Practice Web Scraping 101 : SERP
 Liaichi_Mustapha
Liaichi_Mustapha
What are we going to scrap?
In this project, we will build a simple web scraper to scrap google search results, also known as SERP.
Used Tool :
In this project I tried to use different tools to build this scraper :
SelectorGadget, we talked in deep about it in this article.
The Chrome Developer Tools, we discuss in depth how to use in this article.
Library used :
we used Selenium to build our scraper because it's very popular and can be used to automate processes such as writing in the search box and performing the action of searching. However, we talked about it too in this article.
The Project :
I write the code with =comment to explain the code.
Well let's get right to it :
# Import the neccesary moduls
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
the web driver is basically what will make it possible to automate the browser.
We will find elements by css selector, the possible way to do it is by using the By
from the selenium library.
# get the Google url :
driver = webdriver.Firefox()
driver.implicitly_wait(10)
driver.get("https://www.google.com/?hl=fr")
Then we create a variable driver, which the variable that controls our browser, the last line of code tells the browser to open the given url .
# Get the box search
driver.implicitly_wait(10)
Search = driver.find_element(By.CSS_SELECTOR, 'input.gLFyf')
We find the element using it's CSS selector it's an input field with the class ".gLFyf".
# Let's search about "cute animals" and click On the button search :
driver.implicitly_wait(10)
Search.send_keys("cute animals" + Keys.ENTER)
The Search is the variable that we stored our box search in it, and hence what the line of code means is to write "cute animals" in the box search and the part Keys.ENTER means perform the action of search
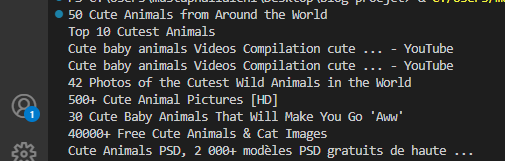
# Get all the link's title from the first page :
links_Title = driver.find_elements(By.CSS_SELECTOR, '.DKV0Md')
for link in links_Title :
# Print all the links :
print(link.text.strip())
Finally, we get all the link's title from the search page which is 9 in total, using CSS selector to find that element on the page then we print each link.
The Full Code :
Here is the full code :
# Import the neccesary moduls
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# get the Google url :
driver = webdriver.Firefox()
driver.implicitly_wait(10)
driver.get("https://www.google.com/?hl=fr")
# Get the box search
driver.implicitly_wait(10)
Search = driver.find_element(By.CSS_SELECTOR, 'input.gLFyf')
# Let's search about cute animals and click On the button search :
driver.implicitly_wait(10)
Search.send_keys("cute animals" + Keys.ENTER)
# Get all the link's title from the first page :
links_Title = driver.find_elements(By.CSS_SELECTOR, '.DKV0Md')
for link in links_Title :
# Print all the links :
print(link.text.strip())
Subscribe to my newsletter
Read articles from Liaichi_Mustapha directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Liaichi_Mustapha
Liaichi_Mustapha
Hello, I’m Mustapha Liaichi an engineering student at the School of information science in Morocco, I’m here to share my learning journey and knowledge with others. I have been coding with python for many years and I find that web scraping is an amazing world to discover also I love web dev and I want to tell others about my projects and achievement.