Apache Flink on Kubernetes
 Elvis David
Elvis David
To begin, I would encourage if you have not checked my last article on Apache Flink 101: Understanding the architecture, please go through it as it will introduce you to how Flink operates.
Introduction
Apache Flink is a powerful open-source stream processing framework that allows developers to build real-time data pipelines and perform complex analytics on streaming data. With the rise of Kubernetes as a popular container orchestration platform, many organizations are looking to deploy their Flink clusters on Kubernetes for easier management and scalability.
Why should you deploy Apache Flink over Kubernetes?
For Job image distribution
Continuous deployment
For portability: From localhost to production
Kubernetes is an open-source service for managing container clusters running on different machines. It was developed by the Google team and released on September 2014.
When deploying Flink on Kubernetes, there are two main approaches:
Standalone mode
Kubernetes Native
Basic Kubernetes Concepts
A Kubernetes cluster consists of a set of worker machines which are called nodes. These worker machines are responsible for running the containerized applications and in every cluster, there is at least one worker node.
A node contains an agent process, which maintains all containers on the node and also manages how these containers are created, started and stopped. It also provides a kube-proxy, which is a server for service discovery, reverse proxy and load balancing. It is also in the node, that we find the docker engine which is used to create and manage containers on the local machine.
We also have a master node which is used to manage clusters. It runs the API server, Controller Manager and Scheduler.
Inside the worker node(s), we have the pods. A pod is the combination of several containers that run on a node. It is the smallest unit in Kubernetes for creating, scheduling, and managing resources.
Kubernetes' Architecture
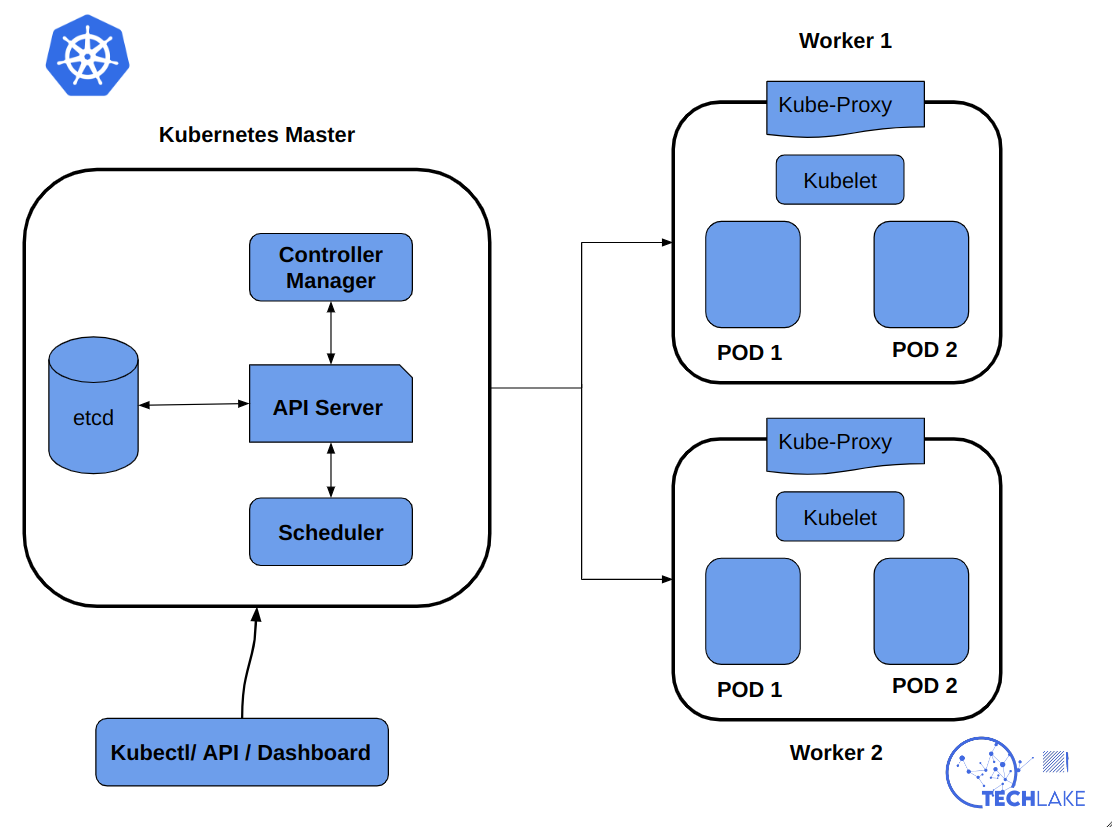
In the figure above, we showcase the architecture of Kubernetes and how the entire process runs.
The API server is a component of the master node or the control panel which is used to expose the Kubernetes API. It receives user requests and submits commands to etcd which stores user requests.
The etcd is a consistent and highly available key-value store which is used as Kubernetes' backing store for all cluster data. The etcd assigns tasks to specific machines and then the kubelet on each node finds the corresponding container to run tasks on the local machine.
Then you can submit a resource description to the Replication controller to monitor and maintain the containers which are in the cluster. You may also submit a Service description file to enable the kube-proxy to forward traffic.
The core concepts of Kubernetes
These are the core concepts of Kubernetes:
Pod replicas are managed by the Replication Controller. It guarantees that a certain number of pod replicas are active at all times in a Kubernetes cluster. The Replication Controller starts new containers if the number of pod replicas is less than the desired amount. If not, it destroys the additional containers in order to preserve the desired number of pod replicas.
Persistent Volumes (PVs) and Persistent Volume Claims (PVCs) are used for persistent data storage.
A Service provides a central service access portal and implements service proxy and discovery.
ConfigMap stores the configuration files of user programs and uses etcd as its backend storage.
The architecture of Flink on Kubernetes
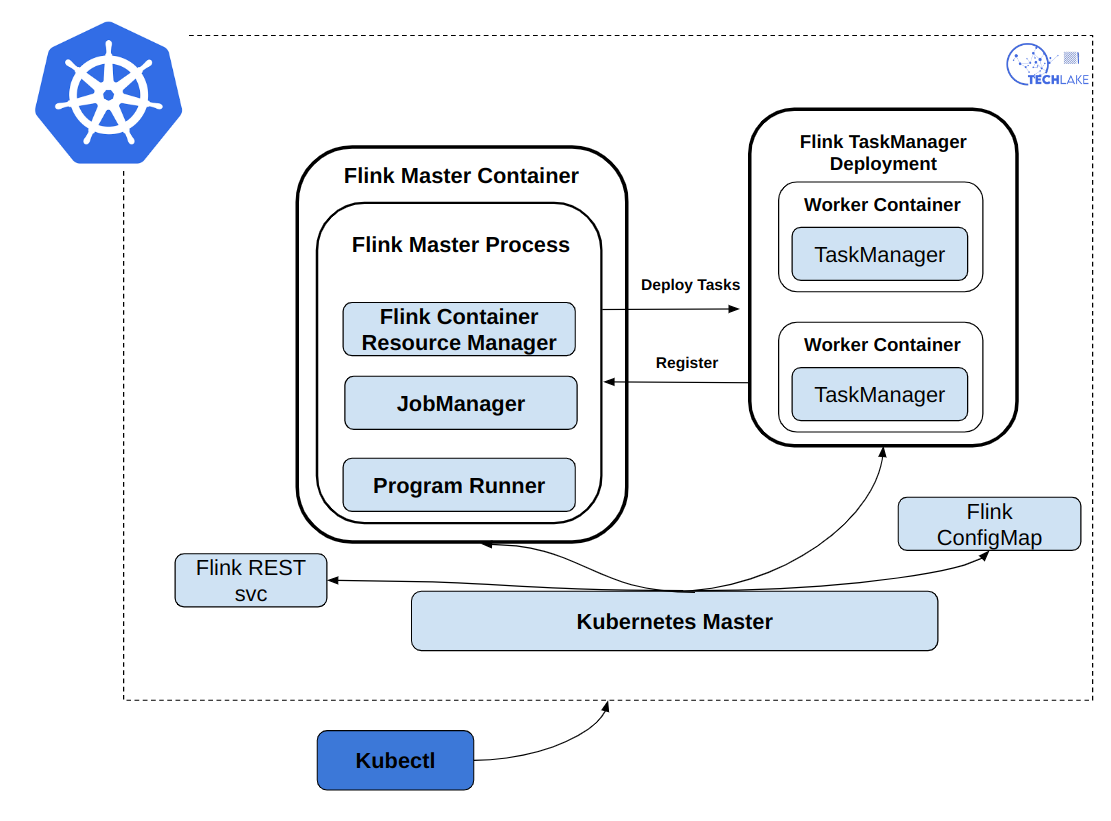
From the figure above, this is the process of running a Flink job on Kubernetes:
The first step is to submit a resource description to the Kubernetes cluster, after submitting, the master container and the worker containers are started immediately.
The master container does the work of starting the Flink master process, which consists of the Flink-containers ResourceManager, the JobManager, and the Program Runner.
After that, the worker containers start the TaskManagers, which in turn register with the ResourceManager. Then, the JobManager allocates tasks to the containers for execution.
In Flink, the master and worker containers are essentially images but they have different script commands. Through setting parameters, you can start the master or worker containers.
So now let us look at what the basic cluster will have:
The JobManager
- The execution of the JobManager is divided into two steps:
1. The JobManager is described by a Deployment to ensure that it is executed by the container of a replica and it is labelled as flink-jobmanager
2. Then we have a JobManager Service which is defined and exposed by using the service name and port number. Usually, the pods are selected based on the JobManager label.
The TaskManager
- It is also described by a deployment to ensure that is executed by the containers of n replicas. One should also define a label for this TaskManager.
Service
- The service is used in exposing the JobManager API REST, UI ports and also the JobManager and TaskManagers metrics.
- Then we have the ServiceMonitor which is used to send the metrics from the service to Prometheus.
Ingress
- The ingress is used to access the UI service port.
ConfigMaps
- It is used to pass and read configuration settings such as
flink-conf.yaml,hdfs-site.xml,logback-console.xml, .etc. if required.
The interaction of Flink on Kubernetes
The process of how Flink interacts is so simple. In this section, we are going to describe the entire process.
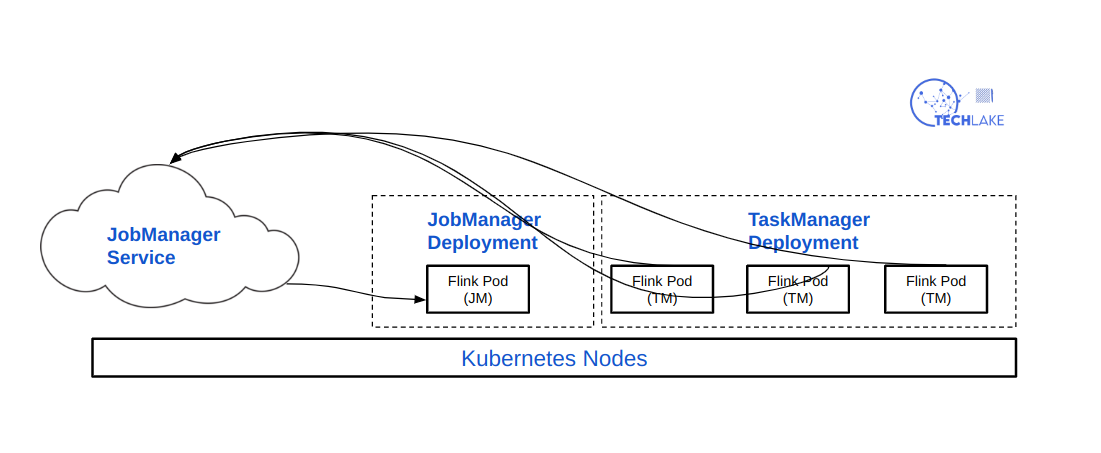
First, submit the defined resource description files, such as ConfigMap, service description files, and Deployment, to the Kubernetes cluster. Then Kubernetes will automatically complete the subsequent steps.
The Kubernetes cluster will start the Pods and run the programs as per the defined description files.
We have the following components which take part in the interaction process within the Kubernetes cluster:
The Deployment ensures that the containers of n replicas run the JobManager and TaskManager and apply the upgrade policy.
We have the service, which uses a label selector to find the JobManager's pod for service exposure.
ConfigMap - which is used to mount the
/etc/flink directory, which contains theflink-conf.yamlfile, to each pod.
Conclusion
There are benefits of deploying Apache Flink on Kubernetes such as portability and job image distribution. But for ease of deployment, it is imperative that you understand the architecture of Flink on Kubernetes and how the entire process. In this article, we have discussed the building blocks to understanding the deployment of Flink on Kubernetes.
Watch out for the next article, where we get our hands dirty with Flink clusters on Kubernetes.
Subscribe to my newsletter
Read articles from Elvis David directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Elvis David
Elvis David
Machine learning engineer and technical writer. Crafting innovative solutions and clear communication. 3 years of experience.