How NebulaGraph Database Uses Jepsen to Detect Data Consistency Issues in Raft Implementation
 NebulaGraph Database
NebulaGraph Database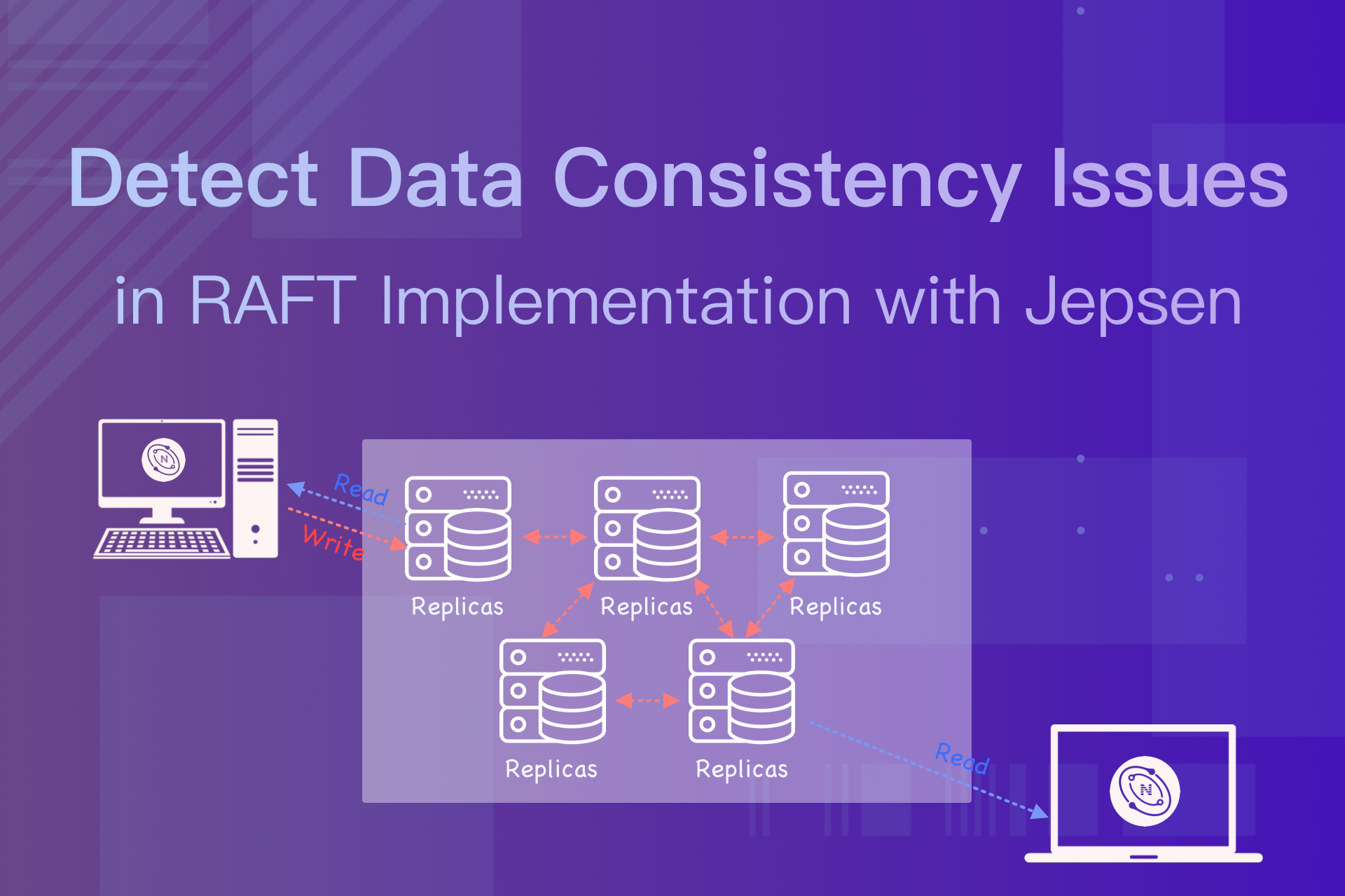
Data consistency is a global issue for all distributed systems. NebulaGraph is no exception as a distributed graph database.
Thanks to the separation between query and storage layers, NebulaGraph only exposes simple kv interfaces in the storage layer. Using RocksDB as a backend kv library, NebulaGraph ensures strong data consistency among multiple replicas via the Raft protocol.
Although raft is meant to be more understandable than Paxos, the practice for it in a distributed system is tricky.
Another challenging problem is how to test a Raft-based distributed system. Currently, NebulaGraph verifies data consistency with Jepsen. In our previous post Practice Jepsen Test Framework in NebulaGraph, we have introduced in detail how Jepsen test framework works, you may take a look at it to gain some basic understanding about Jepsen.
In this post, we will explain how to verify data consistency of the distributed NebulaGraph kv stores.
Strong Data Consistency Explained
Let's start with the definition of strong data consistency. Quote the book Designing Data-Intensive Applications:
In a linearizable system, as soon as one client successfully completes a write, all clients reading from the database must be able to see the value just written.
The basic idea of strong data consistency or linearizability is to make a distributed system appear as if there were only one copy of the data, and all operations on it are atomic. Any read request from any client gets the latest data written to the system.
Linearizability Verification with Jepsen
Take Jepsen timeline test as an example. In this test, we use the single-register model. Clients can only perform read or write operations on the register. All operations are atomic and there is no intermediate state.
Suppose there are four clients sending requests to the system at the same time. Each bar in the figure indicates a request made by a client, where the top of a bar is the time when the request was sent, and the bottom of a bar is when the response was received by the client.

From the client's point of view, any request will be processed at any time between the time when it was sent and the time when the response was received. Seen from the figure above, the three operations, write 1 by client 1 (i.e. 1: write1), write 4 by client 3 (i.e. 3: write4), and read 1 by client 4 (i.e. 4: read1), overlapped in processing time. However, we know the real request processing sequence by the system via the responses received by different clients.
Here's how:
The initial value is empty yet client 4 gets 1 for its read request, which indicates that the read operation by client 4 must have begun after the write 1 operation by client 1 and that write 4 by client 3 must have happened before write 1, or the older value 4 would be returned for the read request by client 4. Thus the sequential order of the three operations is write 4 -> write 1 -> read 1.
Although seen from the above figure, request read 1 is sent first, it's the last one processed. Later operations do not overlap in time, that is to say, they are sent sequentially. Read request by client 2 returns the last write value 4.
The entire process does not violate the rules of strong data consistency, so the verification is passed.
If the read request by client 3 returns the older value 4, then the system is not strongly consistent. Based on the previous analysis, the last successful write value is 1. If client 3 gets the stale value 4, then linearizability of the system is broken.
Actually, Jepsen verifies strong data consistency of distributed systems with similar algorithms.
Data Consistency Issues Found with Jepsen Test
The following gives an example of how a request is handled in a Raft group (three replicas) in NebulaGraph for better understanding of data consistency.
Read request processing is relatively simple as only the elected leader server can interact with the client. The leader, after checking it's still the leader, fetches the corresponding result from the state machine and sends back to the client.
Write request processing is a bit more complex. The steps are shown in the Raft Group Figure below:
The leader (the green circle) receives requests sent from the client and writes them into its WAL (write ahead log).
The leader sends the corresponding log entry in the WAL to its followers and enters the waiting phase.
The follower receives the log entry and writes it into its own WAL, then returns success.
When at least one follower returns success, the leader updates the state machine and sends responses to the client.

Now we will show you some NebulaGraph Raft implementing issues found in Jepsen test with examples below.
Data consistency example 1: Stale value returned for read requests
Shown in the above figure, A, B, C form a three-replica raft group. The circles are the state machines (we assume them as a single-register for simplicity) and the box stores the corresponding log entry.
At the initial state, all the state machines in the three replicas are 1, the leader is A and the term is 1.
After request write 2 is sent by the client, the leader processes it based on the previously described process, informs the client of a successful write, and is then killed.
Then C is elected as leader of term 2. However, since C has yet applied the log entry of write 2 to the state machine (the value is still 1 at the time being), 1 will be returned if C receives requests from the client. This absolutely violates the definition of strong data consistency because 2 has been successfully written while a stale value is returned.
Such an issue occurs after C is elected as leader of term 2. It is necessary to send heartbeat to ensure the log entry of the previous term is accepted by the quorum for the cluster. No read is allowed before the heartbeat success. Otherwise stale data is likely to be returned. Please refer to Figure 8 and Session 5.4.2 in thisRaft paper if you want more details.
Data consistency example 2: Leader ensures itself as a leader
Another issue we have found via Jepsen test is: how does a leader ensure itself still the leader? Such problems occur upon network partition. When the leader can't connect to the quorum due to network failure, if read is still allowed, a stale value is likely to be returned.
To avoid such cases, we have introduced the leader lease concept.
When a node is elected as leader, it needs to send heartbeats to other nodes periodically. If the heartbeat is received by most of the nodes successfully, a lease for some time is obtained and there will not be any new leaders during the term. Thus the data recency is guaranteed on the node and read requests are processed normally during this time.

Being different from TiKV's process, NebulaGraph doesn't consider heartbeat interval \ some coefficient* as the lease time because of the drift of the clock skew of different nodes.
Rather, we store 1) T1 = heartbeat intervals and 2) T2 = the time cost by the last successful heartbeat or appendLog, and get the lease duration by (T1 - T2).
When network is partitioned, the old leader still processes read requests (write requests are failed due to the isolation) during the lease time in spite of isolation. When the lease is expired, both read and write requests would fail. A leader election takes place when a follower node times out while waiting for a heartbeat from the leader node.
Conclusion
You need long-term pressure tests and failure simulations to discover problems in a distributed system. Jespen is a great helper for its ability to verify distributed systems under various failures.
In the future, we will introduce other chaos engineering tools to verify data consistency in NebulaGraph. This way we can continuously improve performance while ensuring high data reliability.
You might also like
Subscribe to my newsletter
Read articles from NebulaGraph Database directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by