The art of fuzzing-A Step-by-Step Guide to Coverage-Guided Fuzzing with LibFuzzer
 Avishek Sarkar
Avishek SarkarIntroduction
Fuzz testing or fuzzing is a widely used technique to identify vulnerabilities by automatically generating and sending random or semi-random inputs to the program. Any program that accepts arbitrary user input is a good candidate for fuzzing. Fuzzing can be applied to any software component that receives input, including libraries, operating systems, and network protocols. However, traditional fuzzing can be inefficient and miss many critical bugs. This blog will discuss coverage-guided fuzzing, a modern fuzzing technique that uses software feedback to guide input generation.
Warming up...
Before deep diving into coverage-guided fuzzing, we need to understand a few terms.
Instrumentation
Instrumentation is modifying a software program or system to collect data on its behaviour, performance, or other characteristics. In software development, instrumentation involves adding special code, called instrumentation code or probes, to a program or system to gather information about its runtime behaviour, such as the number of times a particular function is called or the amount of memory used by the program.
Instrumentation can be used for various purposes, including performance monitoring, profiling, debugging, and security testing.
Sanitizers
Code sanitizers detect and diagnose common programming errors in C and C++ code. They work by instrumenting the code during compilation and adding runtime checks to detect memory errors, undefined behaviour, and other issues that can cause crashes or security vulnerabilities.
There are several code sanitizers available, including:
Address Sanitizer (ASan): This sanitizer detects memory errors such as buffer overflows, use-after-free, and heap and stack buffer overflow. It does this by instrumenting memory accesses and adding run-time checks.
Memory Sanitizer (MSan): This sanitizer detects uninitialized memory reads. It does this by tracking memory allocation and initialization during program execution.
Undefined Behavior Sanitizer (UBSan): This sanitizer detects undefined behaviour in C, and C++ code, such as null pointer dereferences, integer overflows, and signed integer overflow.
Thread Sanitizer (TSan): This sanitizer detects race conditions and other threading issues in multi-threaded programs.
Data Flow Sanitizer (DFSan): This sanitizer detects data-flow issues such as tainted data and data leaks.
Code sanitizers are a powerful tool for detecting and fixing programming errors and can help improve the reliability and security of software. They are widely used in software development, especially for open-source projects where code contributions can come from various sources.
Code Coverage
Code coverage is a measure of how much of the source code of a software program has been executed during testing. It is a way to measure the effectiveness of a test suite by identifying which parts of the code have been executed and which have not. Code coverage is typically expressed as a percentage of the code that has been executed.
Code coverage analysis involves instrumenting the source code or compiled executable with special code that tracks which parts of the code are executed during testing. This can be done by inserting code that counts the number of times each line of code is executed or by using more advanced techniques that track the execution of branches, loops, and functions.
Code coverage analysis ensures that a software program has been thoroughly tested and all code paths have been exercised.
So... What is coverage-guided fuzzing?
Coverage-guided fuzzing is a fuzzing technique that uses code coverage information to guide the generation of inputs. It works by instrumenting the software under test (SUT) with code coverage instrumentation, which allows it to track which parts of the code have been executed during the execution of a test case. The fuzzer then generates new inputs that exercise the uncovered parts of the code to find new bugs.
The process of coverage-guided fuzzing can be broken down into the following steps:
Instrumentation: The SUT is instrumented with code coverage instrumentation. This is typically done by inserting probes into the code that record which parts of the code have been executed during the execution of a test case.
Seed Input Generation: The fuzzer generates an initial set of inputs, called seed inputs. These can be manually crafted inputs, or they can be randomly generated.
Input Mutation: The fuzzer then mutates the seed inputs to generate new test cases. The mutations can be simple, such as flipping bits or changing bytes, or more complex, such as inserting or deleting sections of the input.
Input Execution: The fuzzer executes the generated inputs on the instrumented SUT.
Coverage Feedback: The code coverage information collected during the execution of the input is used to guide the generation of new inputs. The fuzzer identifies which parts of the code were not executed during the execution of the input and prioritizes generating new inputs that exercise these parts of the code.
Repeat: Steps 3-5 are repeated until a bug is found, a time limit is reached, or a certain coverage goal is achieved.
Fuzzing using Libfuzzer
LibFuzzer is an in-process, coverage-guided, evolutionary fuzzing engine.
A crucial feature of libFuzzer is its close integration with Sanitizer Coverage and bug-detecting sanitizers: Address Sanitizer, Leak Sanitizer, Memory Sanitizer, Thread Sanitizer and Undefined Behavior Sanitizer. Using these projects ensures a wide range of memory corruption bugs and undesired application behaviour is detected. A few examples of these are Heap/Stack/Global Out Of Bounds, Use After Free, Use After Return, Uninitialized Memory Reads, Memory Leaks or Uninitialized Mutex Use.
LibFuzzer has been used to find numerous bugs and vulnerabilities in open-source software projects, including the Linux kernel, OpenSSL, and Apache.
More details on Libfuzzer can be found here- https://llvm.org/docs/LibFuzzer.html
The libFuzzer operates similarly to unit testing. We need to write a small fuzzing program (called the “harness”) and create a programming environment to quickly integrate it into projects with a callable set of functions, typically the library API.
The most straightforward integration of libFuzzer is as follows:
// fuzz_userfunction.cpp
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size) {
myfunction(Data, Size);
return 0;
}
An example C++ program
This program inputs a string and checks if the first four characters are "FUZZ". However, it has a buffer overflow vulnerability because it copies sizeof(buf) bytes of data from the input string to a buffer of only four bytes.
#include <cstring>
#include <cstdint>
#include <cstring>
int foo(const char* str) {
char buf[4];
memcpy(buf, str, sizeof(buf));
if (buf[0] == 'F' && buf[1] == 'U' && buf[2] == 'Z' && buf[3] == 'Z') {
return 1;
}
return 0;
}
Adding Libfuzzer support to the above program
#include <string>
#include <cstdint>
#include <cstring>
int foo(const char* str) {
char buf[4];
memcpy(buf, str, sizeof(buf));
if (buf[0] == 'F' && buf[1] == 'U' && buf[2] == 'Z' && buf[3] == 'Z') {
return 1;
}
return 0;
}
extern "C" int LLVMFuzzerTestOneInput(const uint8_t* data, size_t size) {
// Call the vulnerable function with the input data
foo(reinterpret_cast<const char*>(data));
return 0;
}
This code defines the LLVMFuzzerTestOneInput function, called by LibFuzzer with a sequence of bytes to test. In this case, we simply call the foo function with the input data and return 0.
Compiling the target program
Compile the program with LLVM and enable instrumentation for LibFuzzer using the following command:
clang++ -g -fsanitize=address,fuzzer fuzz_string.cpp -o fuzz_string
This command uses Clang to compile the program with LibFuzzer support.
Running the fuzz test
Create a directory called corpus and create some initial input files to use as a seed corpus. For example, create a file called input1 with the following contents:
hello
Now run the fuzz test with the following command:
./fuzz_string corpus -max_len=1000
This command runs the fuzz_stringprogram with the corpus directory as the seed corpus and a maximum input length of 1000 bytes.
root@leo5g:/home/leo/Desktop/libfuzzer_basic# ./fuzz_string corpus -max_len=1000
INFO: Running with entropic power schedule (0xFF, 100).
INFO: Seed: 3426760313
INFO: Loaded 1 modules (7 inline 8-bit counters): 7 [0x55985b9cced0, 0x55985b9cced7),
INFO: Loaded 1 PC tables (7 PCs): 7 [0x55985b9cced8,0x55985b9ccf48),
INFO: 1 files found in corpus
=================================================================
==23809==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x602000000011 at pc 0x55985b94bcc7 bp 0x7ffc1ae13150 sp 0x7ffc1ae12920
READ of size 4 at 0x602000000011 thread T0
#0 0x55985b94bcc6 in __asan_memcpy (/home/leo/Desktop/libfuzzer_basic/fuzz_string+0xd9cc6) (BuildId: f6370ceb7aef635e3af55a5536cb7b9c725ad644)
#1 0x55985b989e2e in foo(char const*) /home/leo/Desktop/libfuzzer_basic/fuzz_string.cpp:7:3
#2 0x55985b98a0f0 in LLVMFuzzerTestOneInput /home/leo/Desktop/libfuzzer_basic/fuzz_string.cpp:16:3
#3 0x55985b8b0323 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) (/home/leo/Desktop/libfuzzer_basic/fuzz_string+0x3e323) (BuildId: f6370ceb7aef635e3af55a5536cb7b9c725ad644)
#4 0x55985b8b1580 in fuzzer::Fuzzer::ReadAndExecuteSeedCorpora(std::vector<fuzzer::SizedFile, std::allocator<fuzzer::SizedFile> >&) (/home/leo/Desktop/libfuzzer_basic/fuzz_string+0x3f580) (BuildId: f6370ceb7aef635e3af55a5536cb7b9c725ad644)
#5 0x55985b8b1bd2 in fuzzer::Fuzzer::Loop(std::vector<fuzzer::SizedFile, std::allocator<fuzzer::SizedFile> >&) (/home/leo/Desktop/libfuzzer_basic/fuzz_string+0x3fbd2) (BuildId: f6370ceb7aef635e3af55a5536cb7b9c725ad644)
#6 0x55985b89ff22 in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) (/home/leo/Desktop/libfuzzer_basic/fuzz_string+0x2df22) (BuildId: f6370ceb7aef635e3af55a5536cb7b9c725ad644)
#7 0x55985b8c9c12 in main (/home/leo/Desktop/libfuzzer_basic/fuzz_string+0x57c12) (BuildId: f6370ceb7aef635e3af55a5536cb7b9c725ad644)
#8 0x7fe8bcc29d8f in __libc_start_call_main csu/../sysdeps/nptl/libc_start_call_main.h:58:16
#9 0x7fe8bcc29e3f in __libc_start_main csu/../csu/libc-start.c:392:3
#10 0x55985b894964 in _start (/home/leo/Desktop/libfuzzer_basic/fuzz_string+0x22964) (BuildId: f6370ceb7aef635e3af55a5536cb7b9c725ad644)
0x602000000011 is located 0 bytes to the right of 1-byte region [0x602000000010,0x602000000011)
allocated by thread T0 here:
#0 0x55985b98785d in operator new[](unsigned long) (/home/leo/Desktop/libfuzzer_basic/fuzz_string+0x11585d) (BuildId: f6370ceb7aef635e3af55a5536cb7b9c725ad644)
#1 0x55985b8b0232 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) (/home/leo/Desktop/libfuzzer_basic/fuzz_string+0x3e232) (BuildId: f6370ceb7aef635e3af55a5536cb7b9c725ad644)
#2 0x55985b8b1580 in fuzzer::Fuzzer::ReadAndExecuteSeedCorpora(std::vector<fuzzer::SizedFile, std::allocator<fuzzer::SizedFile> >&) (/home/leo/Desktop/libfuzzer_basic/fuzz_string+0x3f580) (BuildId: f6370ceb7aef635e3af55a5536cb7b9c725ad644)
#3 0x55985b8b1bd2 in fuzzer::Fuzzer::Loop(std::vector<fuzzer::SizedFile, std::allocator<fuzzer::SizedFile> >&) (/home/leo/Desktop/libfuzzer_basic/fuzz_string+0x3fbd2) (BuildId: f6370ceb7aef635e3af55a5536cb7b9c725ad644)
#4 0x55985b89ff22 in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) (/home/leo/Desktop/libfuzzer_basic/fuzz_string+0x2df22) (BuildId: f6370ceb7aef635e3af55a5536cb7b9c725ad644)
#5 0x55985b8c9c12 in main (/home/leo/Desktop/libfuzzer_basic/fuzz_string+0x57c12) (BuildId: f6370ceb7aef635e3af55a5536cb7b9c725ad644)
#6 0x7fe8bcc29d8f in __libc_start_call_main csu/../sysdeps/nptl/libc_start_call_main.h:58:16
SUMMARY: AddressSanitizer: heap-buffer-overflow (/home/leo/Desktop/libfuzzer_basic/fuzz_string+0xd9cc6) (BuildId: f6370ceb7aef635e3af55a5536cb7b9c725ad644) in __asan_memcpy
Shadow bytes around the buggy address:
0x0c047fff7fb0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7fc0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7fd0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7fe0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7ff0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
=>0x0c047fff8000: fa fa[01]fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8010: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8020: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8030: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8040: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8050: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
==23809==ABORTING
MS: 0 ; base unit: 0000000000000000000000000000000000000000
artifact_prefix='./'; Test unit written to ./crash-da39a3ee5e6b4b0d3255bfef95601890afd80709
Base64:
Now if we run our program, we will see that libFuzzer identifies a problem right away.
The most relevant part of the output is the stack trace, which shows us there was a heap buffer overflow and the information about the input that caused the crash, which comes at the end of the output.
That's a basic demo of how to use LibFuzzer to find crashes in a C++ program. Remember that real-world fuzzing often requires much more configuration and optimization to be effective, but this should give you an idea of the basic workflow.
Fuzzing libxml2 with libfuzzer
Setup the environment
Before we begin, make sure you have the following installed on your system:
A C++ compiler (such as GCC or Clang)
LLVM (version 10 or later)
LibFuzzer (included with LLVM)
libxml2 is a library for parsing XML documents. Before starting fuzzing, it's always good to understand the code structure of the library. You can also compile the library and check the way it works. More details can be found here -https://github.com/GNOME/libxml2
You can also read and check examples of the library execution http://www.xmlsoft.org/examples/
Based on the above link, xmlReadMemory and xmlRegexpCompile functions can be a good starting point for fuzzing. Google’s fuzzer test suite also provides a good set of example fuzzing functions https://github.com/google/fuzzer-test-suite
- Download libxml2.9.2
git clone --branch v2.9.2 --single-branch --depth 1 https://gitlab.gnome.org/GNOME/libxml2
Before compiling our target function, we need to compile all dependencies with clang. It is a good idea also to use -fsanitize=address,undefined in order to enable both the AddressSanitizer(ASAN) and the UndefinedBehaviorSanitizer(UBSAN) that catch many bugs that otherwise might be hard to find.
Compile libxml2.9.2 with instrumentation
cd libxml2 ./autogen.sh export FUZZ_CXXFLAGS="-O2 -fno-omit-frame-pointer -gline-tables-only -fsanitize=address,undefined,fuzzer-no-link" CXX="clang++ $FUZZ_CXXFLAGS" CC="clang $FUZZ_CXXFLAGS" \ CCLD="clang++ $FUZZ_CXXFLAGS" ./configure make -j$(nproc)-fsanitize=address(recommended): enables AddressSanitizer-fno-omit-frame-pointerTo get meaningful stack traces in error messages-gline-tables-onlyinfo allows one to obtain stack traces with function names, file names and line numbers (by such tools asgdboraddr2line). It doesn’t contain other data (e.g. description of local variables or function parameters).fuzzer-no-linkBy default, when you compile a program with the-fsanitize=fuzzerflag, Clang links the program with the LLVM libFuzzer library. This library provides the necessary instrumentation to generate and execute the random inputs for fuzz testing.The
fuzzer-no-linkflag is used to disable this linking process. This is useful when you want to compile the program without the LLVM libFuzzer runtime library, for example, when you want to use a different fuzzing engine or to instrument your program for fuzz testing manually.Writing the fuzz target- xmlReadMemory
To fuzz test libxml2, we need to write a fuzz target function. Create a new file called
fuzz_libxml2.cppand add the following code:#include <cstring> #include <iostream> #include <libxml/parser.h> #include <libxml/xmlerror.h> extern "C" int LLVMFuzzerTestOneInput(const uint8_t* data, size_t size) { // Initialize libxml2 parser xmlInitParser(); // Disable error output to stderr xmlSetGenericErrorFunc(nullptr, nullptr); // Parse the input data as XML xmlDocPtr doc = xmlReadMemory(reinterpret_cast<const char*>(data), size, "noname.xml", nullptr, 0); if (doc == nullptr) { // Cleanup parser xmlCleanupParser(); return 0; } // Cleanup parser xmlFreeDoc(doc); xmlCleanupParser(); return 0; }Compiling the fuzz target
Compile the fuzz target using the following command:
clang++ -O2 -fno-omit-frame-pointer -gline-tables-only -fsanitize=address -fsanitize-address-use-after-scope -fsanitize-coverage=edge,trace-cmp,trace-gep,trace-div fuzz_libxml2.cpp -I ./include ./.libs/libxml2.a -fsanitize=fuzzer -lz -o libxml-fuzzerThis command uses Clang to compile the fuzz target with LibFuzzer support and links against the libxml2 library.
Running the fuzz test
Create a directory called
corpusand create some initial input files to use as a seed corpus. For example, create a file calledinput1.xmlwith the following contents:<root> <child>hello world</child> </root>Now run the fuzz test with the following command:
./libxml-fuzzer corpus -runs=100000 -max_len=100000We will restrict the number of iterations; we will pass the
-runs=100000argument. By default, libFuzzer assumes that all inputs are 4096 bytes or smaller. To change that, either use-max_len=Nor run with a non-empty seed corpus.%[https://www.youtube.com/watch?v=zjYyItcDFws]
After starting the program, the fuzzer will either:
Probe a number of inputs lower than the limit, trigger the exit code path, save the reproducer and exit.
Probe 100000 inputs without breaking the checks and exit.

libFuzzer has tried at least 100000 inputs (#100000) and has discovered 870 inputs of 22kb total (corp: 870/22kb) that together cover 6157 coverage points (cov: 6157).
You can also see that libfuzzer has generated Recommended dictionary, which can be used for a dictionary(More details below).
In addition, when we fuzz for a long time, many samples will be generated and compiled. These samples are stored in the corpus. For example, 870 samples are generated above, and many are repeated. We can streamline them by the following method
mkdir corpus_min
./libxml-fuzzer -merge=1 corpus_min corpus
noname.xml:1: parser error : EntityRef: expecting ';'
<UTFUTF-16>Et&hוF-16>Et&hו��h-16LE>t
^
noname.xml:1: parser error : PCDATA invalid Char value 8
<UTFUTF-16>Et&hוF-16>Et&hו��h-16LE>t
^
noname.xml:1: parser error : Input is not proper UTF-8, indicate encoding !
Bytes: 0xD7 0xD7 0x68 0x2D
<UTFUTF-16>Et&hוF-16>Et&hו��h-16LE>t
^
noname.xml:1: parser error : EntityRef: expecting ';'
<UTFUTF-16>Et&hוF-16>Et&hו��h-16LE>t
^
noname.xml:2: parser error : EntityRef: expecting ';'
&hו�h
^
noname.xml:2: parser error : Premature end of data in tag UTFUTF-16 line 1
&hו�h
^
#870 DONE cov: 6217 ft: 19608 exec/s: 435 rss: 93Mb
MERGE-OUTER: successful in 1 attempt(s)
MERGE-OUTER: the control file has 238731 bytes
MERGE-OUTER: consumed 0Mb (52Mb rss) to parse the control file
MERGE-OUTER: 657 new files with 19608 new features added; 6217 new coverage edges
The corpus is now streamlined to 657 files, and code coverage has also increased.
Improving fuzzing efficiency
Being a coverage-driven fuzzing engine, libFuzzer considers a specific input interesting if it results in new code coverage, i.e. it reaches a code that has not been reached before. The set of all interesting inputs is called corpus.
Items in the corpus are constantly mutated in search of new interesting inputs. Corpus can be shared across fuzzer runs and grows over time as new code is reached.
There are several metrics you should look at to determine the effectiveness of your fuzz target:
Execution Speed
Code Coverage
Corpus Size
The following things are extremely useful for improving fuzzing efficiency, so it is strongly recommended for any fuzz target:
Seed Corpus
Fuzzer Dictionary
A vital way to improve fuzzing efficiency is to use a dictionary. This works well if the input format being fuzzed consists of tokens or has many magic values.
Let's look at an example of such an input format: XML.
XML data will have some special character sequences (or keywords). For example, there is CDATA, <!ATTLIST, etc., in the XML document. If we list these character sequences in advance, the fuzzer can directly use these keywords to combine and reduce many meaningless attempts, and at the same time, it may go to a deeper program branch.
Here we will use an XML dictionary from AFL.
https://github.com/google/AFL/blob/master/dictionaries/xml.dict
Create a corpus directory and run it on all CPUs
mkdir corpus
./libxml-fuzzer -dict=xml.dict -jobs=8 -workers=8 corpus
After running for some time, a heap buffer overflow can be observed.
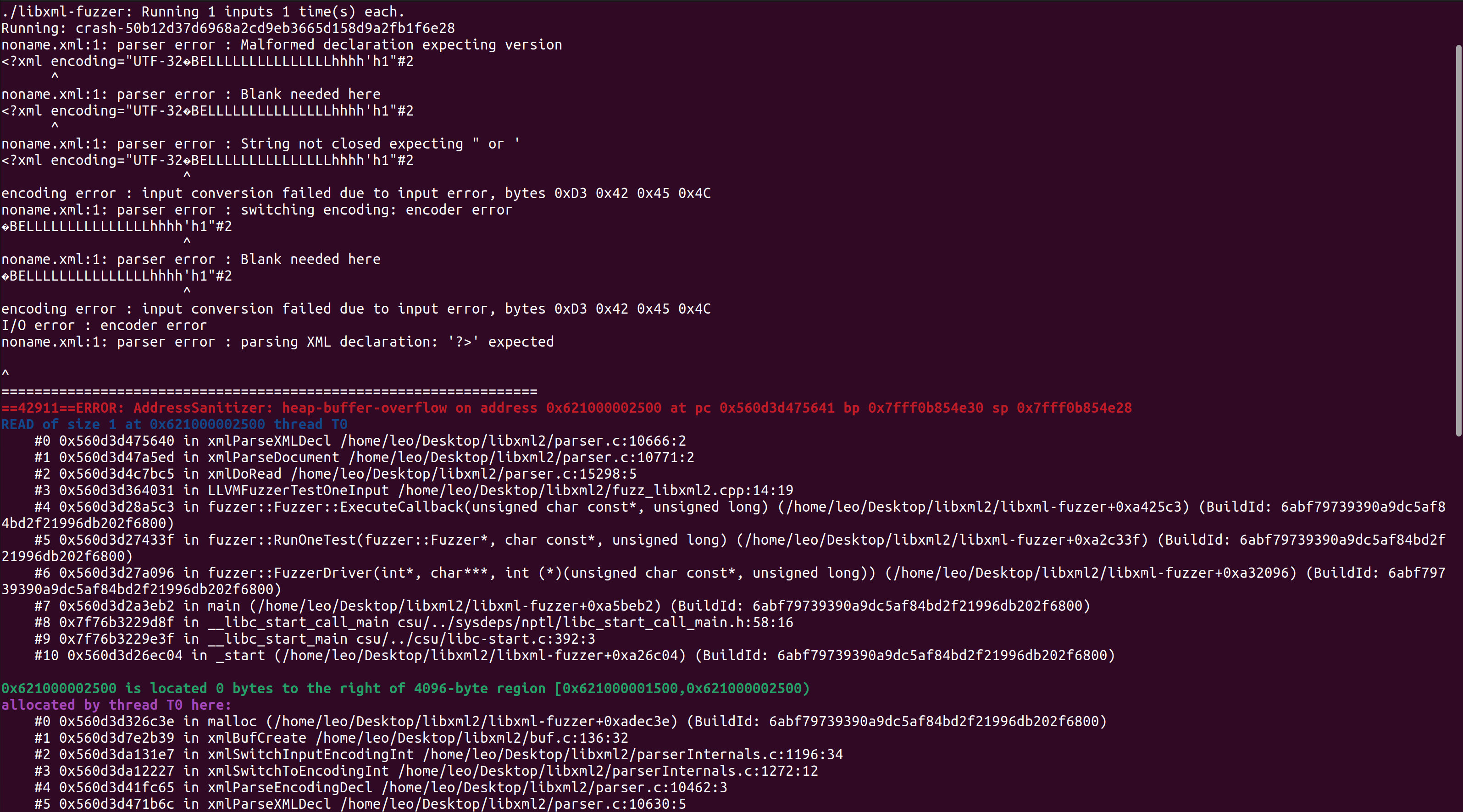
Conclusion
This tutorial demonstrated using LibFuzzer to perform coverage-guided fuzz testing on a simple program and a real-life open-source application. LibFuzzer is a powerful tool that can help you find bugs and vulnerabilities in your software with minimal effort. With some tweaking and experimentation, you can use LibFuzzer to test more complex software components and achieve better code coverage.
References
Subscribe to my newsletter
Read articles from Avishek Sarkar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Avishek Sarkar
Avishek Sarkar
Hi, I'm your friendly cybersec guy, passionate about identifying vulnerabilities in software and helping organizations improve their security posture. Throughout my career, I have always been learning new security testing/pen-testing methodologies, tools, and techniques. As a result, I stay up-to-date with the latest industry trends and best practices. Thanks for visiting my profile, and feel free to connect with me to discuss anything securely!