DataOps: A Brief Introduction
 Andrew Sharifikia
Andrew SharifikiaBackground
The volume of data that is currently collected and processed is perhaps the most spectacular effect of the digital revolution. According to IDC, we generated approximately two zettabytes (ZB) of digital information in 2010, worldwide, and about 44 zettabytes in 2020. (Forbes)
This increase in data production and collection is significant, and since the pandemic stretched from 2020 up to the present, many economies, businesses, and lifestyles around the world were forced to update themselves and to try to connect to their end parties with online unprecedented methods. This significantly impacted how much data is created and a drastic jump in the necessity of the data management field was sensed across almost all business fields around the world.
I think we can all agree that moving forward, as a global community, humanity will invest more in data-driven approaches since it has already seen the effectiveness of proper data analysis on business strategies and market growth.
In Essence
Just like DevOps, DataOps revolves around incorporating agile methodologies in how data is handled throughout the business; this includes all the steps such as collecting raw data, data transformation, data curing, data access control, data storage architectural design, data storage capacity planning, data analyses, and business value extraction and incorporation.
DataOps is not limited to AI projects but enterprises that successfully incorporate AI into their business strategy depend on DataOps more seriously, so some of these operations are specifically implemented for machine learning steps such as feature engineering and handling data outliers.
Most of the above data-handling-related procedures can be categorized under the Data Lifecycle Management (DLM) umbrella.
Data Lifecycle Management (DLM)
Managing the flow of information from extracting newer ones to storage and cleaning the deprecated ones, is in the governance of DLM. Just like a state machine, data is categorized into different tiers and states according to business strategies.
Tiers: We'll be discussing data tiers in an extensive article later, but to make it short: the tier of data is the ranking of data based on how often it's requested by the application flow.
States: At the very point of collection, data are considered raw data, meaning no transformation has been applied yet. The next step is to clean and transform the data which would then enter the (pre-) processed data phase. Afterward, data will enter in either one of two final phases: deprecation which will lead to deletion, or archiving which will lead to being stored in a higher tier (less important, less relevant) data storage.
Predominantly, DLM covers three major aspects:
Data Security and Access Control Management
Generally, direct write access to production data should be prohibited. But read access to some information should also be restricted in some cases; e.g. Personal Identifiable Information (PII) of users, sensitive business strategy related, or user private usage information.
Data Integrity (Healthiness + Recoverability)
Data must be accurate and consistent across multiple copies and DB instances.
Data Availability
Data should be accessible by valid users/operators according to the designed protocols and request handling procedures.
Notes
DLM is not a product but a comprehensive approach that involves designing different procedures, utilizing specialty software, and adhering to a set of practices.
Regarding Data States: After processing the data, new potentials could also be discovered and data generation could happen. This is because after applying some data transformation techniques, new connections and comprehensive complex data indices could be discovered which may prove to be useful even more than the original data.
In Practice
The first steps are about creating a data pipeline workflow, where raw data is generated, collected, transformed, stored, and made accessible for use in the application workflow. This involves designing the request-response flowchart, properly overestimating the amount of data generated, and choosing the right infrastructure for different components of the pipeline.
Afterward, one must incorporate monitoring tools, especially (but not limited to) in critical steps of the pipeline to verify the validity and distribution of different metrics in the data. These tools are usually categorized under Statistical Process Control (SPC) umbrella. The goal of such tools is to use statistical techniques to derive useful insights and then use them to control specific procedures throughout a process. If you're interested in statistical analysis, you can refer to the rather brief section Descriptive Statistics in my other article. SPCs make sure that data is within the valid range, missing values are reported or cured and in case of high-level anomaly detection, raise alerts for requesting immediate help.
Some of the best practices according to TechTarget are:
Establish progress benchmarks and performance measurements at every stage of the data lifecycle.
Define semantic rules for data and metadata early on.
Incorporate feedback loops to validate the data.
Use data science tools and business intelligence data platforms to automate as much of the process as possible.
Optimize processes for dealing with bottlenecks and data silos, typically involving software automation of some sort.
Design for growth, evolution and scalability.
Use disposable environments that mimic the real production environment for experimentation.
Create a DataOps team with a variety of technical skills and backgrounds.
Treat DataOps as lean manufacturing by focusing on continuous improvements to efficiency.
It's a Framework
The DataOps framework is made up of tools and technologies for AI and data management, an architecture that fosters constant innovation, cooperation between the data and engineering teams, and a strong feedback loop. DataOps blends ideas from Agile methodology, DevOps, and Lean manufacturing to accomplish these.
Agile Methodology
Incorporating an agile mindset for the data team breaks down enormous tasks into feasible chunks and allows iterative planning, and assessment. Working with data includes occasional unpredicted situations that oftentimes demand a fast response. Agile principles provide the team with enough flexibility to cover all these bases.
While incorporating the agile methodology, it's also important to note that the data team depends heavily on the goals of business strategists (analysts) and the deliverables of the development team. So it's important to keep a steady and clear communication basis between various departments, which will result in better time-cost estimation, and roadmap planning.
DevOps
Set up necessary managed online services for your company workflow. These services should monitor and deliver analytic reports to the whole ecosystem of product development and it's not totally up to the data team to manage it but the data team is the connecting bridge between many different departments ranging from feature-level development to enterprise-level planning, and this compounds the importance of DevOps infrastructural tools and services.
The data pipelines are the most essential units for the data team, and monitoring the data anomalies as well as the general trend of the performance of data storage and data collection policies, through each step of the data pipeline should be a daily task of any data-driven team.
Lean Manufacturing
Initially coined for manufacturing businesses, Lean Manufacturing is about how to maximize profit by minimizing loss and redundancies. This term was picked up quickly by DataOps teams since using raw data to generate more data and culminate everything into more profit, is a manufacturing process of its own. The 5 lean manufacturing principles are as follows:
Value
From the perspective of the client/customer, valuable aspects of the products or services must be determined. This is what directly impacts the financial gains of the company and the user base. Determining value can cleverly change the way product/service pricing model shifts in a company, as put beautifully by Reverscore:
Establishing value allows companies to define a target price. This top-down approach enables you to set pricing based on the amount of value you deliver and what that is worth to the customer. It’s a very different model to the bottom-up method of calculating your costs and then adding a fixed percentage as margin. Pricing based on value is often more profitable while still being acceptable to the end-customer.
Tweaking different features or delivery logics in A/B testing, analyzing surveys from the user base, and statistically measuring the correlation between different metrics and KPIs are all valid ways of approaching the first step.
Value Stream
Mapping the entire lifecycle of a product or service, consisting of the supply chain, source materials (or raw data), data generation (monitoring) steps, and product (data) storage are all part of this diagram. After a clear image of key profit and cost points is at hand, then these operations are classified under one of the following:
Key Values of the Company
Unavoidable Costs
Outdated or Inefficient Methods
The final bold category is what the planning and next actions of the DataOps team will target.
Flow
By removing functional bottlenecks, service flow aims to reduce lead times and guarantee a steady stream of goods or services. Micronized production replaces batching and siloed thinking, enabling businesses to launch products more quickly and shorten turnaround and development iteration time. As a result, efficiency is increased and big businesses may operate more quickly.
Pull
Pull systems are defined as opposed to push systems, which plan stocks in advance and schedule output to match sales or production projections. Teams only go on to new tasks when the previous ones have been finished, enabling them to respond to problems as they come up. By preventing anything from being created before being requested, it also helps to keep the flow going.
An Agile-based development and production strategy that is adaptable and swift enough to supply products fast is necessary for successfully deploying a pull system.
Perfection
The last and allegedly the most important base to cover is to gradually improve upon the existing process and make your way toward Perfection. From working in Japan I learned a philosophy called Kaizen (改善) which literally means improvement upon an existing base, is a management term coined by Japan, which is an approach to creating continuous improvement based on the idea that small, ongoing positive changes can reap significant improvements.
Kaizen
I've worked under the Kaizen philosophy and it took some time to get adjusted but I can also vouch for it. Kaizen is an iterative approach that involves the following steps:

While we're on the subject, here are the 10 principles of Kaizen:
Let go of assumptions.
Be proactive about solving problems.
Don't accept the status quo.
Let go of perfectionism and take an attitude of iterative, adaptive change.
Look for solutions as you find mistakes.
Create an environment in which everyone feels empowered to contribute.
Don't accept the obvious issue; instead, ask "why" five times to get to the root cause.
Cull information and opinions from multiple people.
Use creativity to find low-cost, small improvements.
Never stop improving.
(Source)
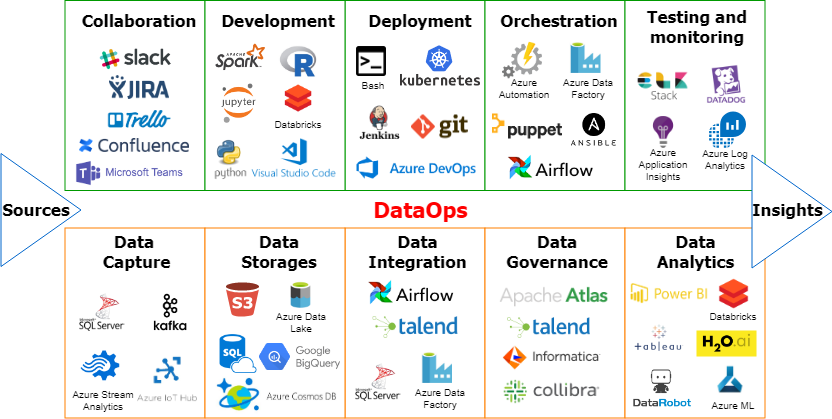
DataOps Tools and Services
The list gets updated every now and then so I encourage you to research them. But as of today, here is a compact image and a descriptive list sourced by two great publications that I respect:
Ascend.io helps ingest, transform and orchestrate data engineering and analytics workloads.
AtIan provides collaboration and orchestration capabilities to automate DataOps workloads.
Composable Analytics' platform includes tools for creating composable data pipelines.
DataKitchen's platform provides DataOps observability and automation software.
Delphix's platform masks and secures data using data virtualization.
Devo's platform automates data onboarding and governance.
Informatica has extended its data catalog tools to support DataOps capabilities.
Infoworks software helps migrate data, metadata and workloads to the cloud.
Kinaesis tools analyze, optimize and govern data infrastructure.
Landoop/Lenses helps build data pipelines on Kubernetes.
Nexla software provides data engineering automation to create and manage data products.
Okera's platform helps provision, secure and govern sensitive data at scale.
Qlik-Attunity's integration platform complements Qlik's visualization and analytics tools.
Qubole's platform centralizes DataOps on top of a secure data lake for machine learning, AI and analytics.
Software AG StreamSets helps create and manage data pipelines in cloud-based environments.
Tamr has extended its data catalog tools to help streamline data workflows.
Final Word
Is something missing? Do you need more information? Let me know in the comments and I'll try to either update this article or include your suggestions in my future works.
Stay tuned.
Subscribe to my newsletter
Read articles from Andrew Sharifikia directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Andrew Sharifikia
Andrew Sharifikia
I'm a senior full-stack developer, and I love software engineering. I believe by working together we can create wonderful assets for the world, and we can shape the future as we shape our own destiny, and no goal is too ambitious. 💫 I try to be optimistic and energetic, and I'm always open to collaboration. 👥 Contact me if you have something on your mind and let's see where it goes 🚀