Making Money From Hacks On The Blockchain Using Python (In-theory)
 Jonathan
JonathanTable of contents

Last year I saw a tweet showcasing, Curve, a crypto decentralized exchange, had a very wide price discrepancy as a result of the Midas hacker selling his loot from the exploit on the platform. This immediately caught my attention and got me thinking. Wouldn’t this imply that whenever a hack occurs on the blockchain there will, at times, be a price discrepancy on the different platform(s)? This could be as a result of users moving their assets to safety or in a case similar to what the Midas exploiter did. I ultimately pushed the idea to the back of my mind and continued searching for another alpha.
It wasn’t until December that the thought pattern resurfaced having had a front-row seat to the debacle that was the Midas Hack. Sure, the Nomad hack happened on a bridge while the Midas exploit occurred on a decentralized exchange I couldn’t help but attempt my theory regardless. My goal was to research how arbitrage or more specifically MEV plays out in the dark forest that is Ethereum.
But what is MEV you ask? MEV is a measure of the profit a blockchain miner can make through their ability to arbitrarily include, exclude, or re-order transactions within the blocks they produce. This simply means that anytime a new block on a blockchain is being created, there is some residual value left over outside of what it took to generate that block. This was what I was after in my pursuit of this project framing it as a question would be to say, “Was there any MEV in a post-Midas Hack world?”. I then set off on what I thought would be a 2-week journey to build an optimized python algorithm to determine if there was a potential opportunity, or what is known as an MEV Searcher.
MEV appears in the wild in numerous forms on the blockchain but for my use case, it would be decentralized exchange arbitrage. This arbitrage is the simplest and notoriously the most competitive.

Let us look at an example of what this would look like: Assume there are 2 decentralized exchanges, Uniswap and another called Sushiswap. For now, think of these “decentralized exchanges” are places where users go swap one token for another. In our example, we are going to take a token pair, ETH / DAI. This means that a person has the option to swap Ether for DAI and vice-versa. Both DEXs (decentralized exchanges) have the ETH / DAI token pair listed on their exchanges but with one major glaring issue. Uniswap has the token pair listed at a lower price than Sushiswap. What a person could do is buy ETH on Uniswap and sell it on Sushiswap.
A transaction of this nature would look something like this:
Swap 1 ETH → 1 DAI on Uniswap
Swap 1 DAI → 1.5 ETH on Sushiswap
I want you to take keen note of the .5 here in our example. This is the MEV. It is the value received outside of what it took to swap these tokens. This type of arbitrage as you can now see comes down to the observance of token pairs which explains the reason why it is so competitive. Hundreds of thousands of MEV Searchers monitor token pairs for even the slightest price discrepancy. DEX arbitrage can even be taken a step further if you do some more research on the concept of flash loans. As a brief overview, this type of loan allows a user to borrow upwards of 1000 ETH (USD 1,640,400 - as of the time of writing) from decentralized financial platforms such as AAVE to conduct the arbitrage and pay back the loan within the same transaction keeping any remaining profit.
Here is a transaction detailing exactly what I gave as an example. Even though it may seem futile to participate in this highly competitive system I’d want you to remember that there are a vast number of networks, each containing its DEXs, with their token pairs which all will, at some point, contain potential arbitrage opportunity
Now, with the stage set, let me break down how I went about sniffing out if there was any MEV after the Midas exploit.
# import
import os
import monitorTweets as mt
# Main
if __name__ == "__main__":
# Check if the csv file for the tweets exists
if os.path.exists(mt.dbPath):
mt.fileDoesExist()
else:
# runs a function if the file doesn't exist to create a new csv file
mt.fileDoesNotExist()
The entirety of the code was written in python and starts with a script called main. This script's objective is to find out if a CSV file of tweets exists. Based on that whether or not that file exists will determine if the script will create a new CSV file or continue forward with the execution. For now, let us assume that the file does exist which would mean that the function, fileDoesExist would be invoked.
# Imports
import tweepy
import os
import telegram
from schedule import every, repeat, run_pending
from dotenv import load_dotenv, find_dotenv
from datetime import datetime
import csv
import pandas as pd
import tweetAnalysis as ta
# GLOBAL VARIABLES
# LOADING .env
load_dotenv(find_dotenv())
# Telegram Bot
telegramChatID = os.getenv("telegramChatID")
telegramToken = os.getenv("telegramToken")
# API KEYS
apiKey = os.getenv("apiKey")
apiKeySecret = os.getenv("apiKeySecret")
accessToken = os.getenv('accessToken')
accessTokenSecret = os.getenv('accessTokenSecret')
# BEARER TOKEN
bearerToken = os.getenv('bearerToken')
twitterAccount = os.getenv('user')
dbPath = os.getenv('dbPath')
def fileDoesExist():
# API v2
client = tweepy.Client(bearer_token=bearerToken)
# API v1.1
auth = tweepy.OAuth2BearerHandler(bearer_token=bearerToken)
api = tweepy.API(auth, wait_on_rate_limit=True)
The name of this file is called monitorTweets its function is to login into my developer portal on Twitter and pull down new tweets from a specific account. Here the script first creates two objects for both version 1.1 and 2 of the Twitter API.
# getting the clientID
usertwitterAccount = api.get_user(screen_name=twitterAccount)
tweets = client.get_users_tweets(id=usertwitterAccount.id,end_time=datetime.today(),max_results=5)
# gets the first latest tweet from a user
for eachTweet in tweets.data:
tweetID = eachTweet.id
userText = eachTweet.text
break
The older API was used to create a Twitter Account object for the variable I assigned called twitterAccount. This Twitter account is Peck Shield. I used them as they provide information about hacks on the blockchain as soon as they happen. I then pull down some tweets using the get_users_tweets function which accepts:
the id of a user’s Twitter account
the date when you want to pull tweets from
the number of tweets you want to pull down
An issue arose where the API only allowed a minimum of five tweets to be extracted each time. I didn’t need the last 5 tweets from Peck Shield’s account, only the last one. To solve this I created a simple for loop to skim through the data within the tweets variable and break once it has run once which would address our 5-tweet minimum issue.
df = pd.read_csv(dbPath)
result = df.isin([tweetID]).any().any()
if result:
send(f"No New Tweets found from: {usertwitterAccount.screen_name}", chat_id=telegramChatID, token=telegramToken)
else:
with open(dbPath, "a", newline='', encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow([usertwitterAccount.id, tweetID, userText])
send("new tweets condition raised")
ta.analyseTweet(userText)
I wanted the tweets to be placed into the CSV file we spoke about earlier so I could track which tweets have been analysed already.
In order not to populate that CSV file with duplicate entries I created a data frame to read the file and create the variable result which takes the tweet ID I pulled down from the latest tweet and checks if it exists within my file.
The ‘isin’ method returns a boolean data frame of the given dimension, the first any() will return a series of boolean values and the second any() will return a single boolean value.
If the value of the result variable is True then I send off a message to Telegram saying that there are no new tweets. I created a telegram bot as a means to keep me updated on the status anytime my code ran. The hope here is that eventually, I will deploy the script to AWS or as a cron job so I’d want to see what is going on every time it ran.
On the other hand, if the result variable returned a False boolean then the script would add a new entry of who the tweet came from (the user’s Twitter ID), which tweet was it and finally the text of the tweet. A message is sent to my Telegram and the text of the tweet is sent off to be analysed in the next script.
def analyseTweet(tweet: str):
# Link extraction
unshortener = UnshortenIt()
# list of possible blockexplorers that we can connect to
blockexplorers = ['polygonscan.com/tx/', 'etherscan.io/tx/', 'snowtrace.io/tx/', 'bscscan.com/tx/']
The next script is named tweetAnalysis. It contains a single 20-line function called analyseTweet. The function’s purpose is to accept a string which would represent a tweet and extract the transaction details and block explorer of the tweet. Think of a block explorer as an easy method to visualise the blockchain. The example transaction I showed you before is a perfect example of what we would be working with. That block explorer was named, etherscan and allows anyone to view every single transaction that has happened on the Ethereum network since its inception.
To get working I instantiated an UnshortenIt object. This was being used as anytime a tweet is extracted using the API any link is converted to a shortened Twitter link which isn’t usable. UnshortenIt, as you would have already guessed, takes a given link and unshortens it. Following that, I created a list of every possible block explorer which we will eventually use to gather the token information from.
# regex to search for the twitter shortened links in tweets
tweetRegex = re.compile(r"[a-zA-Z]+://t\\.co/[A-Za-z0-9]+", re.IGNORECASE)
link = [unshortener.unshorten(uri=eachWord.group()) for eachWord in tweetRegex.finditer(tweet) for eachLink in blockexplorers if re.search(eachLink, unshortener.unshorten(uri=eachWord.group()))]
I created a regex to outline what I would want from the given tweet and then used list comprehension to find the words I want within the tweet.
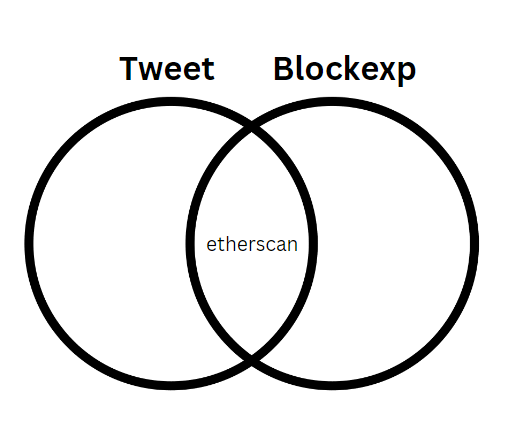
As an explainer for the list comprehension, it would work similarly to a Venn diagram containing two circles. One represents the tweet we sent over from the previous script and the second represents the list of block explorers. The point of intersection would be all the words from the tweet (after being unshortened) which match the list of block explorers.
# finds the hash from the link
txHash = re.findall(r"/tx/([A-Za-z0-9]+)", link[0])[0]
# iterates over all blockexplorers and checks if the link is in there
whichExplorer = [element for element in blockexplorers if element in link[0]][0]
# sends TF the transactions hash to know exactly which tx we are querying + sends over the explorer so we can connect to the correct chain
tf.getTokens(txHash, whichExplorer)
After locating the links which will lead to a block explorer the script then takes the transaction hash, which is on every block explorer link, and assigns that to a variable. Which explorer we are going to scan for tokens is then determined by taking the link variable and checking it against the list of block explorers.
The transaction hash and blockchain explorer are then sent to the next script tokenFetecher.
# imports
from getPool import extractAddress
import os
from web3 import Web3, HTTPProvider
from dotenv import load_dotenv, find_dotenv
from ratelimiter import RateLimiter
from pycoingecko import CoinGeckoAPI
from polygonscan import PolygonScan
#from etherscan import Etherscan
#from etherscan import Snowtrace
#from bscscan import BscScan
# LOADING the .env file
load_dotenv(find_dotenv())
# the parameter is the unique tx hash of the tx being queries & the specific blockexplorer the tx is coming from
def getTokens(txHash:str, blockExplorer:str):
# checks the blockexploer given arguement from TA and determines which blockchain to connect to
match blockExplorer:
case 'polygonscan.com/tx/':
# instantiate a web3 remote provider
endPoint = os.getenv('endpoint')
try:
w3 = Web3(HTTPProvider(endPoint))
except Exception as err:
print(err)
As the name implies TokenFetecher is used to gather the token data given the transaction hash and block explorer.
The single function of the script, getTokens, achieves this by using match-case to determine which blockchain we will connect to. However, as of the time of writing the different python packages have an issue when you have them installed on your system as such I was only able to get polyscan working. This is fine for my use case as the hack occurred on the Polygon blockchain.
To query a blockchain we must first establish a connection to the said chain. The method I chose was to use a python library called web3. This library required a connection to an Ethereum node. An Ethereum node is simply any computer running the software needed to connect with the Ethereum network. Nodes connect to send information back and forth to validate transactions and store data about the state of the blockchain. These connections are called Providers.
Nodes are expensive to maintain and for my simple use case to spin up a new Ethereum node would be a huge undertaking for what I want to accomplish. Luckily, some websites provide us with remote access to nodes via API and one such website is GetBlock. Inside that endpoint variable is my API key which gives me access to the polygon network that allows us to instantiate a Web3 object, allowing us to query blockchain information.
# the tx receipt for to gather all tokens which were traded
txReceipt = w3.eth.get_transaction_receipt(txHash)
tokenAdressList = [str(eachElement.address) for eachElement in txReceipt.logs]
# this takes each element inside of the list and map it a dictionary deleting any duplicates and assign NO values inside of the dictionary - from stackoverflow
uniqueTokenAddressList = list(dict.fromkeys(tokenAdressList))
Using the Web3 object we take the transaction hash from our previous script and pull down all the details in a readable format. From there a token list is built by taking all the addresses of each token involved in the transaction. The Midas hacker used a myriad of the same token in his endeavour which resulted in numerous logged entries of the same token but I only needed the individual unique tokens from this transaction. To create a list of unique values I created a uniqueTokenAddressList which takes each element inside of the list and maps it to a dictionary deleting any duplicates and assigning no values to the keys inside of the dictionary.
tokenDict = {}
for eachAddress in uniqueTokenAddressList:
# we need the unique abi of each specific address
match blockExplorer:
case 'polygonscan.com/tx/':
with PolygonScan(os.getenv('polyscan'),False) as blockScan:
abi = blockScan.get_contract_abi(eachAddress)
# the contract of the given address
tokenContract = w3.eth.contract(address=eachAddress, abi=abi)
So we have a unique list of token addresses. Great. However not much can be done with this information. What I need is direct interaction with the underlying smart contract to that address to figure out which token it is. They are simply programs stored on a blockchain that run when predetermined conditions are met.
To address this issue I set out to pull down each token’s contract and ask it, “Who are you?”. To do this through Web3 we need 2 components, the address we are querying and its ABI. You can think of the ABI as basically how you call functions in a contract and get data back. To do that I invoke the get_contract_abi function and call that for all functions inside of my unique list. From there we now have a token contract that data can be pulled.
# API rate limiter to ensure I don't go over my calls per second
rate_limiter = RateLimiter(max_calls=3, period=2)
with rate_limiter:
# contrainsts to look for ONLYERC20 Tokens based on what is usually found in them
erc20TokenFunctionList = ['<Function balanceOf(address)>', '<Functionname()>', '<Function totalSupply()>', '<Function symbol()>', '<Functiondecimals()>', '<Function transfer(address,uint256)>']
# gets ALL functions belonging to a smart contract address, turns them into strings for better parsing
allTokenFunctionsList = [str(eachElement) for eachElement in tokenContract.all_functions()]
# using the allTokenFunctionsList it finds the matching functions with erc20TokenFunctionList
if set(erc20TokenFunctionList).intersection(allTokenFunctionsList):
tokenSymbol = tokenContract.functions.symbol().call()
tokenName = tokenContract.functions.name().call()
tokenDecimals = tokenContract.functions.decimals().call()
cg = CoinGeckoAPI()
if cg.search(tokenSymbol)['coins'] != []:
#tokenDict.update({f"{tokenSymbol}":{tokenName,tokenDecimals,eachAddress}})
tokenDict.update(
{tokenSymbol: {'name':tokenName, 'address': eachAddress, 'decimals': tokenDecimals}}
)
As with any API, there are certain limits which can’t be exceeded when you make a call. Polyscan and Coingecko are no different. For my script, I used 2 seconds with a maximum of 3 calls. With that constraint put into place, I created a list of function names which are standard among erc20 tokens. The reason why I chose specifically that type of token is that within the different hacks, the exploiter tends to swap through varying tokens some of which may be obscure tokens with no value to them. So to separate the wheat from the shaft I pulled down all of the functions from the tokenContract object and checked to see if that token is indeed the type that we want.
From there I created a set of the erc20TokenFunctionList to find any that are similar to the erc20 token function list. If similarities exist I called forth that token’s symbol, name and decimals values.
As an even greater filter, I used Coingecko to check if the symbol is on that website which would mean that it would at least have some value and legitimacy attached to it. If the token is on the website then we would add this to a dictionary defining the token’s name, address and decimals which would be sent to the next script in our lineup called getPool.
# IMPORTS
import requests
from bdexTest import arbitrage, main
from subprocess import call
# function to use requests.post to make an API call to the Kyberswap subgraph url
def getExchangePool_K(tokenDict: dict) -> None:
"""Extracts addresses given a dictionary of tokens
Args:
tokenDict (dict): Accepts the dictionary from tokenFetech.py to extract the addresses from the Tweet
"""
token1Address = '0x2791Bca1f2de4661ED88A30C99A7a9449Aa84174'.lower()
api = '<https://api.thegraph.com/subgraphs/name/kybernetwork/kyberswap-elastic-matic>'
To figure out if there is an arbitrage opportunity we would need a marketplace(s) that allows us to check for any price discrepancies between tokens. Marketplaces, where buyers meet sellers for tokens on the blockchain, are commonly referred to as decentralized exchanges. The concept behind DEXs (decentralized exchanges) is simple, instead of using the exchange itself to handle the transactions they use smart contracts.
Each DEX has a vast array of tokens and uses “liquidity pools” — in which investors lock funds in exchange for interest-like rewards — to facilitate trades. Each pool is identified by the tokens that reside in them. Take for example Uniswap’s ETH-USDC pool where users can swap Ethereum for USDC. The pools on exchanges are not limited to 2 tokens for example the platform, Curve, has a Tri-crypto pool.
So the goal of getPool is to give a dictionary of token addresses put against another token of my choice is there a pool which exists on a specific DEX that I can swap my tokens between and if so is there a potential arbitrage opportunity available?
I chose Kyberswap to be my DEX of choice as compared to the others they had a wider variety of tokens for me to work with on the Polygon network. To query Kyber I used a Subgraph, which extracts data from a blockchain, processes and stores it so that it can be easily queried via GraphQL.
for eachToken, eachValue in tokenDict.items():
token0Name = eachToken
token0Address = eachValue['address']
queryK = """
{{
token(id:"{token0Address}") {{
symbol,
name,
whitelistPools (orderBy: feeTier, orderDirection: asc, where: {{token0: "{token0Address}", token1:"{token1Address}"}}) {{
id
}}
}}
}}""".format(token0Address = token0Address.lower(), token1Address = token1Address)
# endpoint where you are making the request - ON POLYGON
request = requests.post(f'{api}'
'',
json={'query': queryK})
if request.status_code == 200:
tokenRequest = request.json()
for eachElement in tokenRequest.values():
if eachElement['token'] != None:
if len(eachElement['token']['whitelistPools']) > 1:
poolAddress = eachElement['token']['whitelistPools'][0]['id']
exchanges_address = {
'KYBERSWAP': str(poolAddress)
}
tokens_address = {
'WETH': str(token0Address),
'DAI': str(token1Address)
}
return tokens_address, exchanges_address
else:
raise Exception('Query failed. return code is {}. {}'.format(request.status_code, queryK))
To query Kyber I needed 2 tokens. The first, token0, I chose to be the token from our dictionary and our next token is USDC. I chose this particular token since it is widely used across all networks in the crypto space so you will normally find a pool with a token against it.
What the query is doing is finding a unique pool ID number given two tokens. After, an ID # is found and placed into a dictionary. The token addresses are also both placed into a dictionary.
The reason why they are improperly named is because of the use of a very useful package called bdex. It is a package and CLI tool to get data and arbitrage for specified tokens/exchange pools. Using this package I tinkered with the initialization of the class and let it accept both my token and exchange addresses. It then passes those to the menu and checks for any potential arbitrage opportunities based on the token and exchange information.
tokenDict, exchangeDict = getExchangePool_K(aDicOfToken)
arbObject = arbitrage.ArbitrageAPI(
tokenAddress = tokenDict,
exchangeAddress = exchangeDict
)
main.run_menu(arbObject)
Final Thoughts
As I stated previously at the beginning of the blog, this project was supposed to be a 2-week sprint which would entail building out useable automation but ended up being a 2-month endeavour. This whole ordeal brought to light what I had learnt during my tenure about SDLC and taught me to take careful attention to researching and scoping out a set of requirements for a project.
Only two months ago I was having thoughts about interacting with the blockchain, now here I am building out possible theories I have in my mind with carefully crafted functions.
As for the project itself, I do believe some extensions could be made to further enhance the outcomes. A few thoughts I had were adding AI to better capture the nuisance of tweets to determine if a hack occurred, reading off the content of a tweet or most of the initial tweet checking could be completely sidestepped in favour of a more direct approach in monitoring a set of given token pairs, exchanges and addresses instead of arbitrary ones which may be flung into the script.
I’m just getting started. I plan to dive deep into this rabbit hole. Write more and create more content on crypto topics. If you are into DeFi, AI or python give me a shout on Twitter. I’m more than open to a conversation on those topics.
Github link for those who want to view the entire code.
Until next time 👋
Subscribe to my newsletter
Read articles from Jonathan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jonathan
Jonathan
Writer | Reader | Developer from 🇯🇲 | Building Langchain Bots