Automated Invoice Processing with GPT-4 and Amazon Textract: Advanced Entity Extraction
 rajashekar vt
rajashekar vtTable of contents
- Introduction
- Entity Extraction in Invoice Processing
- Amazon Textract For Invoice Processing
- Extracting Tables and Forms with Amazon Textract
- Extracting Text with Amazon Textract
- Benefits of Using Amazon Textract
- Youtube Video on Extracting Text with Amazon Textract
- Enhancing Entity Extraction with GPT-3
- Enhancing Entity Extraction with GPT-4

Introduction
Invoice processing is an essential task for any business, but it can also be time-consuming and error-prone. With large volumes of invoices coming in daily, manual processing becomes challenging and can result in significant delays, inaccuracies, and costs. This is where technology can help. By revolutionizing the invoice processing process with Amazon Textract and GPT-3, businesses can significantly improve their invoicing process's accuracy, speed, and efficiency.
Entity Extraction in Invoice Processing
Entity extraction plays a crucial role in invoice processing. It is the process of automatically extracting relevant information from invoices and transforming it into structured data. This structured data can then be used for further processing, such as data entry into an accounting system or analysis. Businesses can significantly improve their invoice processing speed, accuracy, and efficiency by automating the entity extraction process.
Amazon Textract For Invoice Processing
Amazon Textract is a powerful technology that has emerged to revolutionize the process of extracting information from documents. It is a fully managed service that uses machine learning algorithms to extract text and structured data from various document types, including invoices.
It is designed to automatically recognize and extract text, tables, and form data from various document types, including invoices. The technology is highly accurate and can even identify and extract information from scanned documents, making it ideal for businesses that process large invoices.
To use Amazon Textract for invoice processing, businesses need to upload the invoices to the Amazon Textract service. The service then uses machine learning algorithms to automatically extract the relevant information from the invoices and convert it into structured data. This structured data can then be used for further processing, such as data entry into an accounting system or analysis.
Here are a few methods showing invoice processing with Amazon Textract.
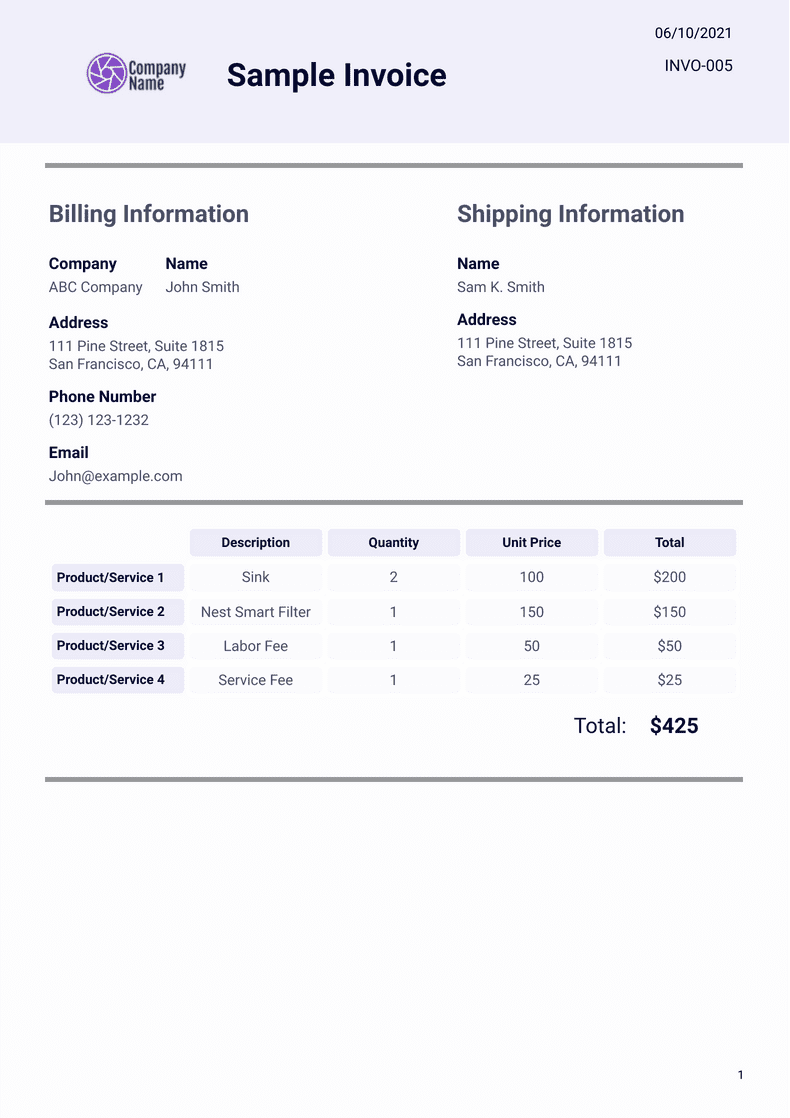
Extracting Tables and Forms with Amazon Textract
We will extract the tables and form fields from the invoice using the analyze_document method of textract.
#import necessary libraries
import boto3
from trp import Document
import pandas as pd
Importing libraries: The code imports necessary libraries like boto3 for connecting to Amazon Textract and s3 bucket, trp for parsing the response from Amazon Textract, and pandas for converting the extracted tables into a DataFrame.
s3=boto3.resource('s3',region_name='your-region-name',aws_access_key_id='your access-key',aws_secret_access_key='your-secret-access-key')
s3BucketName = "sample-bucket-doc"
s3.create_bucket(Bucket=s3BucketName)
#upload the image into the bucket
documentName='sample_invoice.jpg'
s3.Bucket(s3BucketName).upload_file(documentName, documentName)
Creating an S3 bucket: An S3 bucket is created using the boto3 resource object with the necessary access credentials. The sample invoice image is uploaded to this S3 bucket.
#initialize textract client
textract = boto3.client('textract',region_name='your-region-name',aws_access_key_id='your access-key',aws_secret_access_key='your-secret-access-key')
Initializing the Textract client: The Textract client is initialized with the access credentials and the region name.
#obtain the response with featuretypes forms and tables
response = textract.analyze_document(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
},
FeatureTypes=["FORMS","TABLES"])
Analyzing the document: The sample invoice document is analyzed using the analyze_document method of the Textract client. The method is passed the S3 object containing the sample invoice and the desired feature types as inputs. In this case, the feature types are "FORMS" and "TABLES".
#Extracting Tables from Response
def map_blocks(blocks, block_type):
return {
block['Id']: block
for block in blocks
if block['BlockType'] == block_type
}
blocks = response['Blocks']
tables = map_blocks(blocks, 'TABLE')
cells = map_blocks(blocks, 'CELL')
words = map_blocks(blocks, 'WORD')
selections = map_blocks(blocks, 'SELECTION_ELEMENT')
forms =map_blocks(blocks,'KEY_VALUE_SET')
def get_children_ids(block):
for rels in block.get('Relationships', []):
if rels['Type'] == 'CHILD':
yield from rels['Ids']
Extracting tables: The response obtained from the analysis is parsed to extract tables from it. A function map_blocks is defined to filter the blocks in the response and extract the blocks of type "TABLE". A nested function get_children_ids is defined to extract the child ids of a block.
#Mapping the Tables into a Dataframe
dataframes = []
for table in tables.values():
table_cells = [cells[cell_id] for cell_id in get_children_ids(table)]
n_rows = max(cell['RowIndex'] for cell in table_cells)
n_cols = max(cell['ColumnIndex'] for cell in table_cells)
content = [[None for _ in range(n_cols)] for _ in range(n_rows)]
for cell in table_cells:
cell_contents = [
words[child_id]['Text']
if child_id in words
else selections[child_id]['SelectionStatus']
for child_id in get_children_ids(cell)
]
i = cell['RowIndex'] - 1
j = cell['ColumnIndex'] - 1
content[i][j] = ' '.join(cell_contents)
dataframe = pd.DataFrame(content[1:], columns=content[0])
dataframes.append(dataframe)
print(len(dataframes))
print(dataframes[0])
Mapping tables to a data frame: The extracted table blocks are mapped to a data frame by populating the content of each cell into the data frame. The data frame is stored in a list of data frames.
Generated Table:
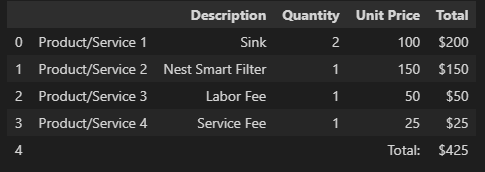
#Extracting Forms from the response
doc = Document(response)
texts=[]
for page in doc.pages:
print("Fields:")
for field in page.form.fields:
text=f"{field.key}: {field.value}"
print(text)
Extracting forms: The response obtained from the analysis is parsed using the trp library to extract forms. A document object is created from the response. The fields attribute of the form attribute of the page attribute of the Document object is iterated to extract the key-value pairs of the form fields.
Generated Form:
Fields:
Total: $425
Address: 111 Pine Street, Suite 1815 San Francisco, CA, 94111
Shipping Information: Name Sam K. Smith Address 111 Pine Street, Suite 1815 San Francisco, CA, 94111
Phone Number: (123) 123-1232
Email: John@example.com
Company: ABC Company
Name: John Smith
Forms are a great way to obtain entities from an invoice, but if we want detailed information on entities within the invoice, it is highly preferred to use the following method.
Extracting Text with Amazon Textract
We will perform OCR on this invoice using the detect_document_text method of Amazon Textract and then obtain the Raw Text, which we can later pass onto GPT-3 model to obtain the Entities.
#import libraries
import textract
import numpy as np
import boto3
Import the necessary libraries: The code imports the 'textract' library, which is a Python library for extracting text from various file formats, and 'numpy' as 'np', which is a library for scientific computing with Python. It also imports the 'boto3' library, which is a library for interacting with Amazon Web Services (AWS).
#load the image
image="sample_invoice.jpg"
with open(image,"rb") as image:
image=bytearray(image.read())
Load the image: The code defines a variable 'image' and assigns it the value "sample_invoice.jpg", which is the name of the invoice image. The code then uses the 'open' function to open the image file in binary mode, and it reads the contents of the image into memory and converts it to a byte array object.
#Initialize Client
client=boto3.client('textract',region_name='Your Region',aws_access_key_id=" Your Access Key",aws_secret_access_key="Your Secret Key")
Initialize the client: The code initializes a client object to interact with the Amazon Textract service using the 'boto3.client' method. It specifies the region of the AWS service and provides the access key and secret key required to access the service.
#Get The Response
response=client.detect_document_text(Document={'Bytes':image})
Get the response: The code calls the 'detect_document_text' method on the client object, passing in the binary representation of the invoice image as an argument. This method returns the response from the Textract service, which contains the detected text from the invoice image.
#Get The Raw OCR Text
text=""
for item in response["Blocks"]:
if item in response["Blocks"]:
if item["BlockType"]=='LINE':
#print(item["text"])
text += f"{item['Text']}"
print(text)
Get the raw OCR text: The code then iterates over the 'Blocks' in the response and concatenates the 'Text' property of each 'LINE' block type into a single string. This string contains the raw OCR text from the invoice image.
Generated Output:
OCR Raw Text: 06/10/2021 K Company INVO-005 Name Sample Invoice Billing Information Shipping Information Company Name Name ABC Company John Smith Sam K. Smith Address Address 111 Pine Street, Suite 1815 111 Pine Street, Suite 1815 San Francisco, CA, 94111 San Francisco, CA, 94111 Phone Number (123) 123-1232 Email John@example.com Description Quantity Unit Price Total Product/Service 1 Sink 2 100 $200 Product/Service 2 Nest Smart Filter 1 150 $150 Product/Service 3 Labor Fee 1 50 $50 Product/Service 4 Service Fee 1 25 $25 Total: $425 1We can't make much sense out of this Generated output, but once we pass this text onto GPT-3 or GPT-4, we can see some fruitful results.
Benefits of Using Amazon Textract
Increased speed and efficiency: By automating the entity extraction process, businesses can significantly improve the speed and efficiency of their invoice processing.
Improved accuracy: Amazon Textract's machine learning algorithms are highly accurate, reducing the risk of errors in the invoice processing process.
Reduced manual effort: Businesses can significantly reduce the manual effort required to process invoices by automating the entity extraction process.
Youtube Video on Extracting Text with Amazon Textract
Enhancing Entity Extraction with GPT-3
Entity extraction is the process of identifying and extracting specific information or entities from a large text corpus. In the context of invoice processing, entity extraction can help automatically extract information like invoice number, vendor name, invoice date, item description, and amount, among others. This information can then be used for further processing, such as data validation, categorization, and accounting.
GPT-3, or Generative Pretrained Transformer 3, is a state-of-the-art language model developed by OpenAI. GPT-3 has been trained on a massive amount of text data, making it capable of understanding and generating human-like text. This capability can be leveraged to improve the accuracy of entity extraction.
By using GPT-3, it's possible to extract entities from unstructured or semi-structured invoices with high accuracy and more flexibly than traditional entity extraction methods.
Traditional entity extraction methods, such as rule-based or machine learning-based systems, require significant manual effort to create and maintain rules or models. Moreover, these methods are limited in their ability to extract entities from new or unseen invoice formats. On the other hand, GPT-3-based entity extraction can be more flexible and scalable, as it does not rely on pre-defined rules or models. Additionally, GPT-3 can learn from the data and improve its accuracy over time, making it an ideal choice for entity extraction in invoice processing.
#import OpenAI Library
import openai
Import the OpenAI Library: The first line of the code imports the OpenAI library, which provides access to OpenAI's APIs and models.
#Authenticate with your OpenAI API Key
openai.api_key = "Your API Key"
Authenticate with the OpenAI API Key: In the next line, the code sets the API key for the OpenAI API, which is required for authentication. Replace "Your API Key" with your actual API key.
#define the prompt
ocr_text = "06/10/2021 K Company INVO-005 Name Sample Invoice Billing Information Shipping Information Company Name Name ABC Company John Smith Sam K. Smith Address Address 111 Pine Street, Suite 1815 111 Pine Street, Suite 1815 San Francisco, CA, 94111 San Francisco, CA, 94111 Phone Number (123) 123-1232 Email John@example.com Description Quantity Unit Price Total Product/Service 1 Sink 2 100 $200 Product/Service 2 Nest Smart Filter 1 150 $150 Product/Service 3 Labor Fee 1 50 $50 Product/Service 4 Service Fee 1 25 $25 Total: $425 1"
prompt= f"Extract entities and their values from the provided text, and separate them by a new line.
Text:{ocr_text}
Entities:"
Define the Prompt: In this line, a prompt specifies the task to be performed by GPT-3. The prompt provides a sample text that contains invoice information, and the task is to extract entities and their values from the provided text.
#Get The Response
response= openai.Completion.create(
model="text-davinci-003",
prompt=prompt,
temperature=0,
max_tokens=2000,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
Get the Response: The code then calls the OpenAI API with the prompt to get the response. The create() method is used to create a completion task, which is what we need to extract entities. The following parameters are used in the create() method:
model: The name of the GPT-3 model to use for the task.
* prompt: The prompt is defined in step 3.
* temperature: The temperature parameter controls the creativity of the response.
* max_tokens: The maximum number of tokens, or words, in the response.
* top_p: The top_p parameter, which controls the diversity of the response.
* frequency_penalty: The frequency_penalty parameter, which controls the frequency of the words in the response.
* presence_penalty: The presence_penalty parameter, which controls the presence of the words in the response.
entities=response["choices"][0]["text"]
Extract Entities: Finally, the code extracts the entities from the response by accessing the "choices" field and then the "text" field of the first choice. The extracted entities are then stored in the "entities" variable.
Generated Output:
Entities:
Company Name: ABC Company
Name: John Smith
Name: Sam K. Smith
Address: 111 Pine Street, Suite 1815
City: San Francisco
State: CA
Zip Code: 94111
Phone Number: (123) 123-1232
Email: John@example.com
Product/Service: Sink
Quantity: 2
Unit Price: 100
Total: $200
Product/Service: Nest Smart Filter
Quantity: 1
Unit Price: 150
Total: $150
Product/Service: Labor Fee
Quantity: 1
Unit Price: 50
Total: $50
Product/Service: Service Fee
Quantity: 1
Unit Price: 25
Total: $25
Total: $425
Enhancing Entity Extraction with GPT-4
GPT-4 is a language model that is trained on vast amounts of text data that can be used to enhance entity extraction by leveraging its natural language processing (NLP) capabilities.
There are several advantages of preferring GPT-4 over GPT-3, firstly, It can take input of 25000 tokens compared to its predecessor, which could only take 3000 tokens. It can remember the previous inputs and provides much more reasonable answers when asked random questions, whereas GPT-3 fudges the wrong answers to make them correct.
#import OpenAI Library and Authenticate with OpenAI Key
import openai
openai.api_key="Your API Key"
Import OpenAI Library and Authenticate with OpenAI Key: Same as we did with the GPT-3, we import the OpenAI library and provide our API key to authenticate with OpenAI.
#define System Role
system_role="Extract entities and thier values as a key-value pair from the provided OCR text and seperate them by a new line.
Define System Role: This is a very important part of defining our use case. we have to define a role for the system so that it tunes its behavior accordingly. This is what makes GPT-4 more reliable compared to GPT-3. It is capable of remembering your past inputs and using them to perform domain-specific tasks.
#define an example input and output
example_text="Invoicing Street Address Template.com City , ST ZIP Code BILL TO Name Address City , State ZIP Country Phone Email pp1 pp2 Pp3 P.O. # # / Taxable NOTES : Your Company Name looooo0000 ロ Phone Number , Web Address , etc. Sales Rep . Name Ship Date Description test item 1 for online invoicing test item 2 for onvoice invoicing template This template connects to an online SQL Server SHIP TO Name Address City , State ZIP Country Contact Ship Via Quantity 1 2 3 PST GST INVOICE THANK YOU FOR YOUR BUSINESS ! DATE : INVOICE # : Client # Terms Unit Price 3.00 4.00 5.50 SUBTOTAL 8.000 % 6.000 % SHIPPING & HANDLING TOTAL PAID TOTAL DUE Due Date Line Total 3.00 8.00 16.50 27.50 27.50 27.50"
example_entities="""
Company Name: Your Company Name
Phone Number: looooo0000
Web Address: Template.com
Ship To Name:
Address:
City:
State:
Zip Code:
Country:
Contact:
Quantity: 1
Quantity: 2
Quantity: 3
Unit Price: 3.00
Unit Price: 4.00
Unit Price: 5.50
Subtotal: 8.00
Taxable:
Line Total: 3.00
Subtotal: 8.00
Shipping & Handling: 6.00
Total Paid: 27.50
Total Due: 27.50"""
Define an example of input and output: You can give a few examples of the provided input and the expected output so that GPT-4 can get a context of what we are looking for. You can provide more than one example, which makes it more reliable. For simplicity, we are providing only one example where the example text was obtained from a sample invoice on which OCR was performed by Amazon Textract and the example entities are the expected entities.
#Get The Response
ocr_text = "06/10/2021 K Company INVO-005 Name Sample Invoice Billing Information Shipping Information Company Name Name ABC Company John Smith Sam K. Smith Address Address 111 Pine Street, Suite 1815 111 Pine Street, Suite 1815 San Francisco, CA, 94111 San Francisco, CA, 94111 Phone Number (123) 123-1232 Email John@example.com Description Quantity Unit Price Total Product/Service 1 Sink 2 100 $200 Product/Service 2 Nest Smart Filter 1 150 $150 Product/Service 3 Labor Fee 1 50 $50 Product/Service 4 Service Fee 1 25 $25 Total: $425 1"
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role":"system","content":system_role},
{"role":"user","content":example_text},
{"role":"assistant","content":example_entities},
{"role":"user","content":ocr_text} #pass the OCR Text obtained from Amazon Textract
]
)
Obtain the response:
Use the OpenAI API client to create a new chat completion request: Similar to how we send requests to ChatGPT API, we send requests to GPT-4 in the same manner.
Specify the model to use for the request: gpt-4
Create a list of messages to send to the API: Each message should include a "role" (either "user" or "assistant") and "content" (the text of the message). Here, we are passing the system role and the example messages as the first 3 messages and the final message includes the OCR text we obtained from the Amazon Textract. Thus using previous examples as a reference it generates the output entities.
#extracting content from the response object.
text=response["choices"][0]["message"]["content"]
Extract the Content from the response:
The response variable in the code contains the entire JSON object returned by the API. The object has several nested levels, but the relevant data is stored in the choices list, which contains a single dictionary representing the response message.
The [0] index in response["choices"][0] accesses the first and only dictionary in the choices list.The "message" key in response["choices"][0]["message"] represents the message object that contains the response text.
Finally, the "content" key in response["choices"][0]["message"]["content"] accesses the text content of the response message, which contains the entities that are extracted from the OCR text.
Generated Output:
Entities:
Date: 06/10/2021
Invoice Number: INVO-005
Company Name: K Company
Name: Name Sample Invoice
Billing Information:
Company Name: ABC Company
Contact Name: John Smith
Address: 111 Pine Street, Suite 1815
City: San Francisco
State: CA
Zip Code: 94111
Phone Number: (123) 123-1232
Email: John@example.com
Shipping Information:
Name: Sam K. Smith
Address: 111 Pine Street, Suite 1815
City: San Francisco
State: CA
Zip Code: 94111
Description: Product/Service 1
Item: Sink
Quantity: 2
Unit Price: 100
Total: $200
Description: Product/Service 2
Item: Nest Smart Filter
Quantity: 1
Unit Price: 150
Total: $150
Description: Product/Service 3
Item: Labor Fee
Quantity: 1
Unit Price: 50
Total: $50
Description: Product/Service 4
Item: Service Fee
Quantity: 1
Unit Price: 25
Total: $25
Total: $425
From the outputs generated by both GPT-3 and GPT-4, we can clearly see why GPT-4 is better suited for invoice processing than GPT-3. The entities extracted by GPT-4 are more comprehensive and accurate for invoice processing. GPT-4 extracted additional entities such as Invoice Date, Invoice Number, Billing Company Name, and Shipping Company Name, which are important information for invoice processing.
In contrast, the entities extracted by GPT-3 are more general and less relevant to invoice processing. For example, GPT-3 extracted the entities "Name" and "Phone Number" without specifying whether they belong to the billing or shipping companies. GPT-3 also did not extract the Invoice Date or Invoice Number entities.
Moreover, the entity values extracted by GPT-4 are well-structured and organized, with clear labels and consistent formatting. This makes it easier for downstream processing and analysis and for human users to read and understand the extracted information.
For More Information and Understanding of GPT-4 You can refer to this Video:
Amazon Textract has proven to be an efficient tool for invoice processing as it can extract information from invoices with high accuracy and at a faster rate than traditional methods. The integration of GPT-4 and GPT-3 has further improved the entity extraction process by providing human-like understanding and the ability to recognize complex entities.
Overall, GPT-4's entity extraction appears to be more tailored towards invoice processing, with a better understanding of the specific types of information and formats that are relevant for this task. GPT-4 can learn from domain-specific data making it a powerful tool for invoice entity extraction. By leveraging these capabilities, GPT-4 can help automate a time-consuming and error-prone task, while improving accuracy and efficiency in processing invoice data.
With these advancements in technology, the future of invoice processing looks bright. The integration of Amazon Textract with GPT-3 and GPT-4 will continue to improve and streamline the invoice processing process, making it faster, more efficient, and more accurate.
But the question remains when to use GPT-3 over GPT-4. The GPT-4 is a subtle step up from its predecessor. However, it is worth considering that it is expensive. In many use cases where you don’t need a model to process multi-page documents or “remember” long conversations, the capabilities of GPT-3 and GPT-3.5 will be just enough.
In conclusion, using Amazon Textract and GPT-4 in invoice processing is a game-changer. It is set to revolutionize the industry by making the process more efficient, accurate, and cost-effective. As OpenAI’s most advanced system, GPT-4 surpasses older versions of the models in almost every area of comparison. It is more creative and more coherent than GPT-3. It can process longer pieces of text or even images. It’s more accurate and less likely to make “facts” up. Thanks to its capabilities, it creates many new possible use cases for generative AI.
Follow FutureSmart AI to stay up-to-date with the latest and most fascinating AI-related blogs - FutureSmart AI
Looking to stay up to date on the latest AI tools and applications? Look no further than AI Demos This directory features a wide range of video demonstrations showcasing the latest and most innovative AI technologies. Whether you're an AI enthusiast, researcher, or simply curious about the possibilities of this exciting field, AI Demos is your go-to resource for education and inspiration. Explore the future of AI today with aidemos.com
Subscribe to my newsletter
Read articles from rajashekar vt directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by