Useful free tools for data cleaning
 Alain Victor Ramirez Martinez
Alain Victor Ramirez Martinez
Data cleansing or Data Cleaning is one of the first tasks you must perform before further analysis, regardless of the task or project you are working on in data science. I want to give you a brief overview of a few tools that can be quite helpful in this post.
Introduction to Data Cleaning
Data preparation and transformation into a format that can be used for analysis and decision-making is known as data cleaning, also known as data cleansing or data pretreatment. The purpose of data cleaning is to increase the accuracy and dependability of the conclusions drawn from data sets by removing errors, inconsistencies, and irrelevant information.
Importance of Data Cleaning
A critical stage of the data analysis process is data cleaning. Inconsistencies, mistakes, and irrelevant information are frequently present in raw data, which can result in inaccurate conclusions and poor decision-making. By cleaning the data, you can make sure that the conclusions drawn from it are accurate and trustworthy, which can help your data-driven projects succeed.
Common Challenges in Data Cleaning
Data cleaning can be a complex and time-consuming process, and there are several common challenges that data scientists and analysts face. Some of these challenges include:
Dealing with missing values
Removing duplicates
Transforming data into a usable format
Handling inconsistent data
Cleaning large data sets
Popular Tools for Data Cleaning
There are several popular tools available for data cleaning, each with its own unique set of features and capabilities. Some of the most popular tools include:
OpenRefine: An open-source data cleaning tool that offers features such as data visualization, data clustering, and data transformation. One of OpenRefine's strengths is its ability to handle large datasets with ease. It also provides a wide range of data transformation functions, including text manipulation, data reconciliation, and data clustering. Additionally, OpenRefine integrates well with other tools and services, making it a popular choice for data scientists and data analysts.
Python Libraries: Here are some useful tools and techniques:
- Pandas is a popular Python library for data manipulation and analysis. It provides a powerful data structure called a DataFrame that makes it easy to clean and manipulate data. With pandas, you can import data from a variety of sources, including CSV, Excel, and SQL databases. Once the data is imported, you can clean it by removing duplicates, handling missing values, and converting data types.
Here's an example of how to use pandas to import and clean data:
import pandas as pd
df = pd.read_csv("data.csv")
# Removing duplicates
df.drop_duplicates(inplace=True)
# Handling missing values
df.fillna(0, inplace=True)
# Converting data types
df["column_name"] = df["column_name"].astype("int")
Continue Python Libraries...
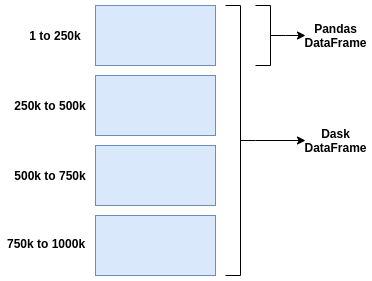
Dask: Pandas is quite effective with tiny data (often 100MB to 1GB), and performance is very infrequently an issue. However, if you have additional data that is significantly bigger than your local RAM (let's say 100GB), you may either continue to use Pandas to manage the data to a certain extent by using some methods, or you can choose a better tool, in this example Dask.
Dask is popularly known as a Python parallel computing library. Through its parallel computing features, Dask allows for rapid and efficient scaling of computation. It offers a simple method for handling massive data in Python with little additional effort outside of the standard Pandas workflow. To put it another way, Dask makes it simple to scale up to clusters to handle enormous amounts of data or down to single machines to handle little amounts of data by utilizing the full potential of CPU and GPU, all of which are wonderfully integrated with Python code. Consider Dask to be a more scalable and performant version of Pandas. Even better, you can perform any data transformation or operation on demand by alternating between a Dask data frame and a Pandas data frame.
NOTE: Regardless of file size, we can also read several files to the Dask data frame in a single line of code.
Dask will generate a data frame that is row-wise partitioned—that is, rows are clustered by an index value—when we import our data from the CSV. Dask uses partitioning to be able to load data into memory as needed and process it very quickly.
Here is an example of how to use Dask with CSV files:
import dask.dataframe as dd
from dask.distributed import Client
# Setting up a cluster
client = Client(n_workers=4)
client
# Loading the data in one or multiple files
ddf = dd.read_csv(
os.path.join("data","flights","small","*.csv"), parse_dates={"Date": [0, 1, 2]},
dtype={'air_time': 'float64',
'arr_delay': 'float64',
'arr_time': 'float64',
'dep_delay': 'float64',
'dep_time': 'float64'},
)
# Finding the mean of departure delay grouped by origin
ddf.groupby("origin").dep_delay.mean().compute()
#Applying a lambda function
ddf['distance'].apply(
lambda x: x + 1, meta=('distance','int64')
).compute()
When it comes to functionality, Pandas still prevails. Pandas are outperformed by Dask in terms of performance and scalability.
Extra:
DataWrangler by AWS: An online data cleaning tool that provides a simple and intuitive interface for transforming and cleaning data. It has a straightforward interface that makes it easy to use, even for those with limited technical skills. DataWrangler is best suited for small to medium-sized datasets, and it provides a limited set of data transformation functions.
Trifacta: A cloud-based data cleaning tool that provides interactive data transformation and data wrangling capabilities. It offers a wide range of features, including data blending, data quality checks, and data visualization.
Important update: February 2022: Alteryx announced it completed its acquisition of Trifacta for $400 million in an all-cash deal.
How to Choose the Right Tool for Your Data Cleaning Needs
When choosing a data cleaning tool, it is important to consider several factors, such as:
Scalability: Consider whether the tool can handle the size of your data sets and whether it is scalable for future growth.
Data format compatibility: Consider whether the tool is compatible with the format of your data, such as CSV, Excel, or JSON.
Features and capabilities: Consider the specific data cleaning tasks that you need to perform and choose a tool that offers the features and capabilities you need.
Conclusion
Data cleaning is a crucial step in the data analysis process, and using the right tools can make this process more efficient and effective. By considering factors such as cost, scalability, and data format compatibility, you can choose the right tool for your data cleaning needs and improve the accuracy and reliability of your data-driven insights.
Subscribe to my newsletter
Read articles from Alain Victor Ramirez Martinez directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Alain Victor Ramirez Martinez
Alain Victor Ramirez Martinez
I am a telco engineer with self taugh studies in Data Science and ML. I am willing to start a new phase in my career moving from project, product and commercial management to the development field.