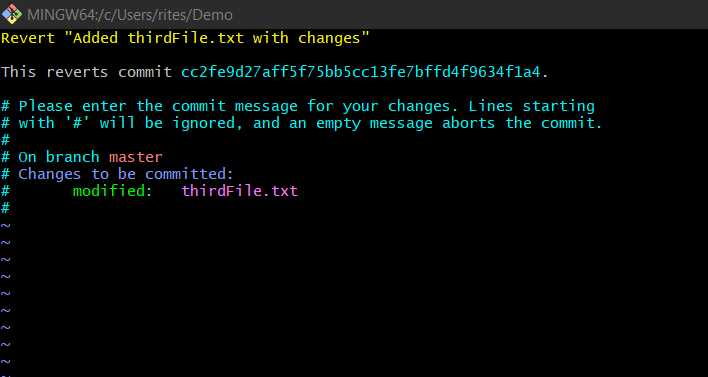
$ git revert cc2fe9d : This command will revert the last commit that was made with the specified commit id. After hitting the command it will prompt for the revert you are proceeding for as below which is similar to git message here you can specify any customized message you want to log during the revert operation:
The content of thirdFile.txt after the revert will be as below:
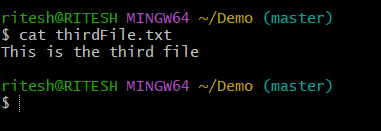
Here, "adding some lines for reverting" is undone in the above picture.
And now if we recheck the log as shown below picture with the command $ git log --oneline we can see that another hashId 844bca4is generated for the revert operation without impacting the previous log of commit ids even the commit id cc2fe9d is still intact which is the difference between traditional undo and git revert.
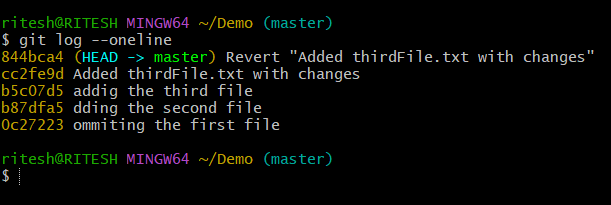
NB: $ cat thirdFile.txt : cat is the Linux command to display the content of a file.
Can a file be deleted with Revert command?
Technically the answer is no. Revert command undoes the commit you specify as hashId . So whatever operation has been performed with that hashid will be undone.
Let's understand the below scenario:
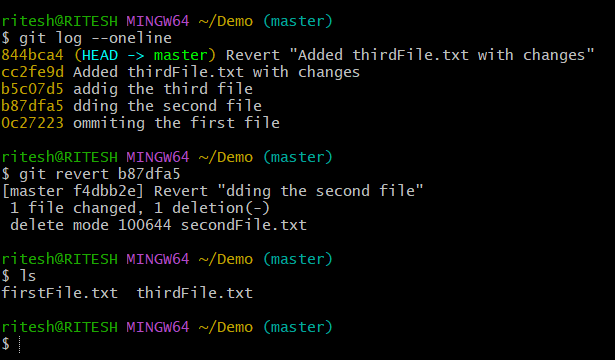
Above picture, we can see that we have 5 commits until now out of which the commitID b87dfa5 is logged for adding the Second file so by this commit a new file was added or created on the master branch before that the file was not present hence, the sole purpose of this particular commit is to create that file. So, when we performed $ git revert b87dfa5 it reverted to its previous state(deleted) the file that was created against the commitID. Hence, the revert operation considers every action as a commit and undoes whatever was done whether it's a code change or file creation it simply brings the operation one step back.
Now you can see logs are still intact. The revert action that deleted the SecondFile is also logged with a hasID or commit ID:
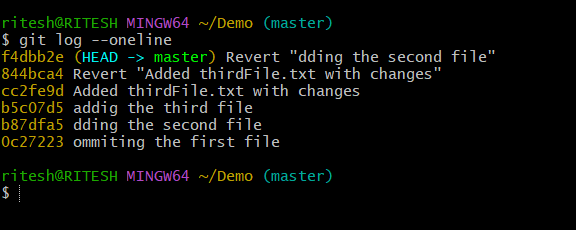
Hence, we can say that "Everything we do in Git is a Commit".
Git Reset
Git Reset is a very important and versatile tool when it comes to undoing changes or mistakes. It has three primary forms of invocation. These forms correspond to command-line arguments --soft and --hard .
Git Reset has a benefit over Git Revert which is, it completely cleans the entire log whereas Git Revert keeps a log of the reverted commit as well.
Illustration
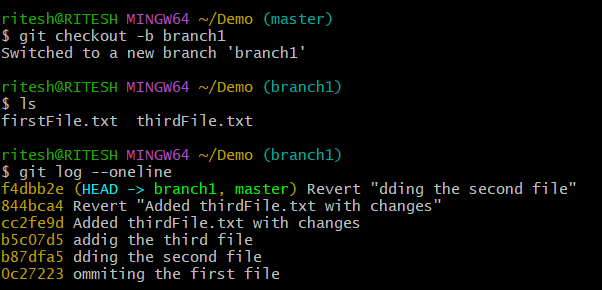
To understand this we will create another separate branch to keep our master branch intact where we will create several files and take the created branch ahead of the master branch. Now in the below picture, you can see currently we have 2 files firstFile.txt and thirdFile.txt.
Now, we have added one more file as SecondFile.txt in our newly created branch and have done some incremental commits which you can see below:
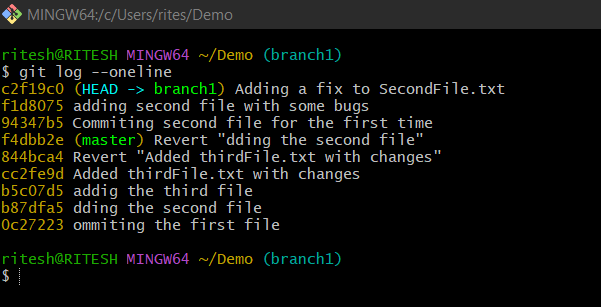
Consider a scenario:
Suppose after doing the above 3 to 4 commits you realized that there are some unstable codes you have committed and now you want to delete the commits you made as well as you don't even want to keep a single trace/log of previous commits. Here comes the command $ git reset --soft
$ git reset --soft commitID : This command will help you with the above scenario. It will clear all the commits, modifications made and even the log of the commits that are performed after the specified commitID.
All the mess is done right after the commitID will be cleared.
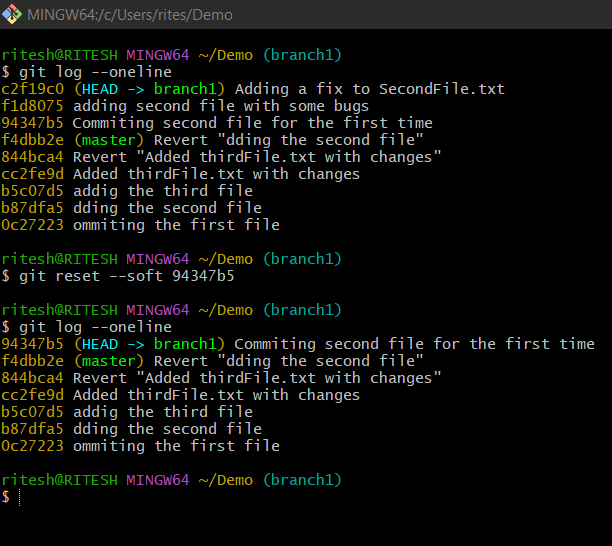
Now, have a look at the below picture to understand the difference made with the reset operation. Here the command $ git reset --soft 94347b5 has cleaned all the commits that were made on branch1 previously upto 94347b5 :
Git Revert vs Git Reset
It's important to understand that git revert undoes a single commit—it does not "revert" back to the previous state of a project by removing all subsequent commits. In Git, this is called a reset, not a revert.
Reverting has two important advantages over resetting.
First, it doesn’t change the project history, which makes it a “safe” operation for commits that have already been published to a shared repository.
Second, git revert can target an individual commit at an arbitrary point in history, whereas git reset can only work backward from the current commit.
git revert is a safer alternative to git reset in regards to losing work.
Cherry-Pick
Cherry-Pick is a very powerful command that enables us to pick any arbitrary commit from any branch and append it to the working head. It picks the commit by reference.
In layman's terms, we can say that it moves a commit from one place and append at the current working HEAD.
Cherry-Pick Usecase
Suppose you have made some changes in a file and committed to the wrong branch. However, now you realized and want to undo it and move that particular commit to the right branch. This is where cherry-pick kicks in.
To perform cherry-pick, make sure you switch to the correct branch and cherry-pick the commit to where it should belong.
Illustration
Now let's say we have two branches master and branch1. Total 8 commits are combining all the branches as below:
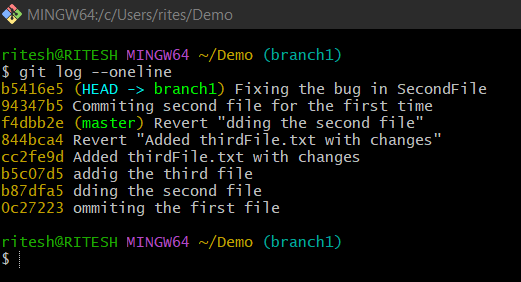
After committing the last commit which is b5416e5 (HEAD -> branch1) Fixing the bug in SecondFile , you realized this commit needs to be done in the master branch as part of a bug fix. In that case, you have to cherry-pick this particular commit with it's reference b5416e5 .
To do so we first need to switch to the branch into which b5416e5 will be cherry-picked.
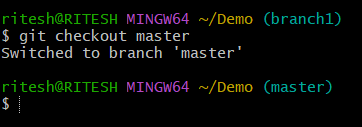
Now, as we have moved to the master branch using $ git checkout master let's perform cherry-pick as below:
$ git cherry-pick commitID : It will pick the specified commit and append to the master branch as the latest commit as below, now you can see the commit cea35d5 which was previously on branch1 is now appended to master as the latest commit.
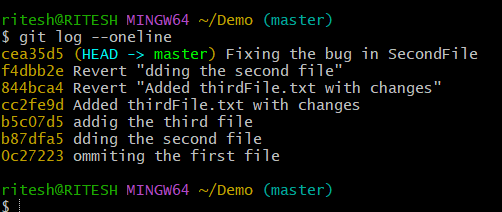
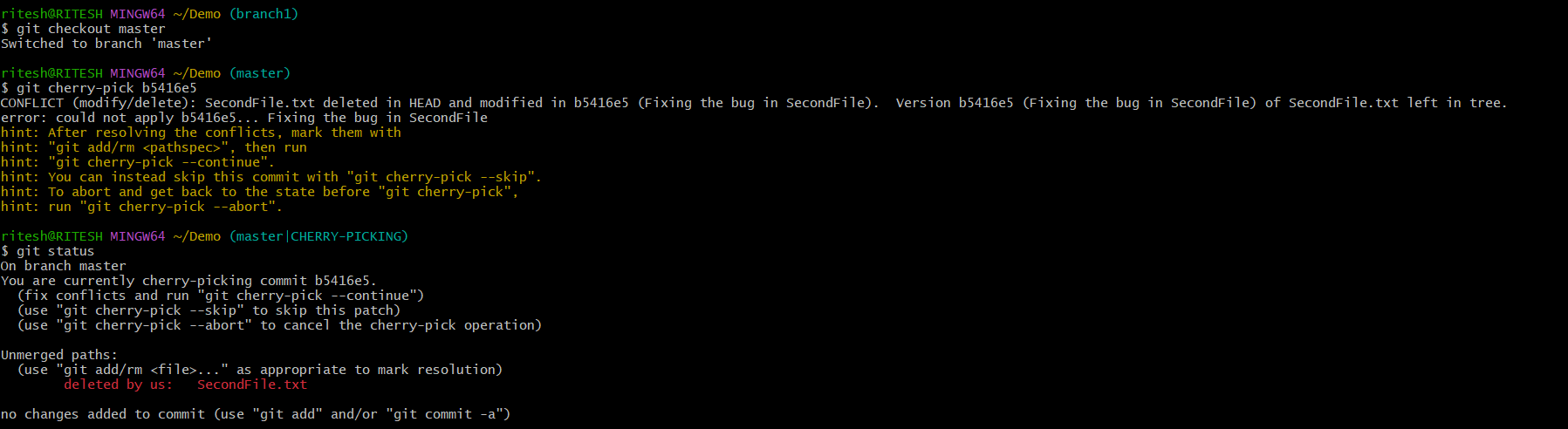
Condition: What if there is any conflict?
If during cherry-picking any conflict arises as blow, we first need to resolve the conflict then only we can proceed with cherry picking.
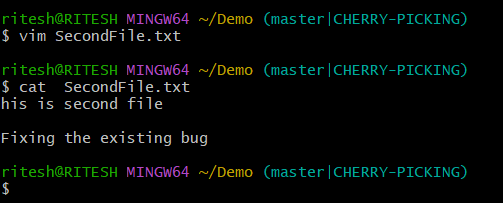
Read through the conflicted file using $ vim filename . By doing vim you will be prompted with details about the conflicts and will be able to resolve them.
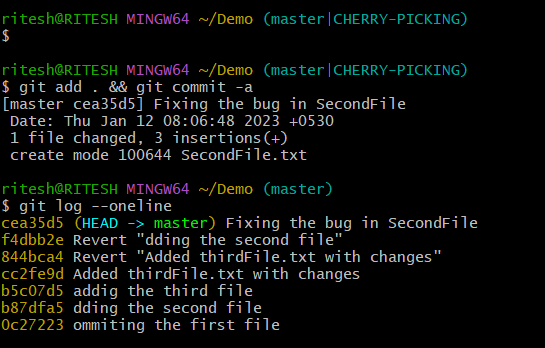
After resolving the conflicts you can be able to succeed with cherry-picking as below, here I resolved the conflicts by committing uncommitted files :
NB: Conflicts can vary or you may not face any conflicts at all. But in real scenarios we mostly face conflicts as lot of changes, fixes gets done by multiple developers
Summary:
Cherry picking is a powerful and convenient command that is incredibly useful in a few scenarios. Cherry picking should not be misused in place of git merger or git rebase.
The git log --oneline or git log commands are required to help find commits to cherry-pick.
Subscribe to my newsletter
Read articles from Ritesh Kumar Nayak directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ritesh Kumar Nayak
Ritesh Kumar Nayak
Passionate about helping organizations build scalable infrastructure and DevOps solutions with cloud technologies. Experienced in designing robust systems, automating processes, and driving efficiency through innovative cloud solutions. Advocate for best practices in DevOps and cloud computing, committed to enabling teams to achieve their full potential.