Flying High with Rust and UDP: Building a Client-Server System for Flight Reservations
 XingXiang Ong
XingXiang Ong
Introduction
Project overview
For my distributed systems class, I was tasked with building a flight reservation system. It would handle client requests for information and seat reservations, while the server maintained the database of flights.
There were 2 requirements for the project:
Use UDP as the underlying communication protocol
Implement and use a custom data marshaling protocol
In this blog post, I'll share my experience building the flight reservation system from scratch, including the challenges I faced, the design decisions I made, and the lessons I learned along the way.
So, if you're interested in building distributed systems or just want to learn more about Rust and UDP, keep reading!
Why rust?
I chose to use Rust for this project because it...
Gives low-level control
Almost guarantees memory safety (unlike other low-level languages like C/C++)
Provides good developer experience, thanks to great IDE tooling
What is Data Marshaling?
A quick introduction
One of the tasks of the project was to create a custom data marshaling protocol. Data marshaling is "the process of transforming the memory representation of an object into a data format suitable for storage or transmission" (Wikipedia).
This is a necessary step that both the client and the server must take when communicating with each other. The most common way that web developers like myself are used to is by JSON documents.
The benefit of using JSON as the marshaling format is that it's so widely adopted in the industry. However, other marshaling formats use less space to encode the same information, like Protocol Buffers (protobuf).
Since the data marshaling protocol that I had to design would only be used for my project, I decided to prioritize simplicity over readability or space optimisation.
My data marshaling design
There are three portions to any datagram sent between the client and server. Note that all byte values are stored in Big-Endian format.
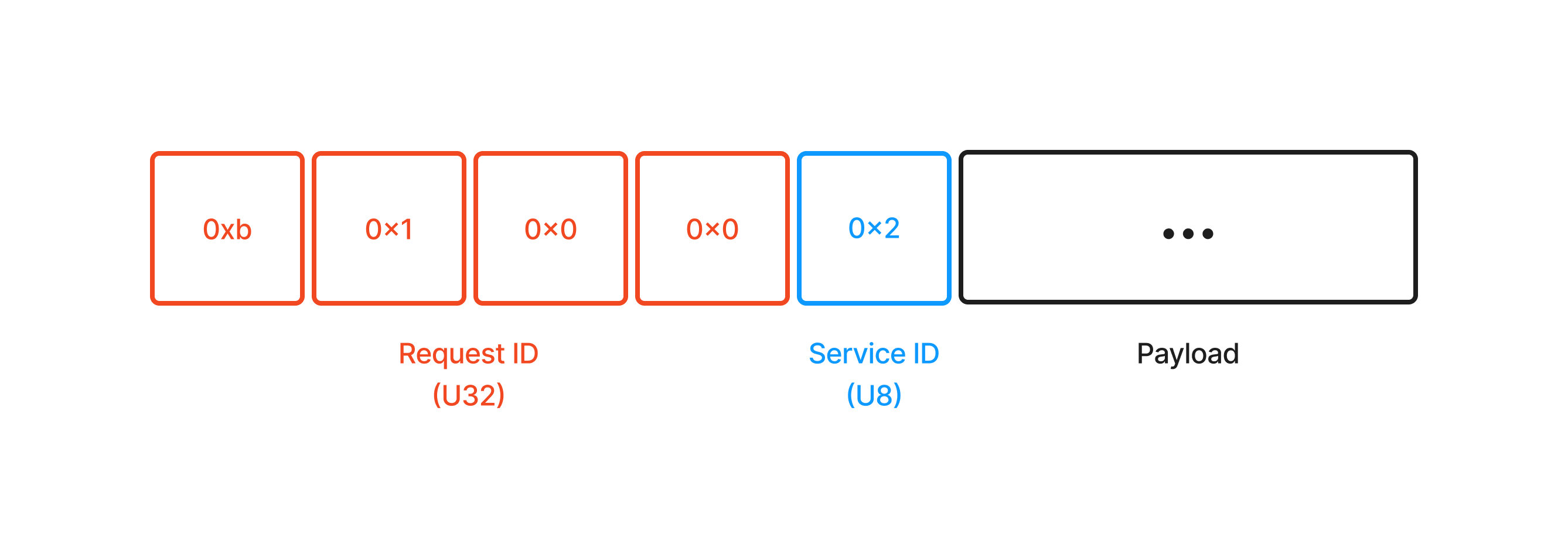
Request ID (4 bytes):
A request ID is used to identify separate requests made by the client. The server needs this, in combination with the client address, to de-deduplicate requests from the client upon a timeout, if at-least-once invocation semantics is used.
This is given 4 bytes, meaning that IDs up to 2^32 can be used. This future-proofs the system for the case that there will be upwards of millions of total requests in the future.
Service ID (1 byte):
A service ID is used by the server to identify the specific service that the client is requesting.
Only 4 services are made available at this point using values 1-4. This ID will also be used to indicate errors by having a value of 0. Hence, there will only be 5 possible values for this ID. Therefore, only 1 byte is needed.
Payload:
- This is variable-sized and depends on the parameters being sent from client to server, or from server to client.
How is the payload marshaled?
It's helpful to understand what pieces of data the client and server are using to communicate with each other.

The data types I need to account for are:
Integer
Float
String
Integer array
Marshaling integers and floats
// marshaling/src/lib.rs
pub fn marshal_u32(number: u32, buf: &mut Vec<u8>) {
buf.extend_from_slice(&number.to_be_bytes());
}
pub fn unmarshal_u32(buf: &[u8], mut i: usize) -> (u32, usize) {
let my_u32 = u32::from_be_bytes([buf[i], buf[i+1], buf[i+2], buf[i+3]]);
i += 4;
// i is returned so the caller can read the rest of the buffer
return (my_u32, i);
}
pub fn marshal_f32(number: f32, buf: &mut Vec<u8>) {
buf.extend_from_slice(&number.to_be_bytes());
}
pub fn unmarshal_f32(buf: &[u8], mut i: usize) -> (f32, usize) {
let my_f32 = f32::from_be_bytes([buf[i], buf[i+1], buf[i+2], buf[i+3]]);
i += 4;
return (my_f32, i);
}
For each data type, I had to decide how I would represent them in Rust. For integers, I decided to use an unsigned 32-bit integer (u32) because there was no need to be able to represent negative numbers and 32-bits would be sufficient since I did not foresee any of the integer values going above 2^32 in size.
For floats, I went with the 32-bit floating point type and not a 64-bit variant because such a high level of precision was unnecessary.
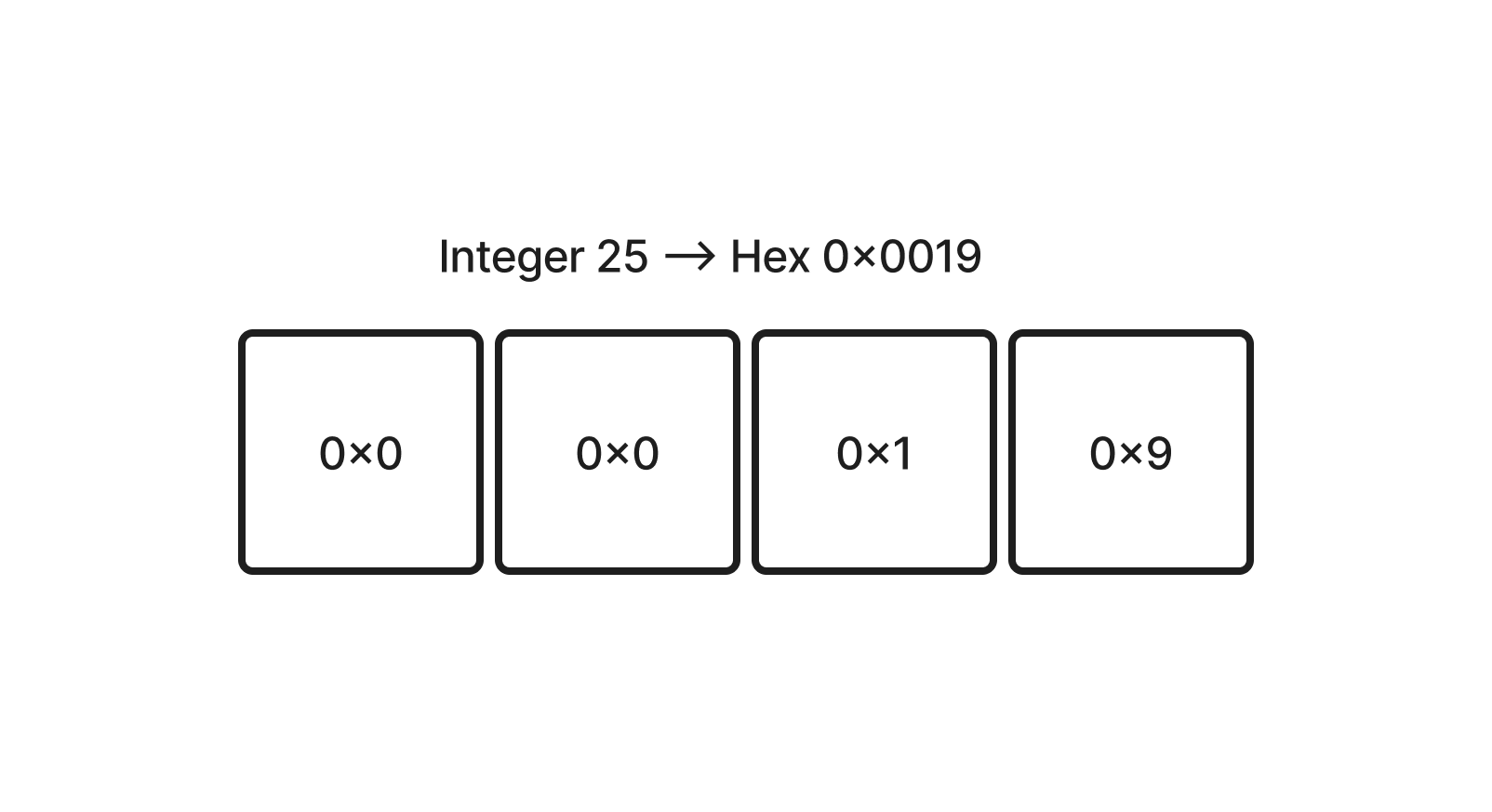
The marshaling and unmarshaling of u32 and f32 were pretty straightforward. I just had to ensure that each data type was converted to bytes in Big-endian format to ensure consistency across the system.
For example, this is how the integer 25 is marshaled (the bytes are in big-endian format).
Marshaling strings and integer Arrays
// marshaling/src/lib.rs
pub fn marshal_string(string: &str, buf: &mut Vec<u8>) {
buf.extend_from_slice(&(string.len() as u8).to_be_bytes());
buf.extend_from_slice(string.as_bytes());
}
pub fn unmarshal_string(buf: &[u8], mut i: usize) -> (String, usize) {
// First read the first byte to determine length of string
let string_length: usize = buf[i].into();
i += 1;
// Then read the string from utf-8 (Rust Strings are stored as UTF-8)
let my_string = String::from_utf8_lossy(&buf[i..i+string_length]).to_string();
i += string_length;
return (my_string, i);
}
pub fn marshal_u32_array(numbers: &[u32], buf: &mut Vec<u8>) {
buf.extend_from_slice(&(numbers.len() as u8).to_be_bytes());
for number in numbers {
buf.extend_from_slice(&number.to_be_bytes());
}
}
pub fn unmarshal_u32_array(buf: &[u8], mut i: usize) -> (Vec<u32>, usize) {
// First read the first byte to determine length of array
let array_length: u8 = buf[i];
i += 1;
// Then read the array
let mut my_array: Vec<u32> = Vec::with_capacity(array_length.into());
for _ in 0..array_length {
let my_u32 = u32::from_be_bytes([buf[i], buf[i+1], buf[i+2], buf[i+3]]);
i += 4;
my_array.push(my_u32);
}
return (my_array, i);
}
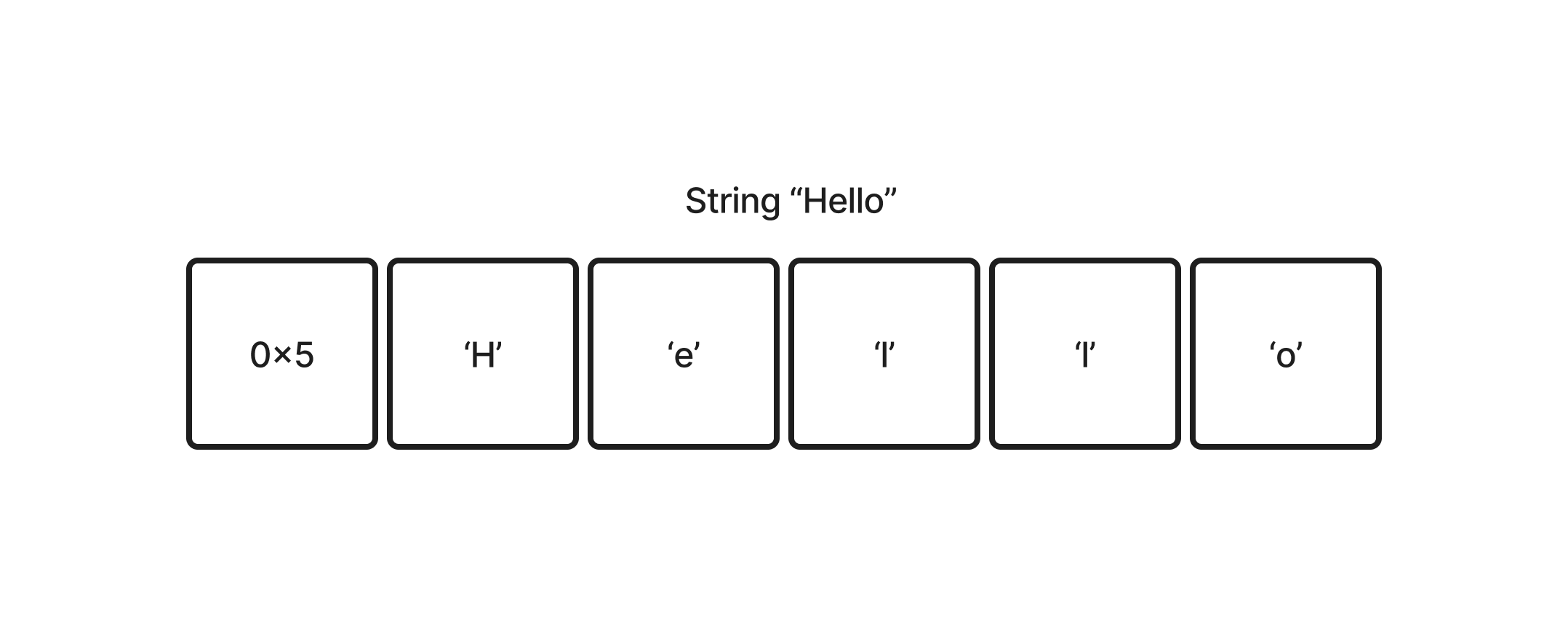
To marshal a string, I first declared the number of characters in the string, followed by the string itself. This is the case for integer arrays too.
For example, this is how the string "Hello" is marshaled (note: the bytes are in big-endian format).
Server Design and Implementation
Storing flight information
As the focus of the project was on inter-process communication instead of data persistence, flight information was just stored in memory via a Hash Map. A Hash Map was used instead of a Vector because looking up the details of a flight is constant time rather than linear time. However, I do admit that given the small size of the data, this optimization is rather negligible.
How the server works
Initialises mock flights in a
HashMapand a response cache in aHashMap.Binds to a UDP Socket.
Receive data from the socket.
Read the
request_id(first 4 bytes) and return the storedpayloadfrom the response cache if available.If the request was not already processed, read the
service_id(the next byte) and call the corresponding service handler, which returns apayloadin the form of aVec<u8>.Add the
payloadto the response cache with the(request_id, client_address)as the key.Concatenate the
request_id, theservice_idand thepayloadbefore sending the response to the client.
Handling client subscriptions
One of the services required was to enable clients to subscribe to a specific flight. Whenever a booking is made for that flight, all subscribed clients must be notified.
The clients would specify the duration which they would be subscribed for. I also needed the socket address of the client to communicate. Thus, I represented a client as a tuple (<expiry_time>, <client socket address>).
To implement this feature, I used a HashMap which I named watchlist_db whose keys were the flight IDs that were subscribed to, and whose values were vectors of clients that were subscribed.
This is an example of what watchlist_db would look like.
{
1: [(1700000000, "192.0.0.1:8080"), (1700000050, "192.0.0.1:8081")],
6: [(1700000890, "192.0.0.1:8082")]
}
Whenever seats are reserved for a particular flight, the system would use watchlist_db to determine the clients that need to be informed.
It first obtains the vector of clients using the flight ID as the key. There is a chance that the client's subscription would have already expired. So, the vector is first cleaned of expired client subscriptions. Then, each client is sent the number of seats remaining for the flight.
// fn reserve_seats_handler
// ... Preceding code
struct WatchlistEntry(u32, SocketAddr);
fn main() {
if watchlist_db.contains_key(&flight_id) {
// First, go through each entry and obtain a cleaned vector of entries.
// A cleaned vector of entries is a vector of entries that have not expired.
let mut cleaned_watchlist = Vec::<WatchlistEntry>::new();
for entry in watchlist_db.get(&flight_id).unwrap() {
if u64::from(entry.0)
> SystemTime::now()
.duration_since(UNIX_EPOCH)
.unwrap()
.as_secs()
{
cleaned_watchlist.push(entry.clone());
}
}
// Then, go through each entry of the cleaned vector and call inform_client.
for entry in cleaned_watchlist.iter() {
inform_client(socket, entry.1, flight_id, flight.seats);
}
// Update the watchlist
watchlist_db.insert(flight_id, cleaned_watchlist);
};
// ... Rest of code
}
Hold on, isn't UDP unreliable...?
The User Datagram Protocol (UDP) is a connectionless protocol that does not guarantee the delivery of packets. So instead of relying on the transport layer for reliability, I will be handling the re-transmission and de-duplication of packets at the application layer.
On the client, it waits only 5 seconds for a response from the server before it times out and retries.
On the server, its role is to listen for requests and answers with a response and is not concerned with ensuring the client receives the response. Thus, there is no need for timeouts here.
However, there is a chance that the response is lost before reaching the client. This would cause the client to timeout and retransmit the same request. This is still acceptable for idempotent requests because no state is being modified. However, for non-idempotent requests (e.g. reserving seats), such a pattern would give undefined behavior if not properly handled.
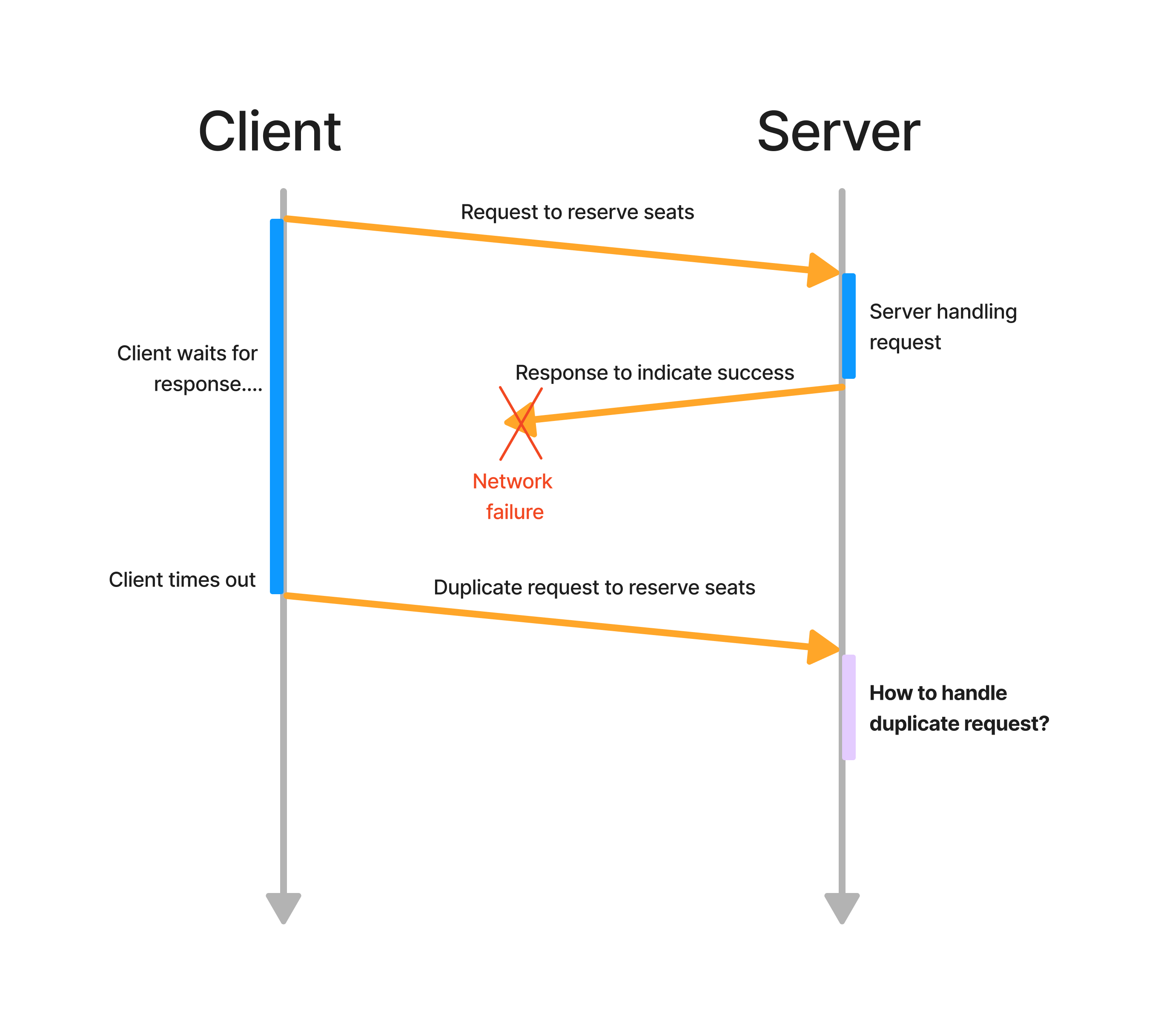
For example, say a client wishes to reserve 1 seat for a particular flight and sends a request to the server to do so. Assuming the request reaches the server successfully, the server will process the request and mutate the state by subtracting 1 seat from the flight. Next, it will send a response to the client, indicating a successful seat reservation request.
Now, assume that this response is lost in transmission and is not received by the client. The client would then time out and retransmit the request. Assume again that the request reaches the server successfully.
How should the server deal with this duplicate request? Should it process it again, or should it disregard it? This is the concept of invocation semantics.
By processing it again, we would be following the "at-least-once" invocation semantics. By recognizing the duplicate request and handling it appropriately, we would be following either the "at-most-once" invocation semantics.
What's the better choice? If the server chooses to process the request again, it would mutate the state again by subtracting an additional 1 seat from the flight. Effectively, 2 seats have now been booked. This doesn't seem right, since the client only intended to book 1 seat!
The other choice is to recognize the duplicate request and respond with a copy of the previously sent response. With this choice, the state would not be mutated further. This seems like the right choice!
This is how I've implemented the server following "at-most-once" invocation semantics:
// server/src/main.rs
fn main() {
// Initialise the response cache to "remember" previously sent responses.
let mut response_cache: HashMap<ResponseCacheKey, ResponseCacheValue> = HashMap::new();
// Now, after receiving a request, check if it has already been processed.
let response_cache_key = ResponseCacheKey {
request_id,
client_addr,
};
if response_cache.contains_key(&response_cache_key) {
// Send the cached response!
send_cached_response()
// Terminate early
}
// If this is not a duplicate request, handle the request normally.
payload = handle_request()
// Save the response into the cache.
response_cache.insert(
ResponseCacheKey {
request_id,
client_addr,
},
ResponseCacheValue {
response_payload: payload.clone(),
},
);
// Send the response.
send_response()
}
And finally, I now have a server that can work well with UDP!
Conclusion
And that's about it!
This was my first foray into Rust and it has been a delight to use. Any potential errors are immediately visible as I'm writing the code (thanks to the rust-analyzer), and the compiler even gives the exact change I need to make! As someone who loves a good developer experience, I am really glad I chose to complete this project in Rust.
If you are new to Rust and want to quickly learn it, I highly recommend this resource, which is a more interactive version of "The Book". It'll also bring you through the installation phase and also gives you tips on how to set up your IDE.
Thanks for reading!
Subscribe to my newsletter
Read articles from XingXiang Ong directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
XingXiang Ong
XingXiang Ong
I am a software engineer from Singapore who is passionate about web development and learning in general!