The Best Introduction to Data Science
 Shubham Handore
Shubham Handore
Plainly stated, data science involves extracting knowledge from data you gather using different methodologies. As a data scientist, you take a complex business problem, compile research from it, create it into data, then use that data to solve the problem. What does this mean for you and how and where do you start?
All you need is a clear, deep understanding of a business domain and a lot of creativity – which, undoubtedly, you have. A significant area of interest in data science concerns fraud, especially internet fraud. Here, data scientists create algorithms to detect fraud and prevent it by using their skills. And this introduction to data science tutorial is where you can start!
In this introduction to data science tutorial you’ll learn everything from scratch including career fields for data scientists, real-world data science applications and how to get started in data science. So start with this introduction to data science tutorial by understanding the responsibilities of a data scientist.
What Does a Data Scientist Do?
Data Scientists work in a variety of fields. Each is crucial to finding solutions to problems and requires specific knowledge. These fields include data acquisition, preparation, mining and modeling, and model maintenance. Data scientists take raw data, turn it into a goldmine of information with the help of machine learning algorithms that answer questions for businesses seeking solutions to their queries. Each of the field is explained in this introduction to data science tutorial, starting with..
Data Acquisition: Here, data scientists take data from all its raw sources, such as databases and flat-files. Then, they integrate and transform it into a homogenous format, collecting it into what is known as a “data warehouse,” a system by which the data can be used to extract information from easily. Also known as ETL, this step can be done with some tools, such as Talend Studio, DataStage and Informatica.
Data Preparation: This is the most important stage, wherein 60 percent of a data scientist’s time is spent because often data is “dirty” or unfit for use and must be scalable, productive and meaningful. In fact, five sub-steps exist here:
Data Cleaning: Important because bad data can lead to bad models, this step handles missing values and null or void values that might cause the models to fail. Ultimately, it improves business decisions and productivity.
Data Transformation: Takes raw data and turns it into desired outputs by normalizing it. This step can use, for example, min-max normalization or z-score normalization.
Handling Outliers: This happens when some data falls outside the scope of the realm of the rest of the data. Using exploratory analysis, a data scientist quickly uses plots and graphs to determine what to do with the outliers and see why they’re there. Often, outliers are used for fraud detection.
Data Integration: Here, the data scientist ensures the data is accurate and reliable.
Data Reduction: This compiles multiple sources of data into one, increases storage capabilities, reduces costs and eliminates duplicate, redundant data.
Data Mining: Here, data scientists uncover the data patterns and relationships to take better business decisions. It’s a discovery process to get hidden and useful knowledge, commonly known as exploratory data analysis. Data mining is useful for predicting future trends, recognizing customer patterns, helping to make decisions, quickly detecting fraud and choosing the correct algorithms. Tableau works nicely for data mining.
Model Building: This goes further than simple data mining and requires building a machine learning model. The model is built by selecting a machine learning algorithm that suits the data, problem statement and available resources.
- There are two types of machine learning algorithms: Supervised and Unsupervised:
- Supervised: Supervised learning algorithms are used when the data is labeled. There are two types:
Regression: When you need to predict continuous values and variables are linearly dependent, algorithms used are linear and multiple regression, decision trees and random forest
Classification: When you need to predict categorical values, some of the classification algorithms used are KNN, logistic regression, SVM and Naïve-Bayes
Unsupervised: Unsupervised learning algorithms are used when the data is unlabeled, there is no labeled data to learn from. There are two types:
Clustering: This is the method of dividing the objects which are similar between them and dissimilar to others. K-Means and PCA clustering algorithms are commonly used.
Association-rule analysis: This is used to discover interesting relations between variables, Apriori and Hidden Markov Model algorithm can be used
Model Maintenance: After gathering data and performing the mining and model building, data scientists must maintain the model accuracy. Thus, they take the following steps:
Assess: Running a sample through the data occasionally to make sure it remains accurate
Retrain: When the results of the reassessment aren’t right, the data scientist must retrain the algorithm to provide the correct results again
Rebuild: If retraining fails, rebuilding must occur.
As you can see, data science is a complex process of various steps taking massive effort to achieve continuous, excellent results.
Now that you understand what a data scientist does, let’s look at a few examples of data science at work in the next section of the data science tutorial.
Data Science in Action: Two Examples
Data science uses its raw data to help solve problems. In each of these two cases, data helped solve a question plaguing people – in the first, a bank needed to understand why customers were leaving, this example focuses on data mining using Tableau. In the second, curiosity existed about what countries had the highest happiness rates, this example focuses on model building. Without data science, the answers couldn’t be found.
Example One: Customer Exit Rate at a Bank
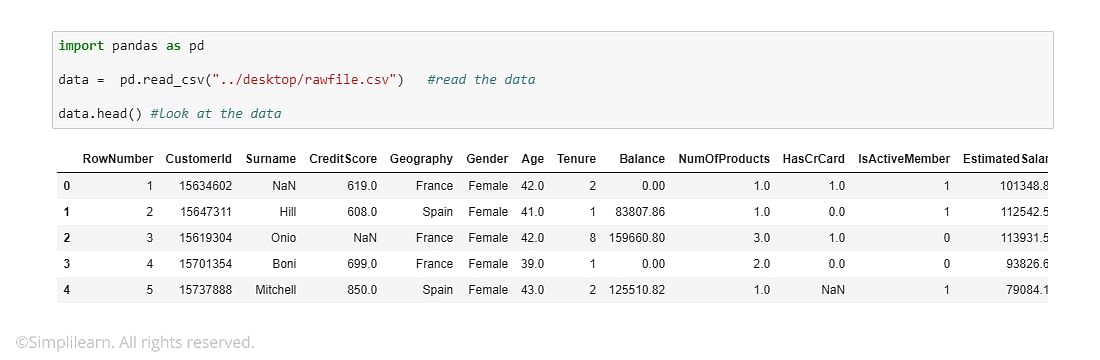
Here, a bank is doing a bit of data cleaning using Python. The customer loads a CSV file and discovers missing values in some subsets, such as the geography field. In this case, the data scientist needs to fill in the empty values with something to even out the data set, so the data is filled in with the “mean” score by writing a piece of code to do so. Otherwise, statistical data won’t work.
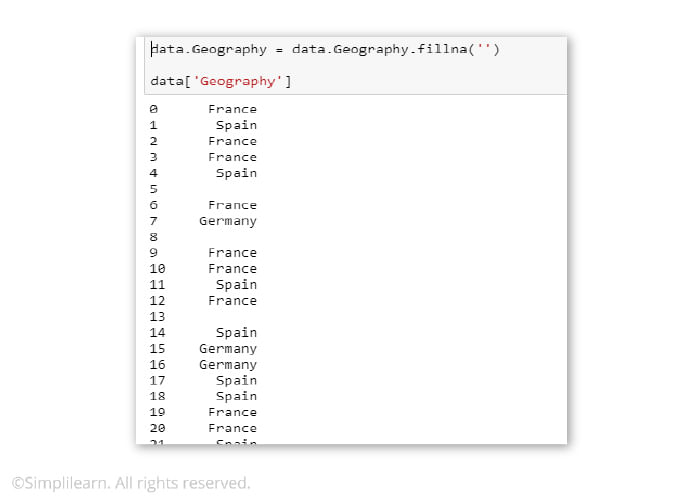
A data scientist can take other steps when data is missing, however. For example, one could drop the entire row – but that’s quite drastic and may skew the results of the study.

If all the columns are empty, though, one can drop those. In addition, when 10 to 20 rows exist, and five to seven are blank, one can drop the five to seven without worrying that the results will change much.
After the data is cleaned, the data scientist is ready to use the data for data mining.
Now, the data scientist uses Tableau to look at the exit rate of the bank’s customers based on gender, credit card holding and geography to see if these are affecting that rate.
Tableau uses a drag-and-drop system to analyze data, so, to analyze gender first, the data scientist puts “Exited” into the “Dimensions” section of Tableau and “Gender” into its “Measures” section.
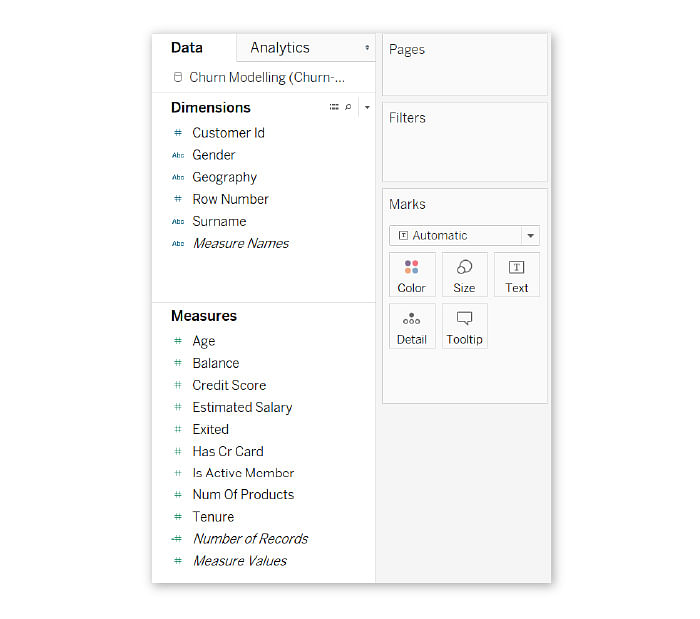
This creates two columns, one for males and one for females, and two values, 0 for those who didn’t exit, and one for those who did.
Then, a bar graph shows the percentages of the values. The data reveals a difference between females and males.
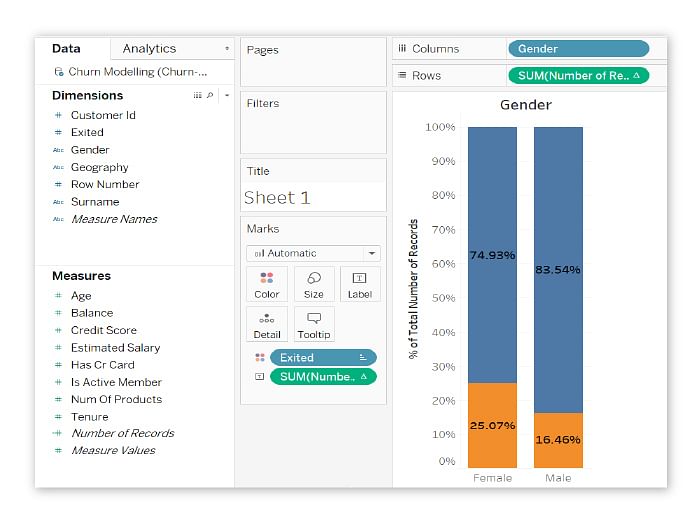
Doing the same for credit cards shows no impact, but geography also shows impact.
As a result, the study shows that the bank should consider the gender and location of its customers when analyzing how it can better retain them. Thanks to data science, then, the bank learns important information about client behavior. In the next section of the introduction to data science tutorial let’s look at some of the practical data science applications and examples.
Example Two: Predicting World Happiness
Here’s the next example of data science use and application that you’ll learn in the introduction to data science tutorial. Predicting world happiness sounds like an impossible goal, no? Thanks to data science, it’s not! Rather, using multiple linear regression model building, it’s possible to assess it. In this introduction to data science tutorial, we will see how.
To do this, one first must ascribe values. In this case, they are happiness rank, happiness value, country, region, economy, family, health, freedom, trust, generosity and dystopian residual. Not all need to be used, but some must be to make and train the model.
Using Python, the data scientist imports libraries such as pandas, numpys, and sklearns. Data is imported as CSV files from the years 2015, 2016 and 2017. Next, the scientist can concatenate the three data or build one model for each CSV. Ultimately, the head() shows the top countries with the highest happiness score.
Plots and graphs arise in Python to show which countries are the happiest and which are less happy. A scatterplot shows the correlation between happiness rank and happiness score; it’s inversely correlated. More plots show that they convey the same message, so the happiness rank score can be dropped.
As the data finishes processing, it’s possible to remove the country names and plot out the most important factors that determine world happiness. The top one, as you might imagine, is the happiness score. From the analysis, the second most important element is the economy, then family and health. Thanks to the highly detailed workings of Python’s multiple linear regression model building, we can now predict world happiness! Hoorah!
As we’ve shown, then, Data Science with Python Certification can help achieve even the loftiest sounding data analysis.
India | United States | Other Countries |
Data Science Course in Bangalore with Placement Guarantee | Data Science Course Chicago | Data Science Course South Africa |
Data Science course in Hyderabad with Placement Guarantee | Data Science Course Houston | Data Science Course Dubai |
Data Science Course in Pune with Placement Guarantee | Data Science Course NYC | Data Science Course UAE |
Data Science Course in Mumbai with Placement Guarantee | Data Science Course Tampa | Data Science Course Sydney |
Data Science Course in Delhi with Placement Guarantee | Data Science Course Dallas | Data Science Course London |
Subscribe to my newsletter
Read articles from Shubham Handore directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by