Data Drift
 Eshan Jairath
Eshan Jairath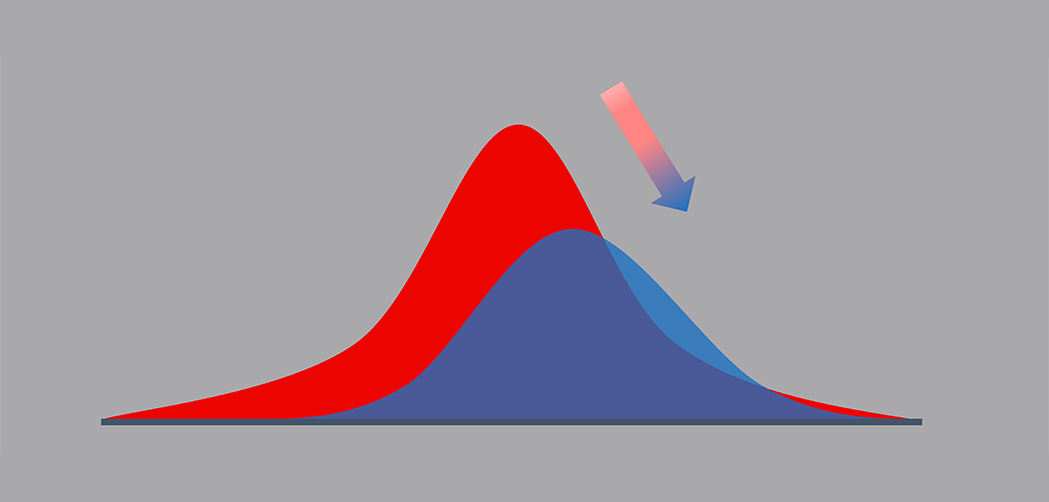
What is Data Drift?
Data drift is a phenomenon that occurs when the distribution of the data that a machine learning model is trained on differs significantly from the distribution of the data it is subsequently applied to. This can lead to a decline in model performance and is a common problem in data science. In this Blog, I am going discuss everything about data drift, what causes it, how to address it and how to detect it.
So, What causes this Data Drift?
There are several causes of data drift. One is concept drift, which occurs when the underlying concept or task the model is trying to learn changes over time. For example, a model trained to detect fraudulent financial transactions may become less effective as fraudsters adapt their tactics. Another cause is non-stationarity, which occurs when the distribution of the data changes over time, for example, due to seasonal or economic factors.
How to address Data Drift?
There are several approaches to addressing data drift. One is to continually retrain the model on new data, known as online learning. This can be done periodically or in real-time, depending on the application and the rate of change of the data..
Another approach is to use domain adaptation techniques, which aim to align the distribution of the training and test data by reducing the discrepancy between them. This can be done by using techniques such as weighting the loss function, adapting the features, or using domain-specific preprocessing steps.
One approach is to use ensemble methods, where multiple models are trained and combined to improve robustness to data drift. There are various techniques to detect data drift such as monitoring the performance of the model over time, comparing the distribution of the training
Detecting Data Drift
There are various techniques to detect data drift. These include monitoring the performance of the model over time, comparing the distribution of the training and test data, and using statistical tests to detect changes in the data.
Here's an Example in Python of how data drift can occur:
# Importing libraries
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# Generating training and test data
X_train, y_train = make_classification(n_samples=1000, n_features=5, n_classes=2, random_state=42)
X_test, y_test = make_classification(n_samples=1000, n_features=5, n_classes=2, random_state=43)
# Training a logistic regression model
clf = LogisticRegression()
clf.fit(X_train, y_train)
# Making predictions on test data
y_pred = clf.predict(X_test)
# Calculating accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
The Conclusion
In conclusion, data drift is a common problem in data science and occurs when the distribution of the data that a machine learning model is trained on differs significantly from the distribution of the data it is subsequently applied to. There are several approaches to addressing data drift, including retraining the model, using ensemble methods, and domain adaptation techniques. Additionally, various techniques can be used to detect data drift.
Subscribe to my newsletter
Read articles from Eshan Jairath directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Eshan Jairath
Eshan Jairath
Hi Everyone, I am Eshan Jairath from New Delhi, India currenlty living in Newcastle Upon Tyne, United Kingdom. As a skilled individual, I have expertise in a range of fields related to computer science🧑💻 and artificial intelligence 🤖. I have a deep understanding of data structures and algorithms, with a strong background in programming, specifically in Python 🐍 and JavaScript. I am well-versed in a range of System analysis and design, machine learning, deep learning, computer vision, and hold a Master's degree in Artificial Intelligence 🎓 as well. I have a strong specialization in developing web applications with machine learning API's. I have experience working with a variety of databases🗂️ including MongoDB, SQL, and Firebase, and am proficient in cloud technologies ☁️, specifically Microsoft Azure. (which I am certified in) 🏅. This combination of skills and education makes me highly qualified to work on a wide range of projects involving machine learning, data analysis, data science, software development, and web development. I am well-equipped 💪 to tackle complex challenges and am dedicated to staying up-to-date with the latest developments in my field. What keeps me going - " Every Great Warrior was once a defenceless child, continuously learning, evolving and waiting for his opportunity to incentivize the world. " Eshan Jairath