Dimensional Modelling
 Ashish GS
Ashish GS
What is Dimensional Modelling in Data Warehouses?
Dimensional modelling (DM) is a data structure technique optimised for data storage in a Data warehouse. The purpose of dimensional modelling is to optimise the database for faster retrieval of data.
A dimensional model in the warehouse is designed to read, summarise, and analyse numeric information like values, balances, counts, weights, etc. in a data warehouse. In contrast, relation models are optimised for addition, updation and deletion of data in a real-time Online Transaction System.
Elements of Dimensional Modelling
Fact
Dimensions
Attributes
Fact Table
Dimension Table
Fact
Facts are the measurements/metrics or facts from your business process. For a school (online coaching centres) business process, a measurent would be sales number by different types of courses/products.
Dimension
Dimension provides the context surrounding a business process event. In simple terms, they give who, what, and where of a fact. In the Sales business process, for the fact quarterly sales number, dimensions would be
Who – Customer Names
Where – Location
What – Product Name
Attributes
The Attributes are the various characteristics of the dimension in dimensional data modelling.
In the Location dimension, the attributes can be
State
Country
Zipcode etc.
Attributes are used to search, filter, or classify facts. Dimension tables contain attributes.
Fact Table
A fact table is a primary table in dimension modelling.
A Fact Table contains
Measurements/facts
Foreign key to the dimension table
Dimension Table
A dimension table contains the dimensions of a fact.
They are joined to fact table via a foreign key.
Dimension tables are de-normalised tables.
The Dimension Attributes are the various columns in a dimension table.
Dimensions offers descriptive characteristics of the facts with the help of their attributes.
There is no set limit given for the number of dimensions.
The dimension can also contain one or more hierarchical relationships.
Steps of Dimensional Modelling
The accuracy in creating your Dimensional modelling determines the success of your data warehouse implementation. Here are the steps to create Dimension Model
Identify Business Process / Objective
Identify Grain (level of detail)
Identify Dimensions
Identify Facts
Building of Schema
Step 1: Identify the Business Process / Objective
Before modelling the data, you should find the types of dimensional modelling appropriate for your data model. The dimensional modelling process (or any data modelling) begins with the identification of the business process that you want to track.
For example: In our case, we would want to track the revenue of each School by different types of products.
This is the most important step of the Data Modelling process, and a failure here would have cascading and irreparable defects.
Step 2: Identify Grain (level of detail)
The Grain describes the level of detail for the business problem/solution. It is the process of identifying the lowest level of information for any table in your data warehouse.
If a table contains transaction data for every day, then it should be daily granularity.
If a table contains total sales data for each month, then it has monthly granularity.
During this stage, you answer questions like
Do we need to store all the available products or just a few types of products? This decision is based on the business processes selected for the Data warehouse.
Do we store the product sale information on a monthly, weekly, daily or hourly basis? This decision depends on the nature of the reports requested.
How do the above two choices affect the database size?
- For example Admin wants to know the sales of each product in different locations on a daily basis. So the grain is “product sale information by location by date”.
Step 3: Identify the Dimension
Dimensions are nouns like date, school, courses, etc. These dimensions are where all the data should be stored. For example, the courses' dimension may contain data like name, price etc.
For example Admin wants to know sales of each product in different locations daily
Dimensions: Product, Location and Time
Attributes: For Product: Product key (Foreign Key), Name, Type, Properties
Hierarchies: For Location: Country, State, City, Street Address, Name
Step 4: Identify the Fact
This step is co-associated with the business users of the system because this is where they get access to data stored in the data warehouse. Most of the fact table rows are numerical values like price or count or rate of percentage etc.
For example Admin wants to know the sales of each product in different locations on a daily basis. So the fact here is the Sum of Sales by product by location by time.
Step 5: Build the schema
In this step, you implement the Dimension Model. There are two popular schemas
Star Schema
The star schema architecture is easy to design. It is called a star schema because the diagram resembles a star, with points radiating from a centre. The centre of the star consists of the fact table, and the points of the star are dimension tables.
The fact tables in a star schema which is the third normal form whereas dimensional tables are de-normalised.
Snowflake Schema
The snowflake schema is an extension of the star schema. In a snowflake schema, each dimension is normalised and connected to more dimension tables.
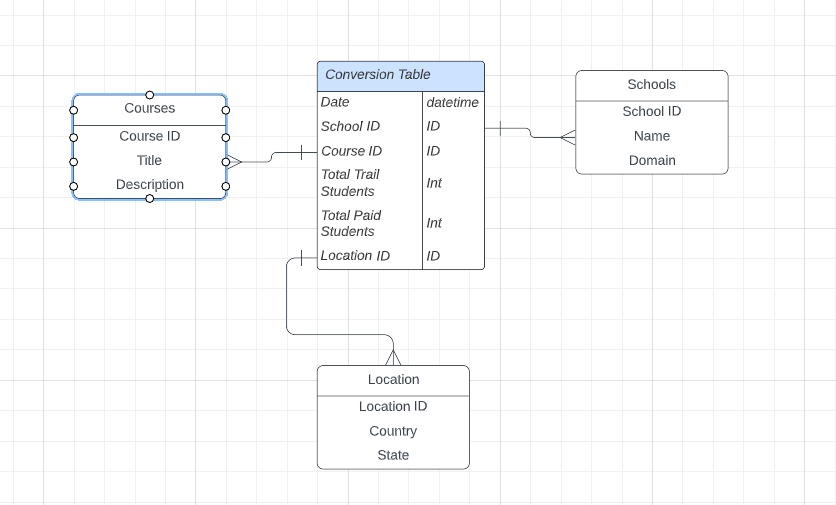
What is a Star Schema?
Star Schema is the data warehouse, in which the centre of the star can have one fact table and a number of associated dimension tables. It is known as star schema as its structure resembles a star. The Star Schema data model is the simplest type of Data Warehouse schema. It is also known as Star Join Schema and is optimized for querying large data sets.
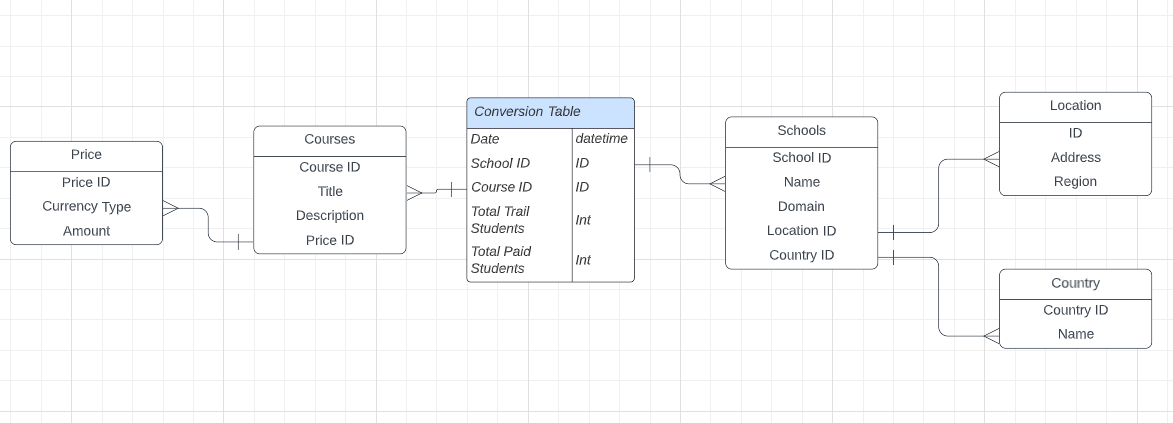
What is a Snowflake Schema?
Snowflake Schema in the data warehouse is a logical arrangement of tables in a multidimensional database such that the ER diagram resembles a snowflake shape. A Snowflake Schema is an extension of a Star Schema, and it adds additional dimensions. The dimension tables are normalized which splits data into additional tables.
Following is a key difference between Snowflake schema vs Star schema:
| Star Schema | Snowflake Schema |
| Hierarchies for the dimensions are stored in the dimensional table. | Hierarchies are divided into separate tables. |
| It contains a fact table surrounded by dimension tables. | One fact table is surrounded by dimension tables which are in turn surrounded by dimension tables. |
| In a star schema, only a single join creates the relationship between the fact table and any dimension tables. | A snowflake schema requires many joins to fetch the data. |
| Simple DB Design. | Complex DB Design. |
| Denormalized Data structure and queries run faster but may require more storage space. | Normalized Data Structure, hence will require lesser storage space. |
| High level of Data redundancy | Very low-level data redundancy |
| A single Dimension table contains aggregated data. | Data Split into different Dimension Tables. |
| Cube processing is faster. | Cube processing might be slow because of the complex join. |
| Offers higher performing queries using Star Join Query Optimization. |
Subscribe to my newsletter
Read articles from Ashish GS directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ashish GS
Ashish GS
I am a backend developer from Bengaluru