Into the heart of Multi-Layer Perceptron Neural Networks (Part-2)
 Joy Krishan Das
Joy Krishan Das
Previously, in Part - 1, we completed a forward pass through one neuron and computed the output value.
$$\hat{Y} = tanh(w_1x_1 + w_2x_2 + b)$$
Now, we will calculate the gradients of parameters [w1, w2, b] using backpropagation.
What is Backpropagation*?*
Backpropagation is a process of distributing the error back through the network from the output to the input layer. This is done by calculating the partial derivative, which measures how the loss function changes as one variable changes while keeping all other variables fixed. This helps us compute the gradient using the chain rule to describe how the function changes in multiple dimensions.
Why do we need a Loss Function?
The Loss function plays a crucial role in backpropagation because it quantitatively measures how well a network is doing on the given task. The goal of training a neural network is to minimize the value of the loss function, representing the amount of error in the network's predictions. There are many loss functions, but two commons are mean squared error(mse) and binary cross-entropy (bce).
Mean Squared Error (MSE): This loss function is used for regression problems where the goal is to predict a continuous value. It is a convex-shaped function therefore, there is a single minimum value. It is guaranteed to converge.
Binary Cross-Entropy (BCE): It is used for binary classification problems, where the goal is to predict a binary output. It is not a convex-shaped function and has multiple local minima. The shape of the graph can vary with values of
yandy_hat.
$$\displaylines{MSE_{(Loss)} = \frac{1}{n}\sum_{i = 1}^{n}(Y - \hat{Y}) \\ BCE_{(Loss)} = -(Y * log(\hat{Y}) + (1 - Y) * log(1 - \hat{Y})) }$$
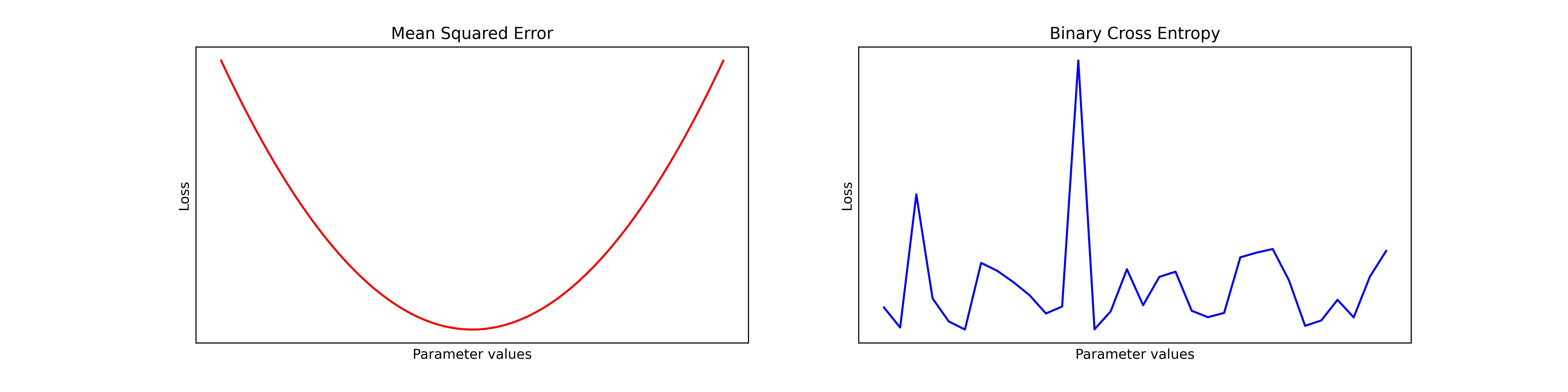
We will use mean squared error as our loss function. In the previous part, we created a Value class and initialized some value objects (which are somewhat similar to Pytorch Tensors). Therefore, we will add a grad attribute to all value objects to calculate the local gradient.
class Value:
# existing methods
def __init__(self, data):
# existing attributes
self.grad = 0.0
def __pow__(self, other): # power operation added
assert isinstance(other, (int, float)), # only supporting
# int/float powers for convenience"
out = Value(self.data**other, (self,) )
return out
def tanh(self): # tanh operation added
x = self.data
t = (math.exp(2*x) - 1)/(math.exp(2*x) + 1)
out = Value(t, (self, ))
return out
def exp(self): # exponential operation added
x = self.data
out = Value(math.exp(x), (self,))
return out
def __neg__(self): # negative operation added
return self * -1
def __sub__(self, other): # subtraction operation added
return self + (-other)
def __truediv__(self, other): # division operation added
return self * other**-1
import random
random.seed(42)
x1, x2 = Value(1.43), Value(2.34)
y = Value(1.0)
# initializing parameters
w1, w2, b = (Value(random.random()) for _ in range(3))
y_hat = (w1*x1 + w2*x2 + b).tanh()
loss = (y - y_hat)**2
The computational graph with one forward pass looks like the following. Currently, the gradient of all the parameters is zero except the loss node, which has a gradient of 1.0. This is because dl/dl = 1.0.

How the gradients are calculated during Backprop?
During backward propagation, the gradients of the output are passed back to its children with respect to the operation, where they are accumulated with other gradients coming from different parts of the computational graph. This process is repeated until the gradients of the input have been calculated.
For example,
In the case of an addition, the output gradient flows back to its children unchanged since the derivative of a sum concerning its inputs is always 1. Specifically, if the output of an addition operation is y = x1 + x2, then the gradient of the output with respect to each of the inputs is -
$$\displaylines{ \frac{dy}{dx_1}= 1; \frac{dy}{dx_2} = 1}$$
In the case of multiplication, the output gradient is multiplied by the value of the other child of the multiplication operation. This product is passed back to both children of the operation using the chain rule. Specifically, if the output of a multiplication operation is y = x1 * x2, then the gradient of the output with respect to each of the inputs is-
$$\displaylines{\frac{dy}{dx_1} = x_2; \frac{dy}{dx_2} = x_1}$$
The same occurs with all operations like subtraction, tanh, power etc. The partial derivative is used to compute the local gradient, which is then multiplied by the output gradient with respect to its immediate parent and passed on to the child as its gradient.
Therefore, let's continue constructing our Value class to track the gradients of each node in the computational graph.
class Value:
# existing methods
def __init__(self, data, _children = ()):
# existing attributes
self._prev = _children
self._backward = lambda: None # backward function to propagate
# gradients backwards
def __add__(self, other):
# existing lines of code
def backward():
self.grad += 1.0 * out.grad
other.grad += 1.0 * out.grad
out._backward = backward
return out
def __mul__(self, other):
# existing lines of code
def backward():
self.grad += other.data * out.grad
other.grad += self.data * out.grad
out._backward = backward
return out
def __pow__(self, other):
# existing lines of code
def backward():
self.grad += (other * self.data**(other - 1)) * out.grad
out._backward = backward
return out
def tanh(self):
# existing lines of code
def backward():
self.grad += (1 - t**2) * out.grad
out._backward = backward
return out
def exp(self):
# existing lines of code
def backward():
self.grad = out.data * out.grad
out._backward = backward
return out
def __neg__(self): # negative operation added
return self * -1
def __sub__(self, other): # subtraction operation added
return self + (-other)
def __truediv__(self, other): # division operation added
return self * other**-1
# building a backward graph with topological sort
def backward(self):
self.grad = 1.0 # gradient of output as 1
topo = []
visited = set()
def build_topo(n):
if n not in visited:
visited.add(n)
for child in n._prev:
build_topo(child)
topo.append(n)
build_topo(self)
for node in reversed(topo):
node._backward()
Therefore, now we can run the magic block of code to calculate the gradients of all the nodes in the computational graph.
loss.backward()
Now, the computational graph will contain all the gradients of all nodes (including the parameters and inputs).

Here, ends one step of a backward pass. :)
Subscribe to my newsletter
Read articles from Joy Krishan Das directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Joy Krishan Das
Joy Krishan Das
Software Engineer, QA at Therap (BD) Ltd.