Don't trust, verify: Indexing ENS Domains with Subsquid
 Massimo Luraschi
Massimo Luraschi
Summary
I leveraged Subsquid's indexing framework to build my very own API that maps an ENS name to its tokenId and vice versa. Why this is needed or important? Read below 😉
The project discussed in this article is available at this repository, on the ens-workshop branch:
github.com/RaekwonIII/ethereum-name-service-indexing/
The repository is also configured, so you can run the project on Gitpod:

Introduction
I have recently published a series of videos and articles to educate about Blockchain Data Indexing.
It specifically discusses Ethereum, although it's applicable to all the EVM networks that Subsquid is available for, plus Substrate networks, with a couple of adaptations I'll probably discuss in a future article. It's a full course consisting of multiple "lessons", introducing Subsquid, the basic concepts, and a few practical tutorials to practice using the SDK.
While creating these tutorials, I choose Ethereum Name Service as an example, because it's a famous project, and quite frankly, also because I take these changes to study some subjects I am interested in (sue me! 😛).
What I didn't realize was that, in doing so, I ended up discovering not one, but two peculiar aspects of the NFTs created by the project, and consequently, two strong cases in favor of blockchain data indexing, and more specifically, two great examples of Subsquid's superiority in this aspect.
Ethereum Domains are NFTs…but they are odd
First of all, this needs to be clarified: whenever someone is registering a domain name on the Ethereum Name Service app, they are minting a Non-Fungible Token from the ENS collection.
This token looks and behaves like a common ERC-721 token: as a matter of fact, the project migrated the registrar in 2019, and since then, it's a contract that is compliant to this standard.
It does, however, have its peculiarities.
Token ID calculation
Unlike usual NFT collections, the tokenId of ENS name is the uint256representation of the hash of the label (vitalik for vitalik.eth). If someone wanted to derive the tokenId for a given ENS name (in this case: vitalik, which computes to 79233663829379634837589865448569342784712482819484549289560981379859480642508), they would have to do it like this:
const ethers = require('ethers')
const BigNumber = ethers.BigNumber
const utils = ethers.utils
const name = 'vitalik'
const labelHash = utils.keccak256(utils.toUtf8Bytes(name))
const tokenId = BigNumber.from(labelHash).toString()
On the flip-side, deriving the ENS name from the tokenId is not as easy. The reason for this was that the fixed-length hash allows to register infinite length of names, but the trade-off is that, because the name is hashed, this is a one-way operation: you cannot obtain ENS names from a tokenId.
All of this is explained in greater detail on ENS documentation page.
Token URL and metadata
Simply put, the ENS contract does not have .tokenURI. The project has, instead, created a separate metadata service which NFT marketplaces like OpenSea can fetch metadata for ENS such as registration data, expiration date, name length, etc.
The problem with this service? It’s using the tokenId to obtain the metadata.
Downsides of these oddities
Let's say you want to visualize the Nyan cat image that Vitalik has associated with his vitalik.eth name: how would you do that?
So this is exactly the adventure I embarked on.
Let's get building!
The project in Lesson 2 of the Blockchain Data Indexing course (you can find the project on this GitHub page) was already indexing ENS tokens, but in order to keep it simple and don't introduce too many variables to the learning process, it stopped at tracking transfers of tokens.
const processor = new EvmBatchProcessor()
.setDataSource({
chain: process.env.RPC_ENDPOINT,
archive: "https://eth.archive.subsquid.io",
})
.addLog(contractAddress, {
filter: [
[
events.Transfer.topic,
],
],
data: {
evmLog: {
topics: true,
data: true,
},
transaction: {
hash: true,
},
},
});
Modifying the schema
Because the objective is to improve the current project and save additional data, we need to change the schema first. I have added new fields, such as name, imageURI, uri and the registrar expiration date as expires :
type Token @entity {
id: ID!
owner: Owner
name: String
imageURI: String
uri: String
expires: BigInt,
transfers: [Transfer!]! @derivedFrom(field: "token")
contract: Contract
}
type Owner @entity {
id: ID!
ownedTokens: [Token!] @derivedFrom(field: "owner")
}
type Contract @entity {
id: ID!
name: String! @index
symbol: String!
totalSupply: BigInt!
tokens: [Token!]! @derivedFrom(field: "contract")
}
type Transfer @entity {
id: ID!
token: Token!
from: Owner
to: Owner
timestamp: BigInt!
block: Int! @index
transactionHash: String!
}
After the publishing of Lesson 2, Subsquid published a new version of our CLI, with improved commands, make sure to install it with
npm i -g @subsquid/cli@latestAnd if you are working on the same project from the lesson, make sure to add this
commands.jsonfile to your root folder.
Following these changes, we need to update the TypeScript models, so let's run the command:
sqd codegen
Processor configuration
What is truly interesting for the ENS project, is the ability to index the NameRegisteredand NameRenewed events as well. This way, we are able to capture every time a name is registered, renewed and when it is transferred to a different owner.
For this, we need to change the part where EvmBatchProcessor class is instantiated and configured:
const processor = new EvmBatchProcessor()
.setDataSource({
chain: process.env.RPC_ENDPOINT,
archive: "https://eth.archive.subsquid.io",
})
.addLog(contractAddress, {
filter: [
[
events.NameRegistered.topic,
events.NameRenewed.topic,
events.Transfer.topic,
],
],
data: {
evmLog: {
topics: true,
data: true,
},
transaction: {
hash: true,
},
},
});
Of course, we also need to adjust how we process each item, because we will have logs generated by three different events, with three different topics, and they have to be treated separately:
processor.run(new TypeormDatabase(), async (ctx) => {
const ensDataArr: ENSData[] = [];
for (let c of ctx.blocks) {
for (let i of c.items) {
if (i.address === contractAddress && i.kind === "evmLog") {
if (i.evmLog.topics[0] === events.NameRegistered.topic) {
const ensData = handleNameRegistered({
...ctx,
block: c.header,
...i,
});
ensDataArr.push(ensData);
}
if (i.evmLog.topics[0] === events.NameRenewed.topic) {
const ensData = handleNameRenewed({
...ctx,
block: c.header,
...i,
});
ensDataArr.push(ensData);
}
if (i.evmLog.topics[0] === events.Transfer.topic) {
const ensData = handleTransfer({
...ctx,
block: c.header,
...i,
});
ensDataArr.push(ensData);
}
}
}
}
await saveENSData(
{
...ctx,
block: ctx.blocks[ctx.blocks.length - 1].header,
},
ensDataArr
);
});
Notice the three different handle* functions. They are not too different from each other, but I'd argue they are still different enough to deserve to be separate:
function handleNameRegistered(
ctx: LogHandlerContext<
Store,
{ evmLog: { topics: true; data: true }; transaction: { hash: true } }
>
): ENSData {
const { evmLog, block, transaction } = ctx;
const { id, owner, expires } = events.NameRegistered.decode(evmLog);
const ensData: ENSData = {
id: `${transaction.hash}-${evmLog.address}-${id.toBigInt()}-${
evmLog.index
}`,
to: owner,
tokenId: id.toBigInt(),
timestamp: BigInt(block.timestamp),
expires: expires.toNumber(),
block: block.height,
transactionHash: transaction.hash,
};
return ensData;
}
function handleNameRenewed(
ctx: LogHandlerContext<
Store,
{ evmLog: { topics: true; data: true }; transaction: { hash: true } }
>
): ENSData {
const { evmLog, block, transaction } = ctx;
const { id, expires } = events.NameRenewed.decode(evmLog);
const ensData: ENSData = {
id: `${transaction.hash}-${evmLog.address}-${id.toBigInt()}-${
evmLog.index
}`,
tokenId: id.toBigInt(),
timestamp: BigInt(block.timestamp),
expires: expires.toNumber(),
block: block.height,
transactionHash: transaction.hash,
};
return ensData;
}
function handleTransfer(
ctx: LogHandlerContext<
Store,
{ evmLog: { topics: true; data: true }; transaction: { hash: true } }
>
): ENSData {
const { evmLog, block, transaction } = ctx;
const { from, to, tokenId } = events.Transfer.decode(evmLog);
const ensData: ENSData = {
id: `${transaction.hash}-${evmLog.address}-${tokenId.toBigInt()}-${
evmLog.index
}`,
from,
to,
tokenId: tokenId.toBigInt(),
timestamp: BigInt(block.timestamp),
block: block.height,
transactionHash: transaction.hash,
};
return ensData;
}
Augment on-chain data with external APIs
We are getting to the juicy bit here.
Finally, I have explored the tokenId and tokenURI issues mentioned above, and changed the saveENSData function to:
Fetch the token metadata from ENS metadata service
Process this information and extract the name of a given token (establishing the
tokenId↔️namerelation) and the URL of the imageSave this data in the
Tokenentity, on the database
async function saveENSData(
ctx: BlockHandlerContext<Store>,
ensDataArr: ENSData[]
) {
const tokensIds: Set<string> = new Set();
const ownersIds: Set<string> = new Set();
for (const ensData of ensDataArr) {
tokensIds.add(ensData.tokenId.toString());
if (ensData.from) ownersIds.add(ensData.from.toLowerCase());
if (ensData.to) ownersIds.add(ensData.to.toLowerCase());
}
const transfers: Set<Transfer> = new Set();
const tokens: Map<string, Token> = new Map(
(await ctx.store.findBy(Token, { id: In([...tokensIds]) })).map((token) => [
token.id,
token,
])
);
const owners: Map<string, Owner> = new Map(
(await ctx.store.findBy(Owner, { id: In([...ownersIds]) })).map((owner) => [
owner.id,
owner,
])
);
for (const ensData of ensDataArr) {
const {
id,
tokenId,
from,
to,
block,
expires,
transactionHash,
timestamp,
} = ensData;
// the "" case handles absence of sender, which means it's not an actual transaction
// it's the name being registered
let fromOwner = owners.get(from || "");
if (from && fromOwner == null) {
fromOwner = new Owner({ id: from.toLowerCase() });
owners.set(fromOwner.id, fromOwner);
}
// the "" case handles absence of receiver, which means it's not an actual transaction
// it's the name being renewed
let toOwner = owners.get(to || "");
if (to && toOwner == null) {
toOwner = new Owner({ id: to.toLowerCase() });
owners.set(toOwner.id, toOwner);
}
const tokenIdString = tokenId.toString();
let token = tokens.get(tokenIdString);
if (token == null) {
token = new Token({
id: tokenIdString,
contract: await getOrCreateContractEntity(ctx.store),
});
tokens.set(token.id, token);
}
token.owner = toOwner;
if (expires) {
token.expires = BigInt(expires);
if (expires * 1000 < Date.now()) {
// ctx.log.info(`Token ${tokenId} has expired`);
continue;
}
let name = "",
uri = "",
imageURI = "";
try {
// https://metadata.ens.domains/docs
let tokenURI = `https://metadata.ens.domains/mainnet/${contractAddress}/${tokenId}`;
const meta = await axios.get(tokenURI);
imageURI = meta.data.image;
name = meta.data.name;
uri = meta.data.url;
} catch (e) {
ctx.log.warn(`[API] Error during fetch token ${tokenId} metadata`);
if (e instanceof Error) ctx.log.warn(`${e.message}`);
} finally {
token.name = name;
token.uri = uri;
token.imageURI = imageURI;
}
}
if (toOwner && fromOwner) {
const transfer = new Transfer({
id,
block,
timestamp,
transactionHash,
from: fromOwner,
to: toOwner,
token,
});
transfers.add(transfer);
}
}
await ctx.store.save([...owners.values()]);
await ctx.store.save([...tokens.values()]);
await ctx.store.save([...transfers]);
}
The important part is where the metadata service API is called, using axios library:
let tokenURI = `https://metadata.ens.domains/mainnet/${contractAddress}/${tokenId}`;
const meta = await axios.get(tokenURI);
I want to take a moment to emphasize the ability to call arbitrary external services to obtain additional information, and add to the data we extract from the blockchain.
This way, we are building a service, providing data that would not be possible to produce by purely relying on the blockchain.
Don't trust, verify
The ENS documentation acknowledges the shortcomings of their architectural choice, and provides an alternative, which is using a third party service, or downloading this service's dataset.
One might brush this off as non-consequential, but if you truly subscribe to the motto “Don’t Trust, Verify”, being able to obtain this information independently, in a decentralized way, and without relying on third party services is paramount.
Local indexing
If you have followed along and want to try this at home, you should delete the previous migration file:
rm -rf db/migrations/*js
Launch the database Docker container and generate a new migration file:
sqd up
sqd migration
Launch the processor:
sqd process
And finally, in a separate terminal window, launch the GraphQL service:
sqd serve
We can, for example, test out our initial question: "what is the image linked to vitalik.eht ENS name?" with this query:
query MyQuery {
tokens(where: {name_contains: "vitalik"}) {
expires
id
imageURI
name
uri
owner {
id
}
}
}
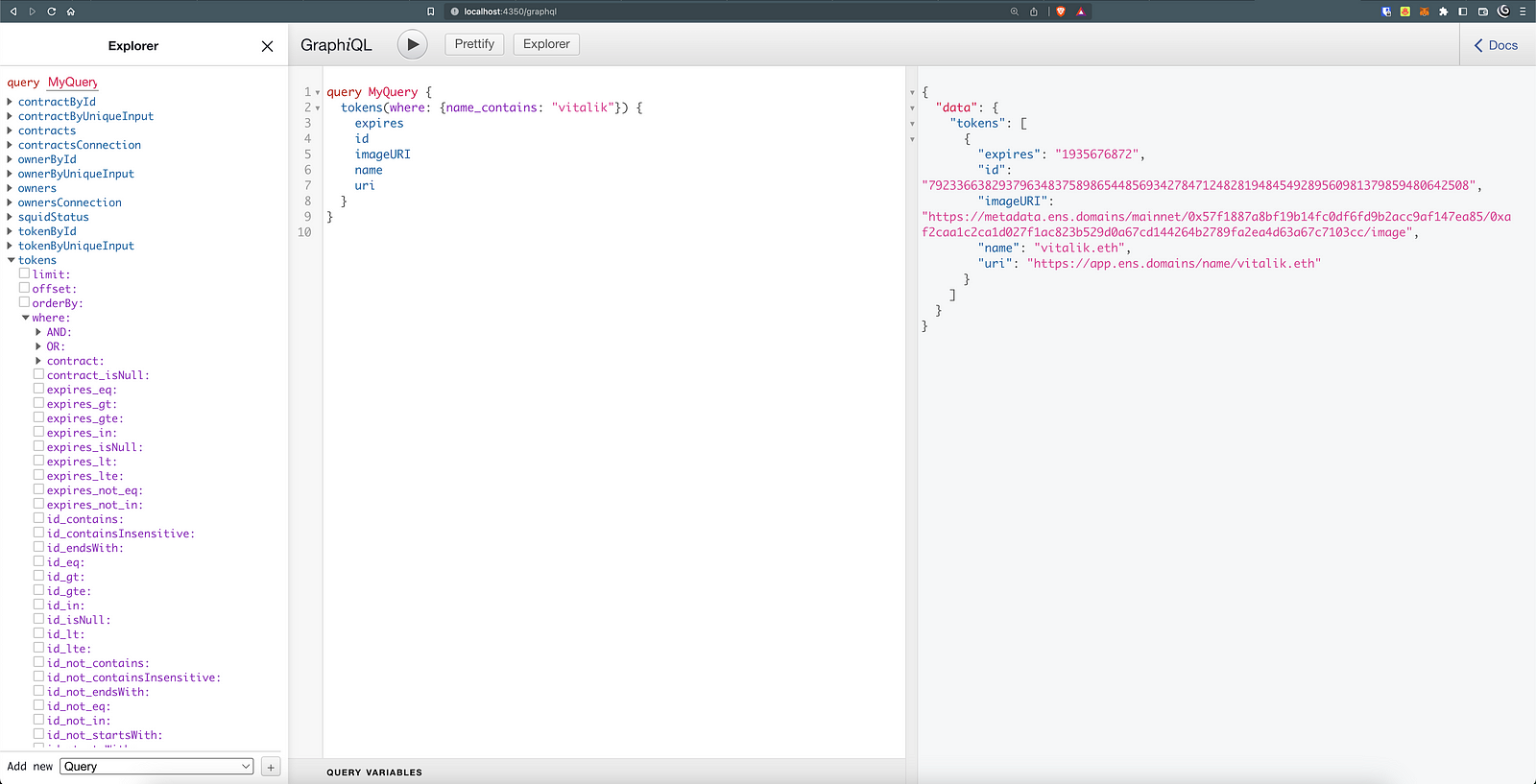
And if we copy paste the imageURI in our browser, we'll eventually land on vitalik's Nyan cat animated image:

Gitpod
Another option, as mentioned at the start of the article, is to run the project on Gitpod by clicking on the related link on the project's README file:
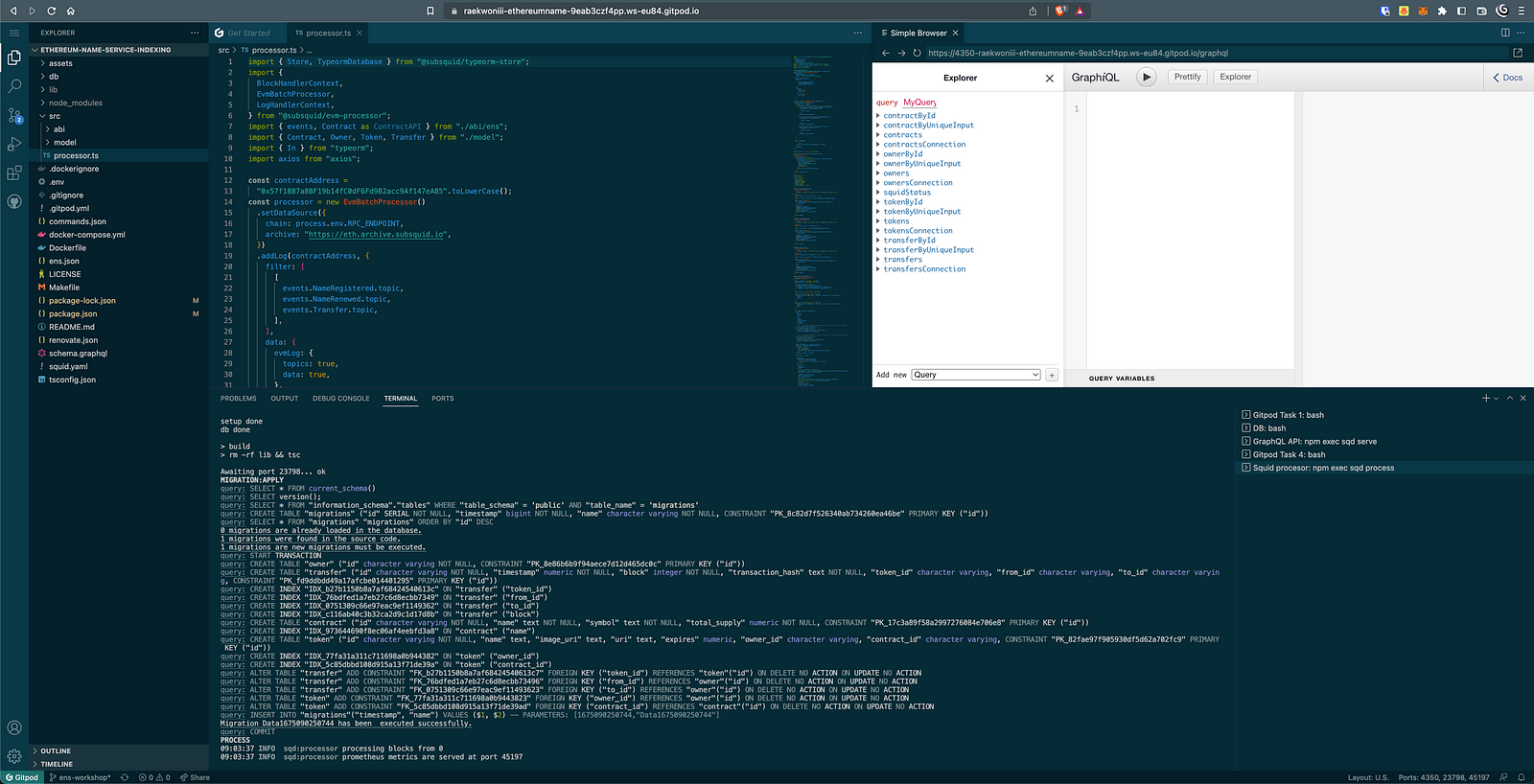
Which will launch the entire project in a cloud-hosted execution environment for us.
Conclusions
What I showed you here is that, thanks to Subsquid, you can build your own indexer, that is able to map every tokenId to its corresponding ENS name, allowing for querying in the opposite direction (get ENS name from tokenId ).
If you found this article interesting, and you want to read more, please follow me and most importantly, Subsquid.
**Subsquid socials:
**Twitter | Discord | LinkedIn | Telegram | GitHub | YouTube
Subscribe to my newsletter
Read articles from Massimo Luraschi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Massimo Luraschi
Massimo Luraschi
Software Engineering, Blockchain, Basket, Science 🇮🇹🇬🇧🇫🇷 If I have seen further it is by standing on the shoulders of giants