What happens when you type www.google.com in the address bar?
 ArunKumar Sri Sailapathi
ArunKumar Sri Sailapathi
You type www.google.com in the address bar and within a fraction of a second (mostly!), the Google web page is displayed on your screen. Have you ever wondered what actually happens in the background in order for the browser to render the page to you?
If you're curious, please read on.
IP Address fetching (from cache)
In order for the browser to load Google's page, it first needs to know the IP address of the machine/server that hosts Google's page.
It first tries to locate it in the browser's cache. (Browsers generally cache the IP addresses for quicker lookups)
If the IP address is not found in the browser's cache, then it goes up one level and looks in the OS's cache.
If it's not found, it looks up in the Router's cache.
If it's not found, it looks in the ISP's cache. (ISPs can be any internet service provider that you use. eg.) Vodafone, AT&T, T-Mobile, Xfinity, ...)
At any point in the above steps, if the IP is found, it immediately is returned to the browser. Let's say, it's not found anywhere above, the browser makes a DNS lookup.
DNS Lookup

The browser hits the DNS recursor/resolver with the query (eg. google.com). If the IP address is present in the DNS resolver, it is returned from here. If not, ...
DNS resolver queries the Root nameserver.
If it's not found there the Root nameserver returns the address of the TLD (Top Level Domain) server. (TLDs can be .com, .org, .edu, ...) This is kind of a directory that maintains the records of various domains against their TLDs.
As the query involves a
.comTLD, the resolver makes a request to the.comTLD server.If it's not particularly known at the TLD server, then it queries the ANAME server (Authoritative Nameserver) with the IP.
ANAME server responds with the IP address of the given URL (www.google.com) and this is returned all the way to the browser and it will get cached at all the touch points for faster look-ups in the future.





Finally, the browser has the IP address to which it needs to establish the connection. It's obviously the worst-case scenario but look at the steps it has to go through to just get the IP address. This is why it is highly essential to establish the connection well in advance even before making the requests. (preconnect, dns-prefetch, ... https://web.dev/preconnect-and-dns-prefetch/)
Actually connecting to the machine
With the IP address available, the browser now initiates a TCP connection with the received IP address.

It happens in 3 steps:
SYN
ACK, SYN
ACK
Fetching the data
Now that the connection is established between the client (browser) and the server (machine), the browser finally makes the actual request that was made by the user which is www.google.com (via the IP address of course)

Depending on the network bandwidth, the connection gets established with varying latencies. The HTML response (something like below) is finally served back to the browser.

Parsing and Rendering

Parsing HTML
The browser parses the HTML to construct the DOM (Document Object Model) tree.

Every browser has its own parser for doing this activity. Mozilla has Gecko HTML parse. Chrome and Safari have WebKit.
Let's for example consider this is the HTML response received:
<html>
<body>
<p>Hello World</p>
<div><img src="example.png" /></div>
</body>
</html>
and the equivalent DOM tree would be something like this:

Parsing CSS

Just like parsing HTML, the browser has to parse the CSS files as well to construct the CSSOM (CSS Object Model) tree.
Let's take this sample CSS and see how it is converted to the CSSOM tree.
body {
font-size: 16px;
}
p {
font-weight: bold;
}
span {
color: red;
}
p span {
display: none;
}
img {
float: right;
}
and the equivalent CSSOM tree would look like this:

Parsing JS
This responsibility is taken care of by the JavaScript engines. Each browser has their own JS engines enabled.
These are some of the popular JS engines:
V8 – Chrome, Opera, Node.js, MongoDB, Couchbase
Chakra – Internet Explorer, Edge
SpiderMonkey – Mozilla Firefox
Nitro - Safari

Rendering

This step merges the DOM + CSSOM trees that were constructed earlier.
Layout
In this step, the browser computes the geometry of each node. (How big or small it has to be). This is done over a series of calculations:
Determines the width, height, and location of each node.
Traversal starts at the root of the Render tree.
Takes the viewport size as the base and calculates down the tree.
The layout is responsible for the first-time calculation
Any subsequent calculations are reflow (Firefox) or layout shift (Chrome)
Reflow/Layout shift can be caused by (not refined to):
Scrolling
Inserting / Removing / Updating DOM
Changing CSS styles
…
Paint

In this step, the browser renders pixels for the calculated layouts. (Calculated layouts to Pixels). Again, this also happens over a series of steps:
Paints individual nodes on the screen
FP – First Paint
- During the first pixel painted on the screen.
FCP – First Contentful Paint
- During the first render of content from the DOM.
LCP – Largest Contentful Paint
- During the largest render of any image / DOM.
Modern browsers use GPUs for faster Paints.
Paints at the rate of max 60fps.
Compositing

Now that everything is converted as pixels (layers), now the browser has to render(or) arrange those layers in the right order. This step is critical as it would ensure efficient reflow and repainting later on.
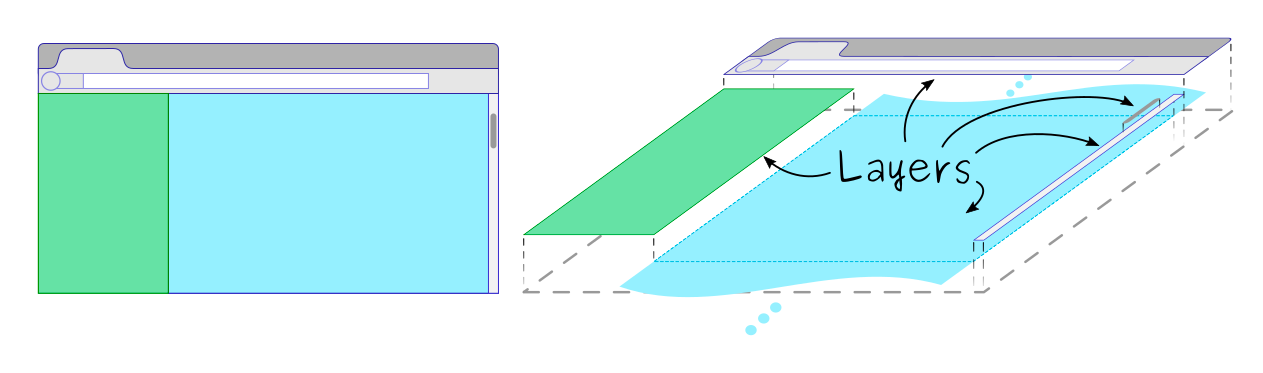
Some notes:
While painting can be a costly operation, compositing is fairly simple and can run on GPUs.
Compositor just moves the layers around to get them right.
This advantage is because painting and compositing are done in different steps.
And finally, you see Google's web page on your screen 😊

What can we "Frontend engineers" learn from this?
In order to load a trivial web page like Google's home page, the browser still needs to go through a lot of steps. Of course, it doesn't look up DNS all the time but it's still possible for some newer websites. We need to make sure we make the best use of the caches available and the preconnects and prefetches that are recommended. If you combine this with a bad network, this could potentially increase the time to load.
It doesn't stop just on loading, it also needs to query the machine to get the response. As we own our machines (mostly!), we could optimize this by sending the response as lightweight as possible. This means ensuring that we send only the critical and required data for that particular page to load rather than sending it all at once. We could also optimize the size of the payloads by adhering to all the industry standard optimization techniques. (chunking, tree-shaking, uglifying, ... just to name a few).
Once the browser gets the response, there are steps on parsing, it also takes a heavy hit if the calculation is too expensive and time-consuming. It would result in the subsequent parsers getting delayed as things happen on a single thread, in the case of JS. We could try moving heavy and complex calculations outside of main threads to web workers or service workers depending on the context and use case. Even CSS parsing could affect many times. Let's say we generally use tag names to assign styles. eg.)
.narrow p { color: red; } .narrow p.red-color-paragraph { color: red; }The first one takes a bit more time than the second one as it first tries to look for all the
ptags in the document and then narrows it down to the ones within.narrowthe class in order to apply thecolor: red. The second one on the other hand directly looks for only theptags which have the classred-color-paragraphassociated with them. (Reference: https://frontstuff.io/you-need-to-stop-targeting-tags-in-css#performance-issues)And of course, it comes with its own scalability problems as we have directly styled the tags rather than specifying them.
We also need to take care of reflows and repaints properly and efficiently. Eg. Moving elements with
translateis better than moving them with absolute /relative positions. I know this is an old and already known one but still worthy of mentioning. (Further reading: https://www.paulirish.com/2012/why-moving-elements-with-translate-is-better-than-posabs-topleft/)Then comes the most important performance metrics we generally worry about a lot. This occurs during the "Painting" stage. These metrics are:
Largest Contentful Paint (LCP)
First Input Delay (FID)
Cumulative Layout Shift (CLS)
These are called web-vital metrics. (Further Reading: https://web.dev/vitals/)
We could also make use of GPU accelerations (Hardware accelerations) in CSS in order to force the browsers to render layers/compositions via GPU rather than using CPU. This ensures things are done faster and more efficiently. We could simply as a hack force the browser to render via GPU by including the following CSS:
{ -webkit-transform: translateZ(0); -moz-transform: translateZ(0); -ms-transform: translateZ(0); -o-transform: translateZ(0); transform: translateZ(0); }Essentially it does nothing, but in the background, it enables the browser to render things via GPU and we can write the rest of the logic which can be rendered as well. (Further reading: https://blog.teamtreehouse.com/increase-your-sites-performance-with-hardware-accelerated-css)
So, there you have it all, and below are some of the popular browser engines:
WebKit
- Safari, Google Chrome (older versions), …
Blink
Forked from Webkit
Google Chrome, Latest Microsoft Edge(79+), Amazon Silk, …
Gecko
- Mozilla Firefox, Thunderbird
Trident
- Internet Explorer
Hope you liked this in-depth article on how web browsers work from when given a URL, to the point of rendering pixels on your screen and beyond.
Cheers
Arunkumar Sri Sailapathi
Subscribe to my newsletter
Read articles from ArunKumar Sri Sailapathi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
ArunKumar Sri Sailapathi
ArunKumar Sri Sailapathi
I am a passionate front-end engineer and an aspiring entrepreneur. I like coding and building products from the scratch. I plan to write about some of the interesting things that I came across during my 10+ years of professional career.