Package Organization Approaches in Go
 Tsvetan Dimitrov
Tsvetan Dimitrov
Inevitably, every Go developer asks the following question:
How do I organize my code?
There are many articles and approaches, and while some work well for some, they may not work well for others. Go has no official conventions and preferences on how you should structure your packages and where your non-code resources should reside.
Unlike other languages though, Go does not allow circular package imports. Projects thus require additional planning when grouping code into packages to ensure that dependencies do not import each other.
The goal of this article is not to specify a strict convention, but rather advocate building robust mental models for reasoning about your problem domains and how to represent them in your project layouts.
Project Layout Types
No approach is perfect, but there are a few that have gained widespread adoption. Please check the following resources:
Ben Johnson's article on Standard Package Layout.
Kat Zien's excellent talk, presentation and code samples can be found here.
Now we are going to explore what options are available for structuring your applications and distinguish between some good and some bad practices.
Flat Structure
Rather than spending time trying to figure out how to break your code into packages, an app with a flat structure would just place all of the
.gofiles in a single package.At first, this sounds awful, because we do not use packages that separate concerns while making it easier to navigate to the correct source files quickly.
Recommendations
When using a flat structure you should still try to adhere to coding best practices. Here are some helpful tips:
- You want to separate different parts of your application using different
.gofiles:
restaurant-app/
customer.go
data.go
handlers.go
main.go
reservation.go
server.go
storage.go
storage_json.go
storage_mem.go
- Global variables can still become problematic, so you should consider using types with methods to keep them out of your code:
package main
import(
"net/http"
"some"
"someapi"
)
type Server struct {
apiClient *someapi.Client
router *some.Router
}
func (s *Server) ServeHTTP(w http.ResponseWriter, r *http.Request) {
s.router.ServeHTTP(w, r)
}
Your
main()function should still be stripped of most logic outside of setting up the application.A possible improvement to the flat structure is to again put all of your code into a single package, but separate the
mainpackage where you define the entry point of the application. This would allow you to use the commoncmdsub-directory pattern:
restaurant-app/
cmd/
web/
# package main
main.go
cli/
# package main
main.go
# package restaurantapp
server.go
customer_handler.go
reservation_handler.go
customer_store.go
- This project layout is usually suitable for small libraries or CLI tools and very simple projects.
Anti Pattern: Group by Function (Layered Architecture)
Layered architecture patterns are n-tiered patterns where the components are organized in layers.
This is the traditional method for designing most software and is meant to be self-independent, i.e. all the components are interconnected, but do NOT depend on each other.
We have all heard about the famous 3-tier MVC (Model-View-Controller) architecture where we split our application into the following 3 distinct layers:
— Presentation / User Interface (View)
— Business Logic (Controller)
— Storage / External Dependencies (Model)
This architecture translated into our example project layout would look like this:
restaurant-app/
# package main
data.go
handlers/
# package handlers
customers.go
reservations.go
# package main
main.go
models/
# package models
customer.go
reservation.go
storage.go
storage/
# package storage
json.go
memory.go
...
This type of layout should NOT compile at all due to circular dependencies.
The
storagepackage uses themodelspackage to get the definitions for aCustomerand aReservationand themodelspackage uses thestoragepackage to make calls to the database.Another disadvantage of this structure is that it does not guide us about what the application does (at least not more than the flat structure).
This type of layout is strongly NOT recommended when writing applications in Go so try to avoid it.
Anti Pattern: Group by Module
Grouping by Module offers us a slight improvement over the layered approach:
reservationapp/
customers/
# package customers
customer.go
handler.go
# package main
main.go
reservations/
# package reservations
reservation.go
handler.go
storage/
# package storage
data.go
json.go
memory.go
storage.go
...
Now our application is structured logically, but that is probably the only advantage of this approach.
It is still hard to decide, e.g., if
reservationshould go to thecustomerspackage because they are customer reservations or are they suited for having their own package.Naming is worse because we now have
reservations.Reservationandcustomers.Customerwhich introduces stutter.Worst of all is the possibility of circular dependencies again if the
reservationspackage needs to reference thecustomerspackage and vice versa.
Group by Context (Domain Driven Design)
This way of thinking about your applications is called Domain Driven Design (DDD).
In its essence it guides you to think about the domain you are dealing with and all the business logic without even writing a single line of code.
Three main components need to be defined:
— Bounded contexts
— Models within each context
— Ubiquitous language
Bounded Contexts
A bounded context is a fancy term defining limits upon your models. An example would be, e.g., a User entity that might have different properties attached to it based on the context:
A
Userin a sales department context might have properties likeleadTime,costOfAquisition, etc.A
Userin a customer support context might have properties likeresponseTime,numberOfTicketsHandled, etc.This showcases that a
Usermeans different things to different people, and the meaning depends heavily on the context.
The bounded context also helps in deciding what has to stay consistent within a particular boundary and what can change independently.
- If we decide later on to add a new property to the
Userfrom the sales department context, that would not affect theUsermodel in the customer support context.
Ubiquitous Language
Ubiquitous Language is the term used in Domain Driven Design for the practice of building up a common, rigorous language between developers and users.
This language is based on the Domain Model used in the software, and it evolves up to the point of being able to express complex ideas by combining simple elements of the Domain Model.
Categorizing the building blocks
Based on the DDD methodology we will now start to reason about our domain by constructing its building blocks.
If we take our Restaurant Reservation System example, we would have the following elements:
Context: Booking Reservations.
Language: reservation, customer, storage, …
Entities: Reservation, Customer, …
Value Objects: Restaurant, Host, …
Aggregates: BookedReservation
Service: Reservation lister/listing, Reservation adder/adding, Customer adder/adding, Customer lister/listing, …
Events: ReservationAdded, CustomerAdded, ReservationAlreadyExists, ReservationNotFound, …
Repository: ReservationRepository, CustomerRepository, …
Now after defining those blocks we can translate them into our project layout:
restaurant-app/
adding/
endpoint.go
service.go
customers/
customer.go
sample_customers.go
listing/
endpoint.go
service.go
main.go
reservations/
reservation.go
sample_reservations.go
storage/
json.go
memory.go
type.go
The main advantage here is that our packages now communicate what they PROVIDE and not what they CONTAIN.
This makes it easier to avoid circular dependencies, because:
addingandlistingtalk tostorage.storagepulls fromcustomersandreservations.Model packages like
reservationsandcustomersdo not care aboutstoragedirectly.
Group by Context (Domain Driven Design + Hexagonal Architecture)
So far we managed to structure our application according to DDD, eliminated circular dependencies and made it intuitive what each package does only by looking at the directory and file names.
We still have some problems though:
How can we start a version of our application that contains sample data*?*
In our current version sample data is bundled with the application’s entry point in
main.goand we have only onemain.go.We have NO option to run a sample data version separately from the main version of the application.
Maybe we want a pure CLI version of the application where instead of adding reservations through HTTP requests, we want the command line to prompt us for each reservation property?
Hexagonal Architecture
This type of architecture distinguishes the parts of the system which form your core domain and all the external dependencies are just implementation details.
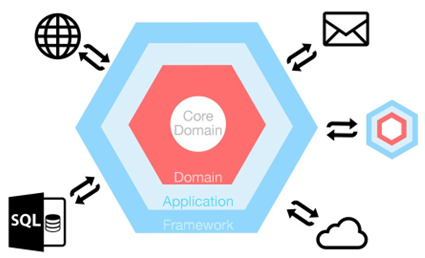
Fig. 1: Hexagonal Architecture Layers Diagram
External dependencies could be databases, external APIs, mail clients, cloud services etc., anything that your application interacts with.
The problem this solves is giving you the ability to change one part of the application without affecting the rest, e.g., swapping databases or transport protocols (HTTP to gRPC).
This is not in any way similar to the MVC (layered) model, because:
- MVC tends to look at inputs and outputs in a top to bottom way (input -> main logic -> output).
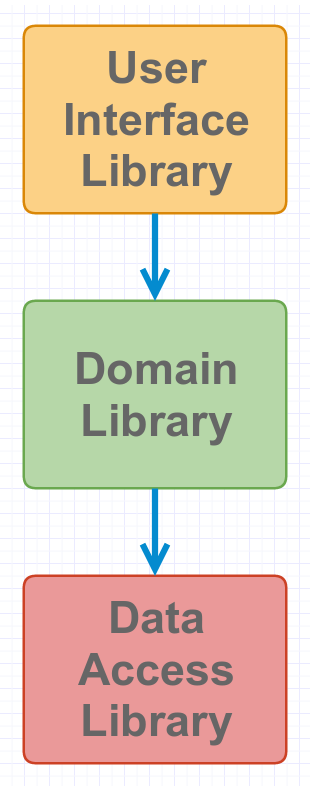
Fig. 2: Layered Architecture Dependency Direction
- Hex treats inputs and outputs on the same level. It does not care if something is an input or an output, it is just an external interface.

Fig. 3: Dependency Inversion Direction
- The key rule in the hex model is that dependencies only point INWARDS (only outer layers depend upon inner layers and not the other way around). This is called the Dependency Inversion Principle. Check this excellent article by Martin Fowler to learn more.
Recommendations
Based on this approach our project structure could look like this:
restaurant-app/
cmd/
# HTTP server
restaurant-server/
main.go
# CLI app
restaurant-cli/
main.go
# HTTP server with seeded data
restaurant-sample-data/
main.go
sample_reservation.go
sample_customers.go
pkg/
adding/
reservation.go
endpoint.go
service.go
listing/
customer.go
reservation.go
endpoint.go
service.go
transport/
http/
server.go
main.go
storage/
json/
customer.go
repository.go
reservation.go
memory/
customer.go
repository.go
reservation.go
To solve the multiple app version binaries problem we utilize the cmd sub-directory pattern which we mentioned as an improvement to the flat structure layout.
We are now able to produce 3 different binaries used to serve different purposes:
restaurant-server- main version of the app deploying an HTTP server.restaurant-cli- a CLI version with a removed transport layer offering a CLI interface for interaction.restaurant-sample-data- a sample data seeded version used mainly for testing.
We introduce the pkg package which separates our Go code from the cmd binaries and non-code resources, e.g. DB scripts, configs, documentation, etc. which should be found on the same level under the project's root directory.
NOTE
Using the
cmdandpkgdirectories has become somewhat of a trend in the Go community. It is not a standard by any means, but a good recommendation that should be considered.
According to DDD we keep the
addingandlistingpackages that represent our core domain.We remove
reservationsandcustomerspackages and instead introduce models in each of the core domain packages, e.g.,adding.Reservation,adding.Customer,listing.Reservation, etc.The advantage here is that we have separate representations per model according to the bounded context (
addingorlisting). This allows decoupled model modification and avoids circular dependencies.We introduce a
transportpackage which contains all transport protocol implementations, e.g. HTTP or maybe gRPC in their respective sub-packages.The
storagepackage is another bounded context that features its model representations on a storage level and sub-packages for storage implementations, e.g.json,memory, etc.Again,
main.goties everything together and should not contain any logic that would require testing.
Conclusion
Unfortunately, there is no single right answer, but at least we outlined some examples of problem domains, how to reason about them and how to translate that reasoning into Go package organization. Great freedom comes with great responsibility! Use the following guidelines wisely:
“Make everything as simple as possible, but not simpler.” — Albert Einstein.
Maintain consistency.
Flat and simple is OK for small projects.
Avoid global scope and
init().Separate depended upon code into its own package.
Two top-level directories:
—cmd(for your binaries)
—pkg(for your packages)All other project files (DB scripts, fixtures, resources, docs, Docker configs, etc.) — should reside under your project’s root directory.
Group by context, not generic functionality. Try DDD/Hex.
mainpackage initializes and ties everything together.
Subscribe to my newsletter
Read articles from Tsvetan Dimitrov directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by