How to load big data between two different cloud providers ( from GCP Cloud storage to AWS S3)
 Melody Egwuchukwu
Melody Egwuchukwu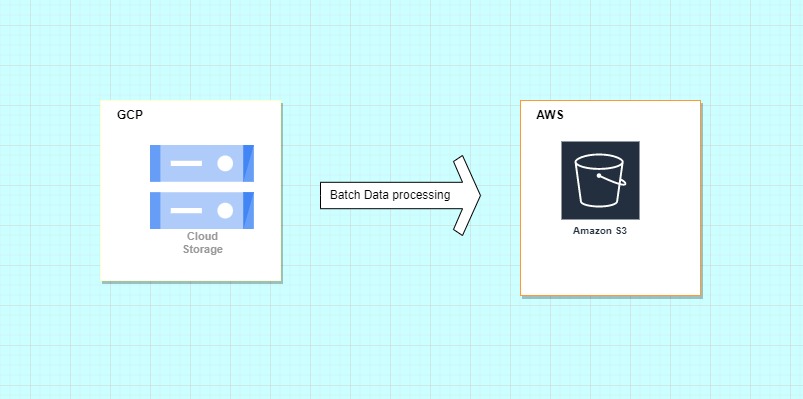
Introduction
When dealing with large volumes of data, storing them in our on-premise servers will be a lot of costs ( in terms of maintenance and speed of data retrieval). That is why many organizations use various cloud provider services to manage and optimize the massive volume of data they produce.
In this blog, we will look into the process of moving big data from GCP cloud storage to AWS S3 ( of which both are data lakes).
Why is this useful to know as a Data/Analytics Engineer?
As a Data Engineer or Analytics engineer of an organization, your company at some point may want to move from one cloud provider to the other, this can happen for various reasons like cost, scalability, etc. You have been given the task to move all the data in the cloud storage bucket to AWS S3 which is the use case in this blog.
What do you do?
- You have an option of writing a custom python script that helps move the data but this will be time taken and maybe not scalable. In order not to reinvent the wheel:
AWS provides a service called DataSync
AWS DataSync is a service that simplifies and automates the transfer of data between storage systems and services.
How it works
DataSync compares the metadata of every file or object in the source and destination. If the size of data in the source is larger than the storage space in the destination there will be failed transfer. You, therefore, have to ensure the size of the data has enough size to be accommodated at the destination.
Terminologies
DataSync Agent: Is a virtual machine owned by you and used to access your self-managed storage and read data from or write data to it (self-managed storage can refer to on-premises or in-cloud storage systems. Transfers with these kinds of systems require using a DataSync agent). It can be deployed on VMware, Hyper-V, KVM, or as an AWS EC2 instance.
AWS DataSync provides several types of agents for different storage environments.
For example, you can use a VMware agent to transfer data from an on-premises file system.
And if you're copying data from a cloud-based file share that isn't an AWS storage service, you must deploy your DataSync agent as an Amazon EC2 instance (which is our case)
If you are copying data between AWS storage services, you do not need DataSync agent at all.
Location: Each DataSync needs a source which it copies data from and a destination where that data is stored. The DataSync location is where this is specified.
Task Execution: Shows all the history of tasks run in the DataSync.
Now that we have this understanding, let's dive right in.
DEMO
Since our source is a cloud-storage system we are going to launch an EC2 instance which will be used to deploy the DataSync agent, else an on-premises hypervisor such as Hyper-V or VMware) would have been used.
the EC2 instance requires AMI to be chosen(for those, who do not know, AMI stands for an Amazon Machine Image and it is a template that contains the software configuration (operating system, application server, and applications) required to launch your instance. If you want to know more about AMI click here
We need an AMI to launch our EC2 instance based on the image provided by DataSync. This image contains the DataSync VM image.
Agent AMIs vary by region, thus you have to choose the right one for your region.
In order to get the data about the latest DataSync AMI for a specified region, run this command (AWS CLI has to be installed on your machine)
Once you have signed into your AWS account via the Cli, if you are using windows I advise using the command prompt to sign in.
aws ssm get-parameter --name /aws/service/datasync/ami --region yourRegion
The result of running this command will be an object containing information about the DataSync image - AMI ID (value), version, ARM, etc.
Now, use the following link and replace 2 parameters - source-region and ami-id with your source file system region and AMI ID that we got by running the previous command.
https://console.aws.amazon.com/ec2/v2/home?region=source-region#LaunchInstanceWizard:ami=ami-id
By going through this link, the "Launch an instance" page will be opened in your AWS account. That is why you need to install AWS Cli.
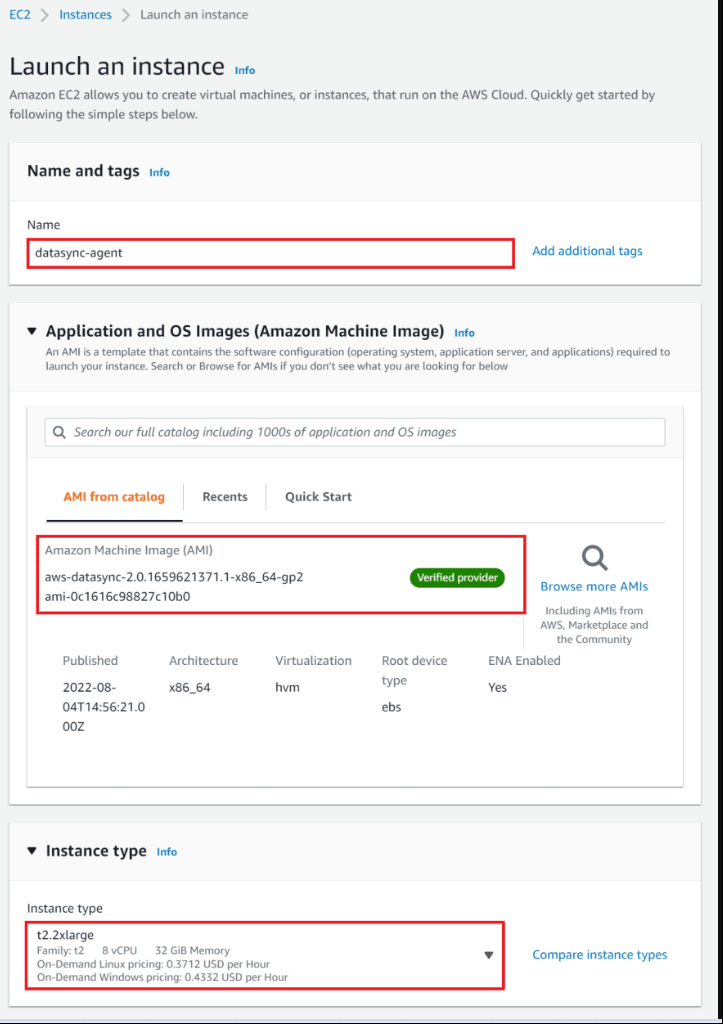
Enter the name of your EC2 instance.
Do not modify the "Application and OS image" section as AMI has already been chosen
For the "Instance type", you have to remember that the instance size must be at least 2xlarge (recommended ones are m5.2xlarge (for tasks to transfer up to 20 million files) or m5.4xlarge (for tasks to transfer more than 20 million files)
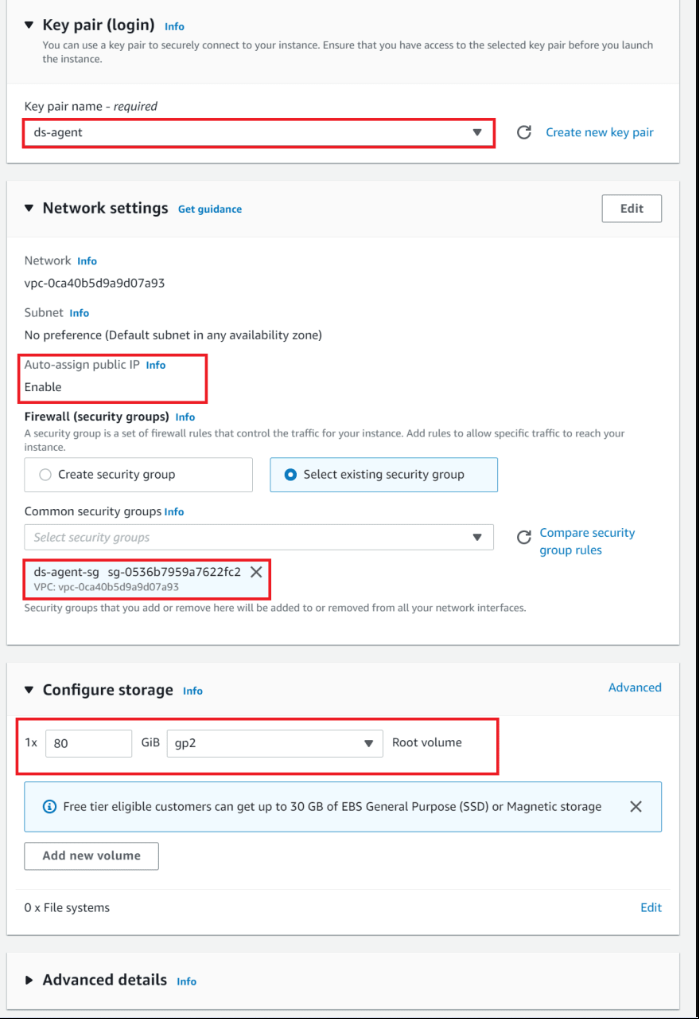
I will choose t2.2xlarge (32 GiB, 8vCPUs, 64-bit)Create a new key pair and save it
In the "Network settings" section, you can edit your VPC and subnet.
Enable Auto-assign Public IPFor the "Security group" section, make sure that the selected security group allows inbound access to HTTP port 80 from the web browser that you plan to use to activate the agent
In "Configure storage" section, ensure that there is at least 80 GB of disk space
Click the "Launch Instance" button
The initial state of the EC2 instance will be pending.
You have to wait until its status changes to running.
When your instance is running, it's assigned a public DNS and IP address that we will need later.To view the assigned DNS and IP address, click on the EC2 instance you just created and check the details. Kindly, note the DNS and IP address generated**.**
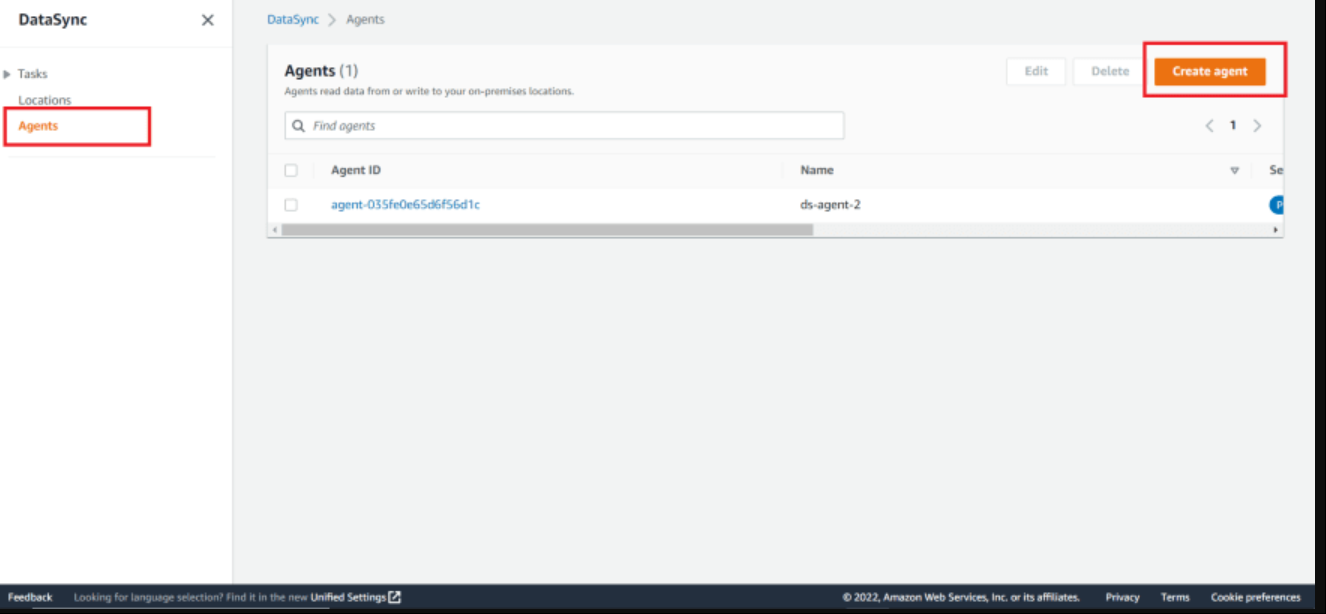
Now, as we deployed our DataSync agent, we need to activate it cause activation securely associates the agent that you deployed with your AWS account
In order to do that, go to the AWS DataSync console, choose Agents on the left-side bar and then click the "Create agent" button.
On the "Create agent" page the first section you see is "Deploy agent"
As we deployed our DataSync agent as an EC2 instance, choose "Amazon EC2"
The second section is the "Service endpoint" that the DataSync agent uses to communicate with AWS.
You have 3 options - public, VPC or FIPS.
Also, I need to mention that after you choose a service endpoint and activate the agent, you won't be able to change the endpoint
For simplicity, I am going to choose the public service endpoint.
It means that all communication from your DataSync agent to AWS occurs over the public internet
- The last section of this page is called "Activation key"
To obtain the agent's activation key, you have 2 options - do it automatically or manually.
We will do this automatically, and thus we need to specify the agent's address (to get the IP address, go to your EC2 running instances, choose the one we deployed earlier in this tutorial, and copy its public IP address)
Put copied IP to the "agent address" field.
After that, you can press the "Get key" button.
Your browser will connect to the IP address and get a unique activation key from your agent.
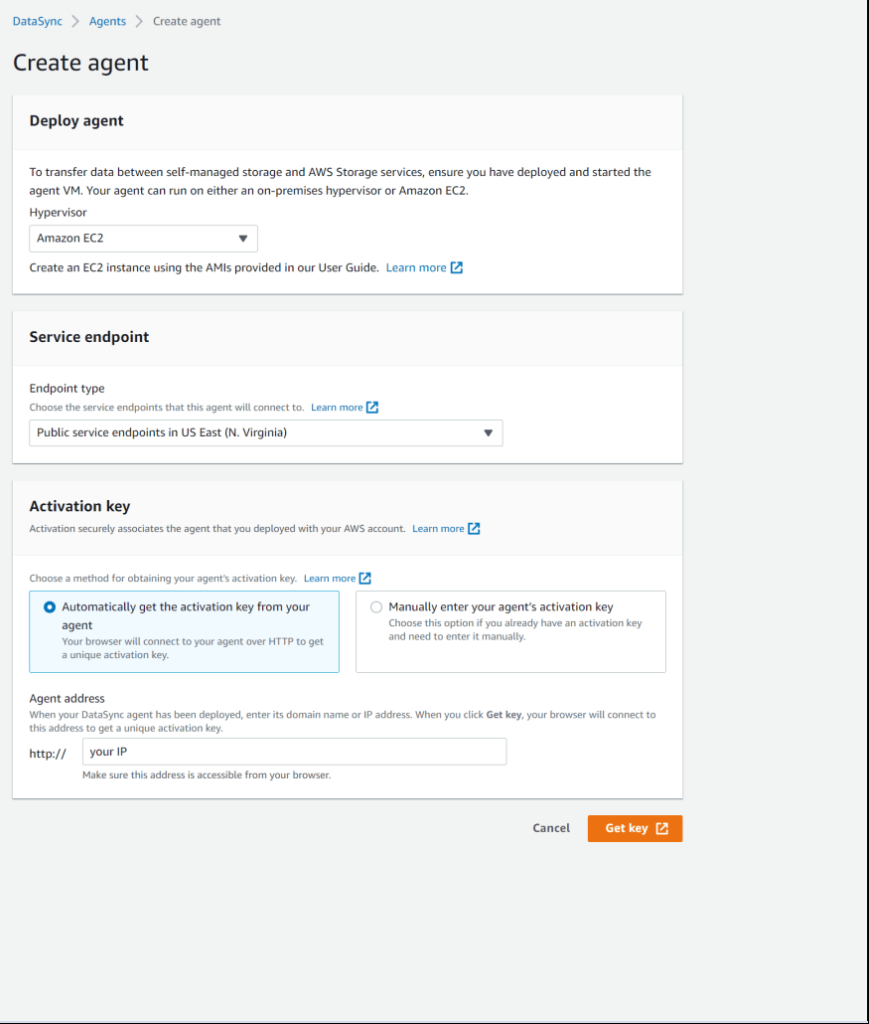
If activation succeeds, you will see a "Successfully retrieved activation key from agent" message with the activation key itself.
Then just type the agent name (not required) and press the "Create agent" button
The DataSync agent was successfully activated!
You should congratulate your self for reaching this point,
Next, we need to configure the Source and Destination locations.
On the DataSync console, go to "Locations", and click the "Create location" button
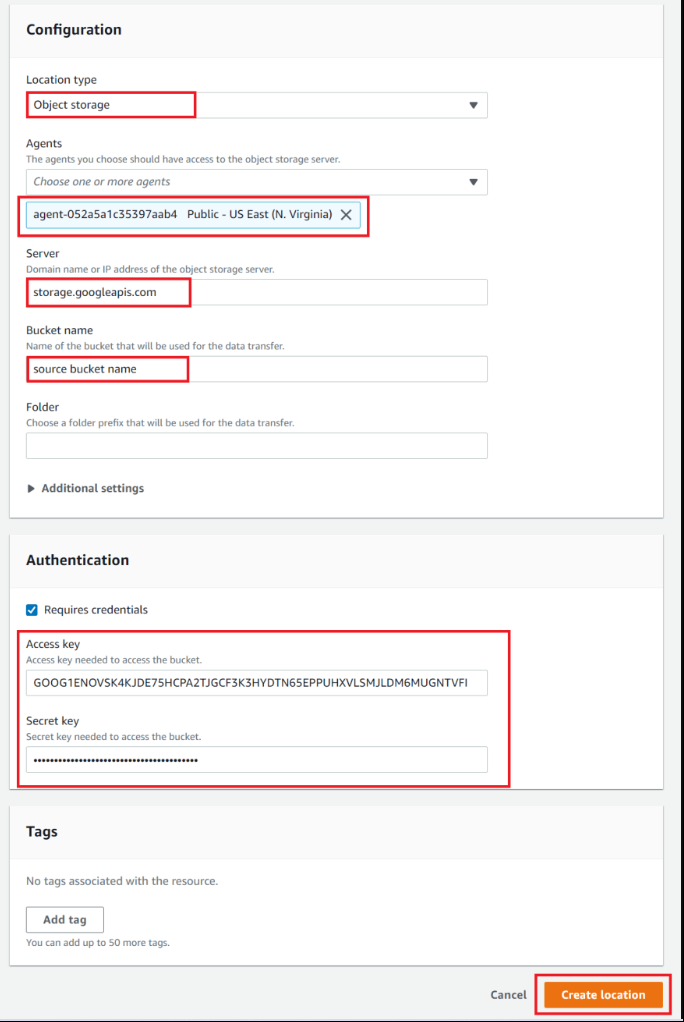
- For the location type, choose "Object storage"
A lot of new fields appeared.
Choose our previously activated agent in the "Agents" field
For "Server", type “storage.googleapis.com”
For "Bucket name", type the name of the cloud storage source bucket in GCP.
If you want, you can specify the folder that will be used for the data transfer (I will leave it empty)
In the "Authentication" section, you have to specify HMAC credentials that include access and secret keys.
DataSync agent uses an HMAC credential to authenticate to GCP and manage objects in the Cloud Storage bucket.
We are not going to talk about HMAC keys but here is the link to how you can create one
Enter your access & secret keys, and you are ready to press the "Create location" button
Now, let's go through the same process and create a destination location which is our AWS S3 Bucket.
Click the "Create location" button on the "Locations" page.
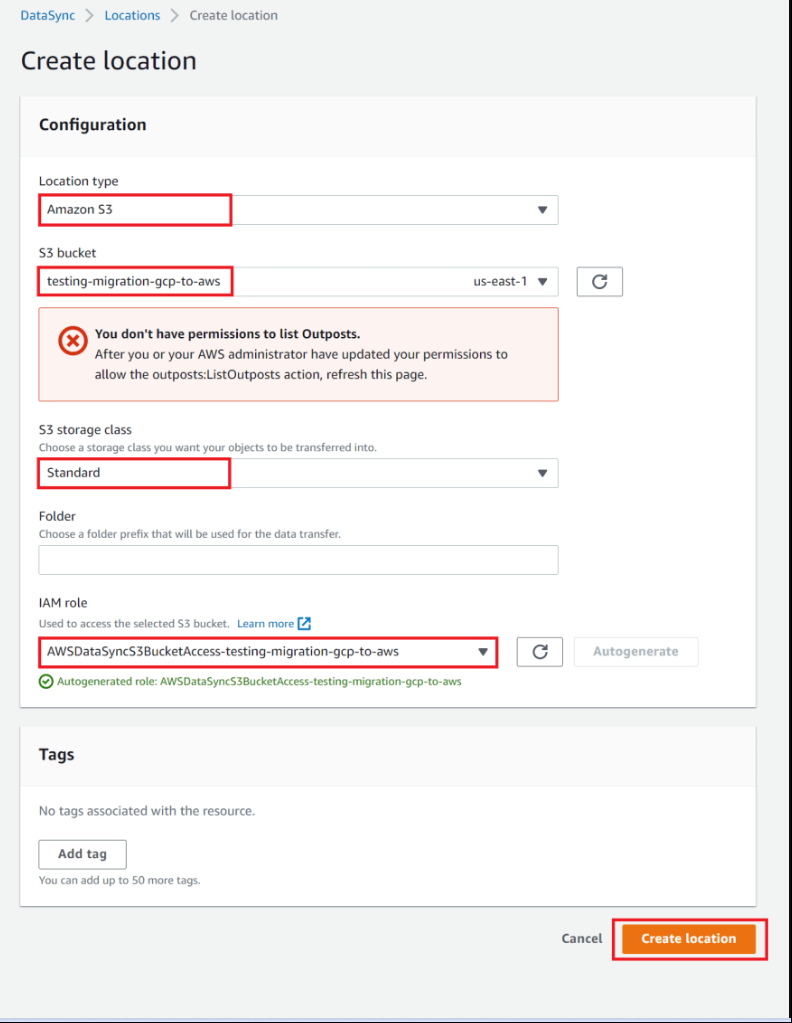
For the "Location type" field, choose "Amazon S3"
For the "S3 bucket", select the destination AWS S3 bucket
For the "Storage class" you can leave the default value - Standard.
In the "IAM role", choose a role with appropriate permissions
(DataSync needs to access the AWS S3 bucket in order to transfer the data to the destination bucket. This requires DataSync to assume an IAM role with appropriate permission and a trust relationship - here is the link)
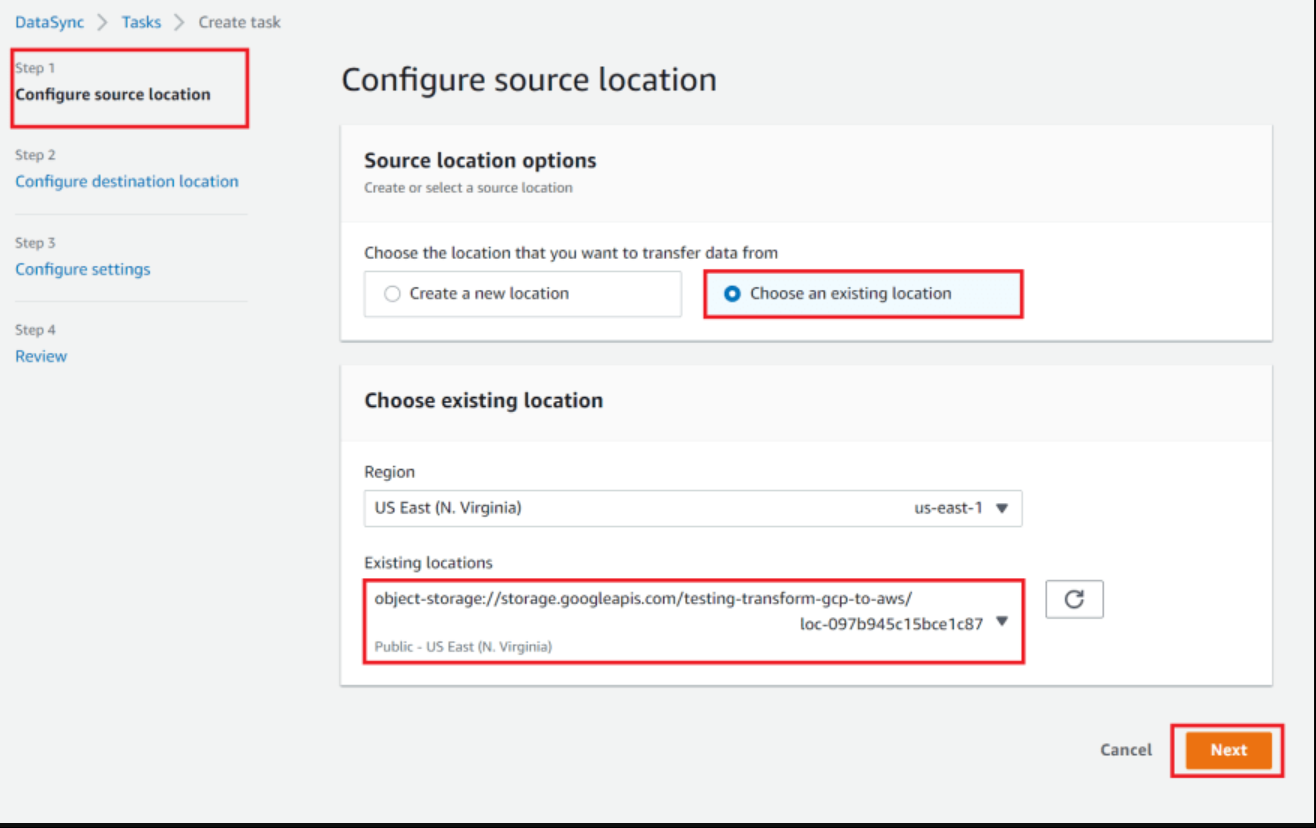
On the DataSync console, go to "Tasks", and click the "Create task" button
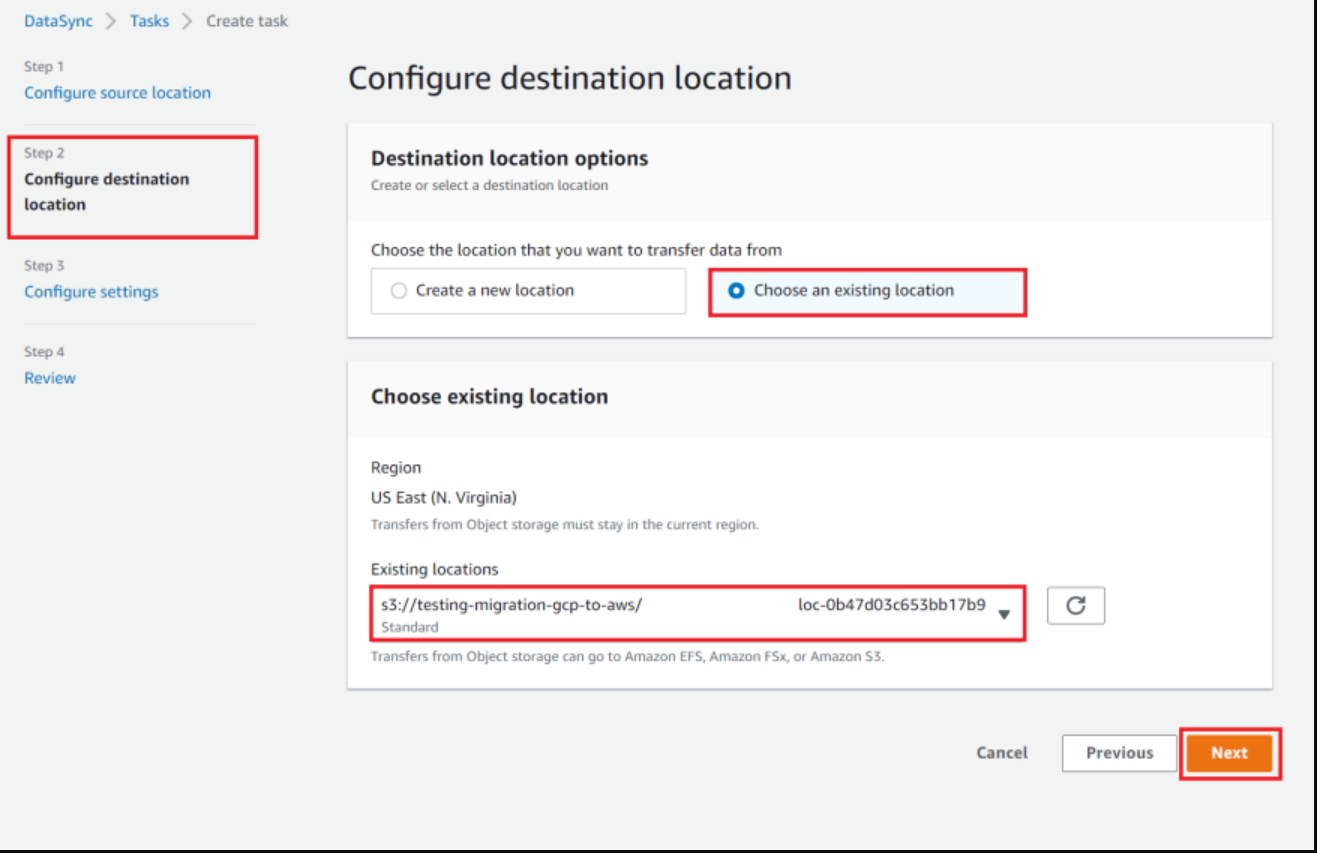
- In step 1 - "Configure source location", select "Choose an existing location"
For "Existing locations", choose our previously created GCS location
In the second step - "Configure destination location" do the same as in the previous step, but for "Existing locations" choose the S3 location
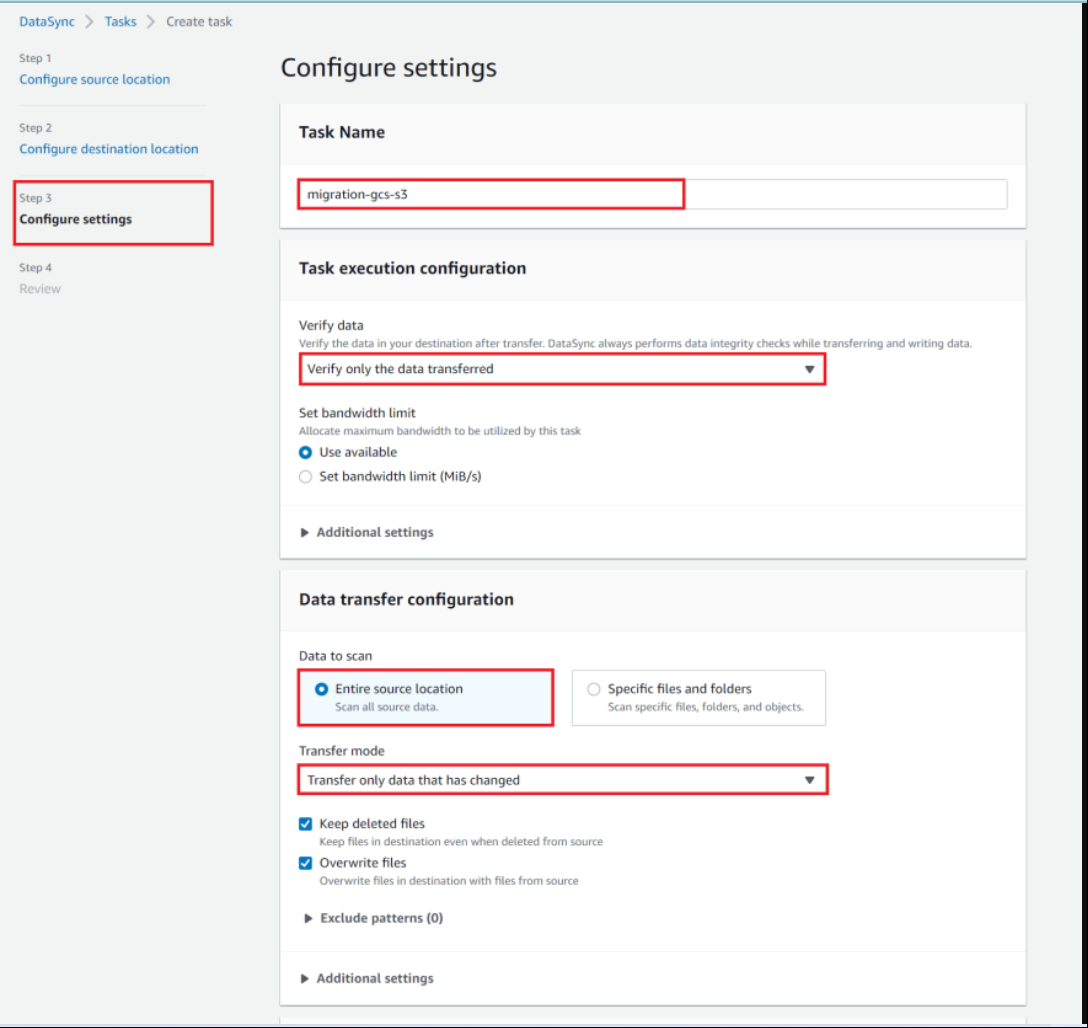
n the third step - "Configure settings", enter the task name
In the "Task execution configuration" section, for "Verify data" choose the needed option (I will leave the default one)
In the "Data transfer configuration" section, leave everything as default values (but you can adjust it if needed)
In the "Schedule" section, choose a schedule you want this task to be executed on
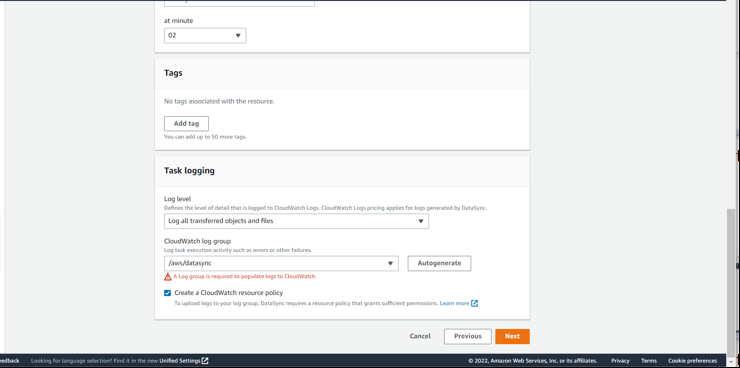
Add AWS CloudWatch log groups so you can track the progress of the data transfer, and if there is any error you can easily trace where the issue is from.
Once, that has started transferring
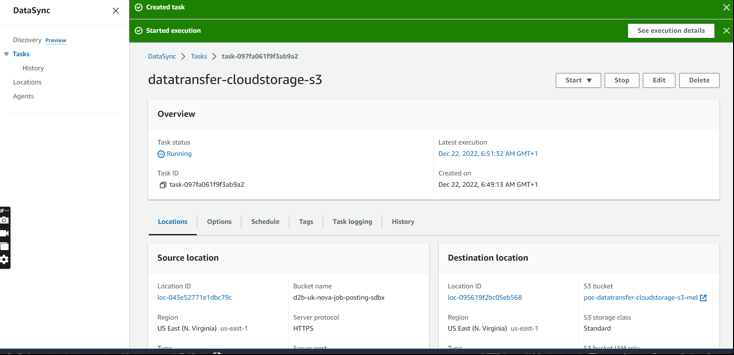
the task status will be running.
Next, you can view the progress of the data transfer
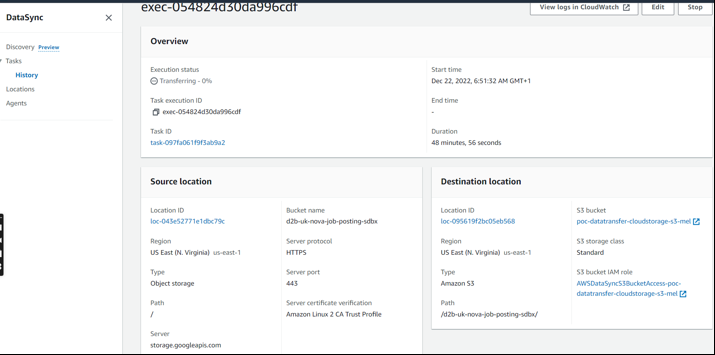
you can view logs on your Cloudwatch log groups
I hope you were able to follow through to the end, create your AWS DataSync task, and also migrate your data.
I will really appreciate your like and comments on the post.
Also, feel free to follow me on GitHub and Medium!
Reference:
Kairat Orozobekov -link
Subscribe to my newsletter
Read articles from Melody Egwuchukwu directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Melody Egwuchukwu
Melody Egwuchukwu
hi, I'm currently a Data Engineer Trainee at Data2bots. It has really been an exciting learning experience. I will be sharing helpful tips in the Data Engineering space as I progress.