Base58 - What Is it? Why Use It?
 Kirk Haines
Kirk Haines
As programmers, we are familiar with using numbers in different bases. We know about the binary, or base 2 system, that underlies our hardware. We are also usually aware of hexadecimal, or base 16, numbers because they are ubiquitous in many areas of what we do. Front-end programming, for example, uses hexadecimal to specify things like color codes -- #ffe23e. Backend programming also has a variety of uses for hexadecimal, such as expressing complex binary data in a human-readable, and human-typeable way -- 01ad3c6c27af21964e937593e2af9270963d896e.
Base 58, as the name states, is a way of expressing numbers in a system where each position has 58 digits, instead of 2 in binary, 10 in decimal, or 16 in hexadecimal. The advantage of a system with a large number of digits is that it can express even large numbers in a compact way. The base 62 system, which uses all ten digits, along with the 26 letters of the modern Latin alphabet in both lowercase and uppercase forms, or the base 64 system, which uses those characters plus + and /, have long been used to create compact sequences which are easy for people to use and type, and which are more compact than decimal numbers. A base62 number will be about 55.8% of the size of a decimal number.
There is one problem with the Base 62/64 systems for human use, however. It contains four characters which, depending on the font that is in use, can be difficult to distinguish between -- O, 0, l, and I, and the punctuation characters have drawbacks, as well. Thus, the concept of Base58 came along. The historical record seems somewhat ambiguous about the origins of the idea, but in 2009, both Flickr and the very early Bitcoin source code make mention of it.
The Bitcoin source, in particular, is specific about the reasoning:
// - Don't want 0OIl characters that look the same in some fonts and
// could be used to create visually identical looking account numbers.
// - A string with non-alphanumeric characters is not as easily accepted as an account number.
// - E-mail usually won't line-break if there's no punctuation to break at.
// - Doubleclicking selects the whole number as one word if it's all alphanumeric.
Eliminating those four characters loses only a small amount of the size compaction; Base58 encoded numbers are 56.7% of the size of decimal numbers, and the elimination of visually similar characters reduces the chances of a human reading or transcription error.
Since these early uses in 2009, Base58 has found usage in a wide variety of different applications. It is commonly used, in a few different variations, in the cryptocurrency and blockchain spheres, for the same reasons as were expressed above. In addition, it has found use in other applications as a compact way to encode path or filename data, among other things.
Among the variations of Base58 that are in use, the simplest of these simply change the alphabet that is used, typically reordering the letters. For instance, Ripple used a character order that appears to be almost random, but which was chosen so that the first characters of certain important, commonly encoded sequences will always have a common, meaningful letter.
Monero introduced a concept of encoding long sequences of bytes in short, 8-byte blocks, with padding, so that the output has a deterministic size. For example, a Monero address is 69 bytes long. Depending on the precise bytes that make up the address, it's possible that the final size could vary slightly when encoded with Base58. However, by using the block encoding and padding scheme, 69-byte Monero addresses will always end up being 95 characters long after encoding.
Three different checksumming schemes have been introduced. Bitcoin introduced Base58Check, which allows for a prefix, which is typically a single byte, although there is no technical requirement for it to be just one byte, to be prepended to the data. The prefix + data is then SHA256 hashed, and the resulting hash is passed through SHA256 a second time. The first four characters of the hash are then used as a checksum. Avalanche also introduced a simpler version of Base58Check, which eliminates the second pass through SHA256.
Additionally, the Substrate SDK for Polkadot introduced SS58, which is an address format with an implied checksumming algorithm based on Base58Check, but with a few key differences. Among these, rather than it using SHA2, it uses Blake2 for its cryptographic hashing function. Another very important difference is that the size of the checksum can vary in size between one byte and eight bytes, depending on the address format being used, and there are sixteen different address formats. It is also defined very specifically within the context of encoding addresses, and the expected behavior for SS58, when used with inputs that don't conform to what is in the spec, appears to be undefined.
The technical challenge with implementing a Base58 library is that most of the encoding work essentially revolves around doing some simple math with extremely large numbers.
Consider the following Monero address, the bytes of which are represented here as a hexadecimal string:
12426a2b555065c79b8d6293c5dd18c25a25bae1a8b8c67ceac7484133e6798579bba3444bd48d5d9fcffa64d805e3977b07e2d420a2212df3d612a5dbcc67653844ded707
If one interprets that sequence of bytes as a number, and one converts it to base 10, the magnitude of the number may be more clear.
1051489444096421776404938024043970419427503504570917630111914401795488476539125862169719760744464514996646591843577133626961699980940091376839812635255849749139347207
The most straightfoward way to convert this to base 58 is to do an integer division of the number. The remainder represents the last digit of the number. The value that remains should then be integer divided by 58, with the remainder representing the next digit. Repeat until the numbers has been divided out to 0.
This approach is generally fairly simple to code, particularly if your language supports math with arbitrarily large numbers.
# alphabet is an array that maps a digit position, such as 13, to a digit, such as E.
b58str = ""
while number > 0
number, remainder = number.divmod(base)
b58str << alphabet[remainder]
end
b58str.reverse
This approach is very slow, however, and base 58 is frequently used in applications where speed-of-encoding is valuable.
There are a few crates for Rust that implement base 58 encoding, with varying degrees of completeness. The fastest and most complete of these is bs58. It supports encoding and decoding in a variety of alphabets, though it doesn't support Monero's alternative encoding scheme. It also supports both Base58Check and CB58 checksumming, with enough syntactic niceties to make it fairly pleasant to use.
It is interesting to take a peek at the core of its implementation:
fn encode_into<'a, I>(input: I, output: &mut [u8], alpha: &Alphabet) -> Result<usize>
where
I: Clone + IntoIterator<Item = &'a u8>,
{
let mut index = 0;
for &val in input.clone() {
let mut carry = val as usize;
for byte in &mut output[..index] {
carry += (*byte as usize) << 8;
*byte = (carry % 58) as u8;
carry /= 58;
}
while carry > 0 {
if index == output.len() {
return Err(Error::BufferTooSmall);
}
output[index] = (carry % 58) as u8;
index += 1;
carry /= 58;
}
}
for _ in input.into_iter().take_while(|v| **v == 0) {
if index == output.len() {
return Err(Error::BufferTooSmall);
}
output[index] = 0;
index += 1;
}
for val in &mut output[..index] {
*val = alpha.encode[*val as usize];
}
output[..index].reverse();
Ok(index)
}
I am not going to do an in-depth analysis of this, but essentially what it is doing is implementing all of the math in the previous, simple version of the algorithm without resorting to complex, higher-order arbitrary precision mathematical functions. Instead, it uses simple integer mathematical functions, a single 8-bit byte at a time, to iterate through the data to encode and transform it into base 58.
The Rust library based this implementation on the trezor-crypto C library, and it is fast. On my laptop, it can encode a string with 3 bytes to base58, returning a string, in about 38ns to 40ns, depending on what the string is.


It has no hard limits on the size of data that it can handle with this algorithm, and maintains good performance, even with larger pieces of data.

If you are a Rust developer, this is the library to use.
If you are a Crystal developer, until recently the landscape for base 58 implementations was pretty bleak. There are a few very modest implementations that provide some basic capabilities, but none support the full range of base 58 variations, and none are particularly fast.
However, I have released a new library, base58.cr, to address this. This library is also based on the aforementioned trezor-crypto C library's base 58 implementation, optimized for Crystal. It supports the Bitcoin, Flickr, Ripple, and Monero alphabets, with Monero's 8-byte block-based encoding and it supports both Base58Check and CB58 checksum algorithms, as well, and it is quite fast.
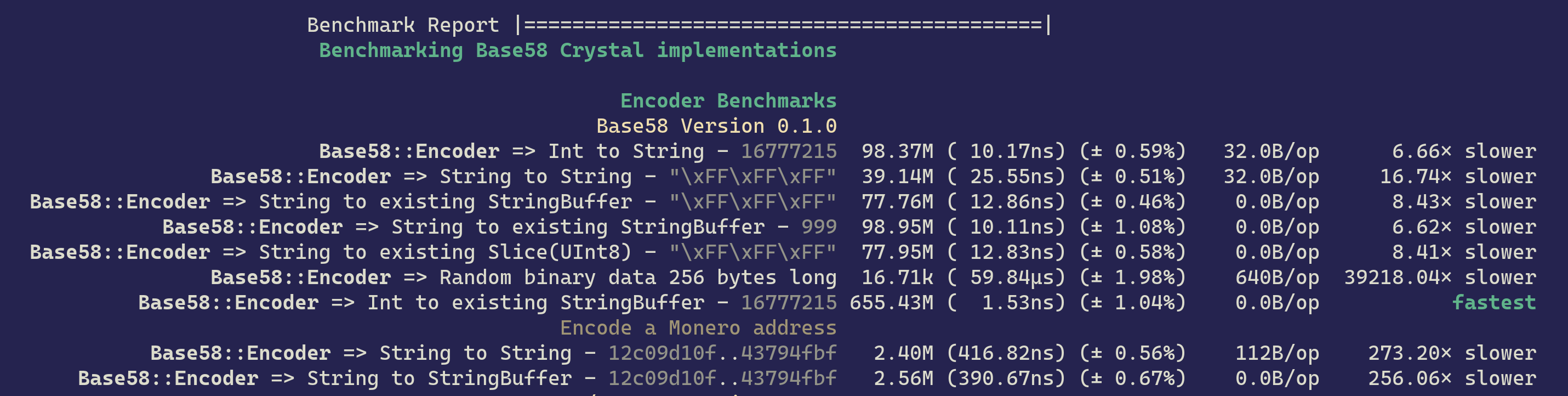
At approximately 25ns - 26ns to encode \xFF\xFF\xFF, and around 400ns to encode a full 69 byte Monero address, the performance is extremely competitive for whatever you may want to do, whether it is encoding IDs into URLs, compacting session information, or writing a Polkadot distributed application, you can leverage base58.cr to your advantage.
And regardless of whether you are using Rust, Crystal, Ruby, Python, or any other language, odds are good that there is a Base 58 library available to you. It is a simple idea with a lot of utility.
Subscribe to my newsletter
Read articles from Kirk Haines directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by