Handling Tens of Billions of Threat Intelligence Data with NebulaGraph Database
 NebulaGraph Database
NebulaGraph Database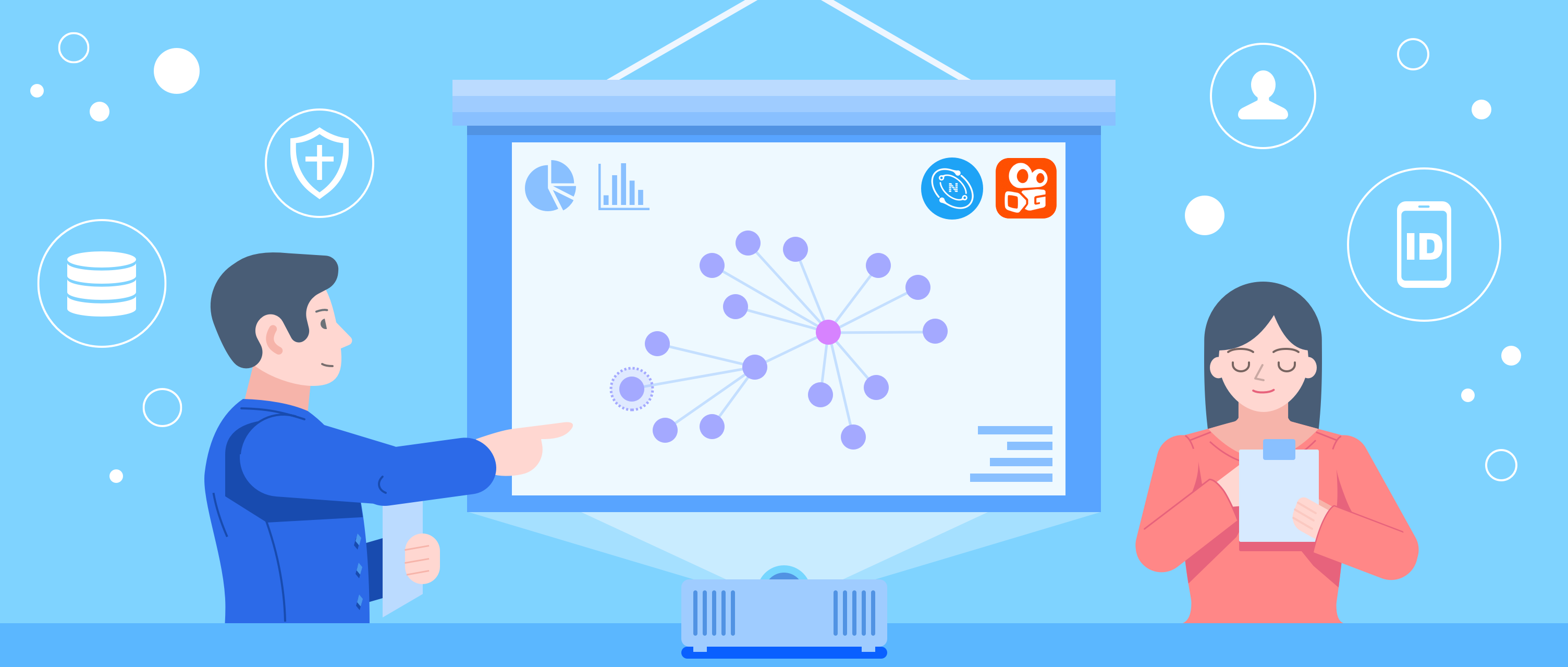
About Kuaishou
Kuaishou is a leading content community and social platform with its mission to be the most customer-obsessed company in the world. Kuaishou has relentlessly been focusing on serving its customers and creating value for them through the continual innovation and optimization of its products and services.
Why Graph Database?
Traditional relational databases perform poorly in handling relational operations of complicated data. As the volume and relationship depth of data increase, relational databases are not capable of handling computing effectively.
Therefore, to better reflect the relationships between data, enterprises need a database that can store relationship information as entities and flexibly expand the data model. Graph databases are what they need.
Compared with traditional relational databases, graph databases have the following two advantages:
One is that graph databases can represent the relationships between data.

From the graph model shown in the preceding figure, you can see that graph databases are designed to reflect the relationships in an intuitive way based on a graph model. Its model expression based on the relationship between entities makes graph databases interpretable.
The other is that graph databases can handle relationships between data.
High performance: In traditional relational databases, relational data is mainly handled by the JOIN operation. As data volume and relationship depth increase, because of the constraints of multi-table joins and foreign keys, large additional overhead will be caused to a traditional relational database, which will seriously lower its performance. The bottom layer of a graph database is adapted to the data structure of the graph model, which can speed up data queries and data analytics.
Flexibility: Graph databases support flexible data models. Users can adapt their data model to their business needs, such as adding or deleting vertices and/or edges, and expanding or shrinking the graph model. Graph databases enable users to frequently change data schema.
Agility: The graph models supported by graph databases are intuitive. The graph models support Test-Driven Development. Every time the graph database is built, functionality testing and performance testing can be performed, which is compliant with the agile development methodology, and can help improve production and delivery efficiency.
Because of these advantages, graph databases can be widely used in the fields of financial anti-fraud, public security, criminal investigation, social network, knowledge graph, data lineage, operation and maintenance of IT assets, and threat intelligence.
The Kuaishou threat intelligence Team aims to integrate security data in the entire chain that is composed of mobile clients, Web clients, Cloud clients, Advertising Alliance Data, and small programs so that the company has a unified basic security capability, thereby empowering the business of the company.
threat intelligence is characterized by diversity of entities, complexity of relationships, richness of data labels, and so on. Therefore, it is most appropriate to use a graph database to store threat intelligence data.
Why NebulaGraph?
Through demand collection and researches, the Kuaishou threat intelligence Team finally decided to use NebulaGraph as its graph database solution in the production environment.
Collect Demands
To choose a graph database solution for Kuaishou, writing data and querying data are the main focus.
About writing data: offline + online
The database needs to support batch offline import of all data generated each day. On the platform, tens of billions of relational data may be generated each day, and all data needs to be written to the database in hours.
The database needs to support real-time data writing. Flink consumes data from Kafka. After being processed, the data will be directly imported from Flink into the graph database in real time. Hundreds of thousands of QPS needs to be supported.
About querying data: The database needs to support online real-time queries in milliseconds. 50 thousand of QPS needs to be supported.
Filtering and querying vertices and edges by property
Querying multiple hops of relationships
Some basic graph data analysis capabilities
- Algorithms to find the shortest path from one vertex to others in a graph, and so on
In summary, the selected graph database solution for the big data architecture needs to have three basic capabilities: writing data in real time and offline, querying online graph data, and basic OLAP capability, which require the graph database to support basic OLAP and online, concurrent, and low-latency OLTP.
Select a Solution
Based on the requirements identified above, while selecting a graph database solution, we mainly considered the following factors:
The volume of data that the graph database can handle must be large enough, because enterprise-level applications usually generate tens of billions or even hundreds of billions of graph data.
The cluster must be scalable, because it is necessary to scale out the cluster online without stopping the service in the production environment.
Queries must be executed in milliseconds, because the database needs to meet the performance requirements of online services, and the increase of the graph data volume should not lower the query performance.
The database needs to be easily connected with big data solutions such as HDFS and Spark, and a graph computing platform can be built based on it later.
Features of NebulaGraph

High performance: Reading and writing data in milliseconds.
Scalability: Supporting scaling in and out and storing graphs of an ultra-large size.
Engine architecture: Separation of compute and storage.
Graph data models: Vertices and edges. Supporting modeling on properties of vertices or edges.
Graph query language: nGQL, a SQL-like query language, easy to learn and use. It can meet complicated business needs.
Provision of diversified tools for importing and exporting data.
The NebulaGraph community is highly active.
NebulaGraph outperforms JanusGraph and HugeGraph in query performance.
All these features of NebulaGraph and that it precisely answers to our needs and scenarios make us finally decide to use NebulaGraph in our production environment.
Modeling Graph Data for Threat Intelligence
As shown in the following figure, from an intelligence point of view, the difficulty of countermeasures from bottom to top for layered defense increases.

On each layer, the attackers and defenders are previously in separate adversarial actions. Now, after application of a graph database, the entity IDs on each layer can be linked together through a specific relationship to form a three-dimensional hierarchical network. By using such a network, companies can quickly grasp the attack methods, cheating tools, gang characteristics, and other information.
Therefore, graph modeling based on security data can turn the original two-dimensional plane recognition into a three-dimensional recognition, which can help our company identify attacks and risks more clearly and accurately.
Basic Graph Model
The main purpose of graph modeling for threat intelligence is identifying risks of a dimension not only by its status and properties, but also by considering the dimension from the network point of view, which means the data relationship in heterogeneous graphs and in isomorphic graphs should be used to identify the risk of the dimension.
Take the device risk as an example. A device may involve the network layer, device layer, account layer, and user layer. On each layer, the device can be represented by an entity ID. With the help of the graph database, we can complete a three-dimensional risk recognition for a device, which is very helpful for risk identification.

The preceding figure shows the basic graph modeling for threat intelligence data. It constitutes a knowledge graph based on threat intelligence.
Dynamic Graph Model
In addition to the elements in the basic graph model, we also need to consider that each relationship is time-sensitive, that is, a relationship that exists in interval A may no longer exist in interval B. Therefore, we hope that the graph database for threat intelligence can truly reflect the real-world relationship across different time intervals.
This means that the database must be able to return data of different graph models according to the query time interval, which we call dynamic graph models.
To model dynamic data, a question arises: What edge types should be returned according to the query time interval?

As shown in the preceding figure, in query time interval B, C, or D, the specified edge should be returned, but in query time interval A or E, this edge should not be returned.
Weighted Graph Structure
To detect gangs that commit underground economy crimes or evildoers, this situation often occurs: A device may be associated with many accounts, some of which are often used by criminals themselves, and the others are bought by them for illegal live streaming. To cooperate with the public security or legal affairs departments in cracking down on illegal activities, we need to accurately distinguish which accounts are commonly used by the criminals and which are just accounts they bought for illegal actions.
This is why the relationship between the account and the device should be weighted: If an account usually uses a device, it means that the account is strongly linked with the device, so the weight of the relationship is higher; If an account uses the device to commit underground economy crimes or to do live streaming, it means that the account is weakly linked with the device, and accordingly, the weight of this relationship is lower.
Therefore, our edges do not only have time properties but also weights.
In summary, a weighted time-evolving graph model is finally created for threat intelligence data.
Architecture and Optimization of Threat Intelligence Service Based on Graph Database
The following figure shows the overall architecture of the threat intelligence service.

Overall Architecture of Threat Intelligence Service
In this architecture, there is an integrated intelligence query platform based on the graph database. Its architecture is shown in the following figure.

Overall Architecture of Integrated Intelligence Query Platform
NOTE: AccessProxy for access from an enterprise private network to IDC, and kngx for direct invocation inside IDC.
Optimization of Writing Data Offline
The relational data we need to build is probably updated in billions every day. It is a very challenging task to ensure that such a large amount of data can be written within hours, that data anomalies can be sensed, and that data will not be lost. The optimization is focused on failure retry, dirty data discovery, and the import failure alarm strategy.
In the data import process, various factors such as dirty data, server bouncing, crash of the nebula-graphd process, and writing data too fast may cause a failure in batch writing data. By using the synchronous client API, multi-level retries, and exit-after-failure strategies, we have solved the problems of writing failures or incomplete batch writing caused by bouncing or restarting on the server side.
High-Availability and Switching of Dual Cluster
At Kuaishou, two graph database clusters are deployed, one for online and the other for offline. The synchronous dual write technology is adopted to write data to both clusters. The online cluster is to provide online RPC services, and the offline one provides CASE analysis and WEB query services. Both clusters are independent from each other.
Besides, the status monitoring module and the distribution module of the dynamic configurations are connected, that is, when a slow query or a failure occurs in one cluster, the distribution module of the dynamic configurations will complete the cluster switching seamlessly.
4.3 Cluster Stability
Our data architecture team has done research, maintenance, and improvement on the Community Edition of NebulaGraph.
NebulaGraph adopts the separation of computing and storage design. It is composed of three services: Meta, Graph, and Storage. They are responsible for metadata management, computing, and storage respectively.

Overall Architecture of NebulaGraph
The storage layer of NebulaGraph is the base of the graph database engine. It supports multiple store types. We adopt the classic implementation, RocksDB implemented in C++ for KV store and the Raft consensus mechanism, which enables the cluster to scale in or out dynamically.

Architecture of Storage Layer
We have fully tested the storage layer, improved its code, and optimized its parameters, including optimizing the Raft heartbeat mechanism, improving the leader election mechanism and the log offset implementation, and tuning the Raft parameters, to improve the failure recovery time of a single cluster. We also optimized the failure retry mechanism on the client side. All these make our graph database more user-friendly. For example, before optimization, disconnections would be caused by failures, but now the database can be recovered in milliseconds after failures.
About the monitoring and alarm system, we have implemented monitoring of multiple levels of the cluster. The overall monitoring architecture is shown in the following figure.

Cluster Monitoring Architecture
The following metrics are monitored:
Hardware: CPU busy, disk utility, memory, network, and so on.
The interface of the Meta, Storage, and Graph services in the cluster, and the online status and distribution of the partition leaders.
Evaluation of the availability of the cluster from the user's perspective.
Collecting and monitoring metrics of Meta, Storage, RocksDB, and Graph in a cluster
Slow queries.
Optimization of Super-Node Queries
In a real-world graph model, the out-degree of vertices generally conform to the characteristics of the power-law distribution, so super-nodes (vertices having out-degree of millions or even tens of millions) during a graph traversal will cause obvious slow queries. How to stabilize the time consumption of online queries and to avoid extremely time-consuming occurrence is the problem we need to solve.
The solution to the super-nodes problem in a graph traversal is reducing the scale under acceptable business conditions. Here is how it is implemented:
Using an appropriate LIMIT clause to truncate the result.
Sampling edges at a specified ratio.
Now, let's look at how a super-node query is optimized.
Using LIMIT
Prerequisite
From a business perspective, using LIMIT to truncate the result of each hop query is acceptable. Take the following queries as an example.
# Executing the LIMIT clause until the end.
go from hash('x.x.x.x') over GID_IP REVERSELY where (GID_IP.update_time >= xxx and GID_IP.create_time <= xxx) yield GID_IP.create_time as create_time, GID_IP.update_time as update_time, $^.IP.ip as ip, $$.GID.gid | limit 100
# Executing the LIMIT clause on the query result first, and then executing the next query.
go from hash('x.x.x.x') over GID_IP REVERSELY where (GID_IP.update_time >= xxx and GID_IP.create_time <= xxx) yield GID_IP._dst as dst | limit 100 | go from $-.dst ..... | limit 100
Before Optimization
On the storage layer, all the outgoing directed edges from a vertex are traversed, and on the graph layer, the LIMIT clause is executed until the result is returned to the client, where a lot of time-consuming operations are unavoidable. In addition, although NebulaGraph supports configuring the maximum out-degree scanned for a vertex on the storage layer level (max_edge_returned_per_vertex), it does not support flexibly specifying LIMIT on the query statement level, and in a multi-hop query for the out-degree of multiple vertices, it is impossible to make precise restrictions on the statement level.
How to Optimize
The one-hop GO traversal is executed into two steps:
Step 1: Scan all outgoing directed edges (destVertex) of a vertex (srcVertex), and obtain the properties of the edges.
Step 2: Obtain the property values of all the destVertex.
For a multi-hop GO traversal, each hop query can be executed in two cases:
Case 1: Only Step 1 is executed.
Case 2: Both Step 1 and Step 2 are executed.
Step 2 consumes most of the time for the entire query. For example, a RocksDB iterator operation is needed to query each property of destVertex, which takes 500 μs if no cache hit occurs. Therefore, for those vertices with a large amount of outgoing directed edges, executing the LIMIT clause before Step 2 is key. In addition, executing the LIMIT clause in Step 1 has greater benefits to the super-nodes.

The following table lists the cases whether a LIMIT clause can be used to optimize the query and the benefits.

NOTE: N represents the out-degree of a vertex; n represents LIMIT n ; scan represents the consumption of scanning the out-degree; get represents the consumption of obtaining the vertex properties.
Test Result
As can be seen from the preceding table, the query in Case 1 or Case 2 can be improved a lot by optimizing the LIMIT clause. Case 2 is suitable for security business queries. For example, the following table shows the test result against LIMIT 100 in Case 2 on a cluster deployed on three machines, each equipped with a single disk of a 900 GB data storage capacity (in the case that no RocksDB cache hit occurs).

The test results show that after optimization, the time consumption of super-node queries is greatly reduced.
Sampling Edges
For those scenarios where optimizing the LIMIT clause cannot be used, we can use the reservoir sampling algorithm to solve them. NebulaGraph supports configuring the maximum out-degree of each vertex on the nebula-storage process level and enabling the reservoir sampling algorithm. Based on these features, we decided to enable the graph database to support the following features:
When the reservoir sampling algorithm is enabled for the nebula-storaged process,
max_iter_edge_for_samplecan be configured to specify the number of edges to be scanned. By default, all the edges will be scanned.Graph service supports sampling edges at each hop of a GO query.
Configuration of
enable_reservoir_samplingandmax_edge_returned_per_vertexcan be effective on the session level.
With all these features, the business side can adjust the sampling ratio more flexibly to control the traversal scale to achieve the smoothness of the online service.
Improving and Optimizing Query Clients
The open-source NebulaGraph has its own clients. We have improved an optimized these clients in the following two ways to make them suitable for projects at Kuaishou:
Connection pooling: The underlying interface of the clients provided by NebulaGraph requires creating and initializing a connection, executing the query, and closing the connection for each query. In high-frequency query scenarios, frequent creation and closing of connections is detrimental to the performance and stability of the system. In practice, we have adopt connection pooling technology to re-encapsulate the clients and monitor the entire life cycle of each connection to reuse and share connections, which improves business stability.
Automatic failover: Through regular detection and monitoring the abnormalities in the stages of connection creation, initialization, querying, and destroying, we have implemented the real-time discovery and automatic removal of faulty nodes in the graph database cluster. If the entire cluster is unavailable, the service can be migrated to the backup cluster in seconds, which reduces the potential impact of cluster failures on the availability of the online service.
Visualizing and Downloading Query Result
For those queries for fixed relationships (with fixed nGQL statements), the front end will display the returned results in a customized graphical interface, as shown in the following figure.

As shown in the preceding figure, ECharts is adopted to display graph data on the front end, and some optimizations have been made in loading and displaying data.
Problem 1: The relationship graph needs to be able to display the details of each vertex, but the chart provided by ECharts can only display the values. Solution: Modifying the source code to add a click event for each vertex by adding a modal to display more details.
Problem 2: After the click event is triggered, the relationship graph will be in a rotating state for a long time, so it may not be able to identify which node is clicked. Solution: Obtaining the position of each vertex in the window when the graph is first rendered, and fixing the position of each vertex after the click event is triggered.
Problem 3: If a graph contains a lot of vertices, they will be displayed in a crowded way. Solution: Enabling users to use mouse to graphically zoom, pan, and roam the graph.
For those queries for flexible relationships (with flexible nGQL statements), we deployed NebulaGraph Studio to visualize the results, as shown in the following figure.

Practice of Graph Database in Threat Intelligence
Based on the architecture and optimization of the graph database, we provide two access methods, Web and RPC, which mainly support the following services at Kuaishou:
Tracking and tracing, fighting illegal activities offline, and analysis of underground economy crimes at Kuaishou Security.
Risk control and anti-cheating of business security
For example, the characteristics represented by graph data of group controlled devices distinguish from those of normal devices, as shown in the following figure.

Normal IP addresses and devices should be like this.
The following figure shows how group controlled devices are represented in a graph.

The vertex at center represents an IP address. All the vertices connected with it represent devices that are group controlled.
Conclusion and Expectations

Ensuring and improving stability: Implementing real-time synchronization and automatic access switching of HA clusters across availability zones to guarantee an SLA of 99.99%.
Improving performance: Planning to update the hardware storage solution of RPC and AEP and optimize the query execution plan
Enabling the graph computing platform to communicate with the graph query engine: Building an integrated platform for graph computing, graph learning, and graph query.
Supporting real-time detection: Writing of real-time relationships and identifying real-time risks.
Subscribe to my newsletter
Read articles from NebulaGraph Database directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by