How to use Gradient-Boosted Decision Trees in Python?
 Stylianos Kampakis
Stylianos Kampakis
Gradient-Boosted Decision Trees is one of the most popular techniques in machine learning and for a good reason. It is one of the most powerful algorithms in existence, works fast and can give very good solutions.
In this article, we will look at how to use Gradient-Boosted Decision Trees in Python for financial time series prediction. We will use the Scikit-learn library to build and evaluate our model.
What are Gradient-Boosted Decision Trees?
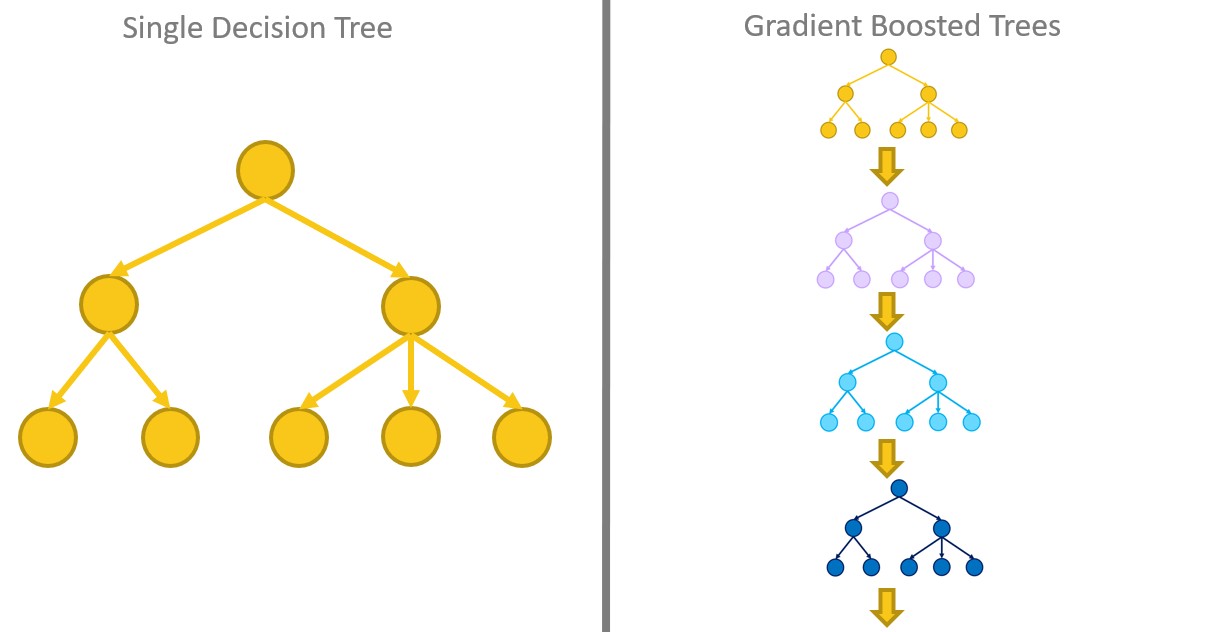
image source: https://thedatascientist.com/gradient-boosted-trees-python/
Gradient-Boosted Decision Trees are a machine-learning technique for optimizing the predictive value of a model through successive steps in the learning process. They are a type of supervised learning algorithm that is used to solve classification, regression, and ranking problems.
It is one of the most important algorithms in existence, works fast and can give very good solutions. There are 4 popular libraries for gradient boosted trees but now we'll focus on just one of them: the Scikit-Learn Library.
Data Preprocessing
Now, you will discover how to prepare your data for using with gradient boosting with the Scikit-Learn Library library in Python.
Here are some steps that you can follow to prepare your data for building a Gradient-Boosted Decision Tree model:
Load the data: You will need to load the data that you want to use for training and testing the model into your Python script. This can be done using functions such as
pandas.read_csv, which reads data from a CSV file, ornumpy.loadtxt, which reads data from a text file.Split the data into training and test sets: It is a good idea to split your data into a training set and a test set, so that you can evaluate the model on unseen data. You can use the
train_test_splitfunction from thesklearn.model_selectionmodule to randomly split the data into training and test sets.Preprocess the data: You may need to preprocess your data before training the model. This can include tasks such as scaling the data, handling missing values, and encoding categorical variables. The
sklearn.preprocessingmodule contains a number of functions that can be used for these purposes.Choose appropriate evaluation metrics: Depending on the type of problem you are trying to solve, you may need to choose different evaluation metrics to assess the performance of your model. For example, for a classification task, you may want to use metrics such as accuracy, precision, and recall, while for a regression task you may want to use metrics such as mean squared error or R2 score.
Train-test split: After splitting the data into training and test sets, you can start training the gradient-boosted tree model using the training data. You can use the
GradientBoostingClassifierorGradientBoostingRegressorclass from thesklearn.ensemblemodule to build the model. After training the model, you can use the test set to evaluate the model's performance.Fine-tune the model: Once you have trained the model, you may want to fine-tune it by adjusting the hyperparameters or adding more decision trees. You can use cross-validation to evaluate the performance of different hyperparameter combinations and choose the combination that performs the best.
Gradient Boosted Trees in Python with Scikit-Learn Library
Scikit-learn library

image source: https://blog.anybox.fr/introduction-au-machine-learning-avec-python-et-scikit-learn/
Scikit-learn (also known as sklearn) is a popular machine-learning library for Python. It provides a range of supervised and unsupervised learning algorithms in Python. Some of the popular algorithms it provides include:
Linear regression
Logistic regression
Support vector machines (SVM)
Decision trees
K-means clustering
Scikit-learn is designed to be easy to use and efficient, with a focus on being easy to understand and implement. It is built on top of NumPy, SciPy, and matplotlib, and integrates well with the rest of the scientific Python ecosystem, such as Jupyter notebooks and pandas.
Scikit-learn provides a number of tools for building gradient-boosted tree models.
To use gradient-boosted trees with scikit-learn, you can use the `GradientBoostingClassifier` or `GradientBoostingRegressor` classes from the `sklearn.ensemble` module. These classes provide a convenient interface for training gradient boosted tree models and making predictions with them.
**Here is an example** of how to use the `GradientBoostingClassifier` class to train a gradient boosted tree model for classification in Python:
`from sklearn.ensemble import GradientBoostingClassifier from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split # Load the breast cancer dataset X, y = load_breast_cancer(return_X_y=True) # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Create the gradient boosted tree model gbt = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, random_state=42) # Train the model on the training data` [`gbt.fit`](http://gbt.fit)`(X_train, y_train) # Evaluate the model on the test data accuracy = gbt.score(X_test, y_test) print("Test accuracy: {:.2f}".format(accuracy))`
In this example, we first load the breast cancer dataset from `sklearn.datasets`, which is a built-in dataset in [scikit-learn](https://thedatascientist.com/top-4-regression-algorithms-in-scikit-learn/). We then split the data into training and test sets using `train_test_split`. We create a `GradientBoostingClassifier` object with `n_estimators=100`, which means that the model will be trained using 100 decision trees. We set the `learning_rate` parameter to 0.1, which controls the contribution of each tree to the final prediction. Finally, we use the `fit` method to train the model on the training data, and the `score` method to evaluate the model on the test data.
This is just a simple example of how to use gradient boosted trees with scikit-learn. There are many other parameters that you can adjust to fine-tune the model, such as the depth of the decision trees, the minimum number of samples required to split a node, and the regularization term. You can find more information about these parameters in the documentation for the `GradientBoostingClassifier` and `GradientBoostingRegressor` classes.
### **Application of Gradient Boosted Trees in Financial Time Series Prediction**
Gradient Boosted Trees (GBTs) can be used to predict financial time series data, such as stock prices, currency exchange rates, or financial indices. GBTs are a type of ensemble machine learning algorithm that can be used for both regression and classification tasks, and are often used for predicting time series data due to their ability to handle high-dimensional data, their robustness to outliers, and their ability to achieve state-of-the-art performance on many tasks.
To use GBTs for financial time series prediction, you will first need to prepare your data by splitting it into training and test sets, and possibly preprocessing it to handle missing values or scale the data. You can then use the `GradientBoostingRegressor` class from the `sklearn.ensemble` module to train a GBT model for regression.
Here is an example of how to use the `GradientBoostingRegressor` class to train a GBT model for financial time series prediction in Python:
`from sklearn.ensemble import GradientBoostingRegressor from sklearn.model_selection import train_test_split # Load the financial time series data X = ... # features y = ... # target # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Create the GBT model gbt = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, random_state=42) # Train the model on the training data` [`gbt.fit`](http://gbt.fit)`(X_train, y_train) # Make predictions on the test data y_pred = gbt.predict(X_test) # Evaluate the model using a metric such as mean squared error from sklearn.metrics import mean_squared_error mse = mean_squared_error(y_test, y_pred) print("Test MSE: {:.2f}".format(mse))`
In this example, we first load the financial time series data and split it into training and test sets using `train_test_split`. We then create a `GradientBoostingRegressor` object with `n_estimators=100`, which means that the model will be trained using 100 decision trees. We set the `learning_rate` parameter to 0.1, which controls the contribution of each tree to the final prediction. Finally, we use the `fit` method to train the model on the training data, the `predict` method to make predictions on the test data, and `mean_squared_error` function from `sklearn.metrics` to evaluate the model's performance.
There are many other parameters that you can adjust to fine-tune the model, such as the depth of the decision trees, the minimum number of samples required to split a node, and the regularization term. You can also try using different evaluation metrics or using cross-validation to improve the model's performance.
## **Summary**
In this post you discovered how you can prepare your machine learning data for gradient boosting with **Scikit-learn library** in Python.
Specifically, you learned: What is scikit-learn library? How do you use scikit-learn in Python?
By following the steps outlined above, you can train and fine-tune a GBT model for financial time series prediction, and use it to make accurate predictions on unseen data.
Subscribe to my newsletter
Read articles from Stylianos Kampakis directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Stylianos Kampakis
Stylianos Kampakis
I am a data scientist. I have been involved in the area of data science, blockchain and artificial intelligence for more than a decade.