Measuring service level objectives (SLO) and service level indicators (SLI)
 Piyush T Shah
Piyush T ShahOverview
Service Level Objectives (SLOs) and Service Level Indicators (SLIs) are two critical concepts in Site Reliability Engineering (SRE) that help in defining, measuring, and achieving performance goals.
SLOs are a set of objectives that define the level of service that aims to provide to its users. This typically includes metrics such as uptime, response time, and error rates. SLIs, on the other hand, are measurable indicators that help track progress toward SLOs.
SLIs are typically collected and stored in a monitoring system, such as Prometheus, and can include metrics such as CPU usage, memory usage, and network latency. By defining and measuring SLOs and SLIs, organizations can gain insights into the performance of their systems, identify areas for improvement, and make data-driven decisions to optimize their infrastructure for reliability and performance.
So how can you achieve the best performance in production environments?
Define clear SLOs: Before measuring SLOs and SLIs, you need to have clear, well-defined SLOs that define the acceptable level of service for your system. These should be specific, measurable, and tied to business outcomes. For example, an SLO could be "99.99% of requests must be served successfully within 500ms".
Monitor SLIs: SLIs are the metrics that are used to measure the performance of your system. These metrics should be relevant to your SLOs and should give you a good idea of how well your system is meeting its objectives. Examples of SLIs include latency, error rate, and throughput.
Establish SLI thresholds: Once you have defined your SLIs, you need to establish thresholds for each one. These thresholds represent the minimum level of performance that your system must achieve to meet your SLOs. For example, if your SLO is to serve 99.99% of requests successfully within 500ms, you might set a threshold of 99.9% for latency and 0.1% for error rate.
Continuously monitor SLOs: You should continuously monitor your SLIs and compare them against your established thresholds. This will allow you to quickly identify any issues and take corrective action before they impact your customers.
Use automation to manage SLOs: Automation can help you manage your SLOs by providing real-time monitoring, alerting, and automated responses to issues. For example, if an SLI falls below its threshold, you can use automation to automatically scale up your infrastructure or roll back a deployment.
Use dashboards and reporting to track progress: Dashboards and reporting can help you track your progress towards meeting your SLOs over time. This can be used to identify trends, spot areas for improvement, and demonstrate the effectiveness of your SRE practices to stakeholders.
Real Life Scenario
Ok so enough of Gyan. Now let us look at an example using a combination of tools such as Prometheus and Grafanna on how to set SLI thresholds and how to define error rate
Prometheus is a popular open-source monitoring solution that is widely used for monitoring and alerting in SRE practices.
Grafana is a visualization tool that can be used with Prometheus to create dashboards and visualizations. You can create a Grafana dashboard that displays your latency SLI and error rate SLI, along with their respective thresholds. This dashboard could also display other metrics such as CPU usage, memory usage, and network throughput.
Let us understand this concept with the help of a scenario.
Scenario: Assume you work for a company that has a virtual machine running on a cloud provider. You want to monitor the CPU usage of this VM and set an SLO that requires the CPU usage to remain below a certain threshold.
To do this, we need to set up the environment.
Set Up the Monitored VM
The first step is to set up the VM that you want to monitor. Here are the steps you can follow:
Choose a cloud provider to host your VM.
Create a new VM instance on your chosen cloud provider. In this example we are using an Ubuntu OS however you can choose an OS of your choice.
Install the necessary dependencies on the VM. In this example, we'll monitor the CPU usage of the VM, so you'll need to install a utility that can report CPU usage metrics. On Linux-based systems, you can use the
mpstatcommand to report CPU usage.For example, on a Ubuntu-based system, you can install
mpstatusing the following command:
Test that the CPU usage utility is working correctly by running the
mpstatcommand and verifying that it reports CPU usage metrics.
Install and Configure Prometheus on the Monitoring Server
The next step is to install and configure Prometheus on a separate monitoring server. Here are the steps you can follow:
Install Docker on your monitoring server.
Pull the latest Prometheus Docker image from Docker Hub using the following command:

Create a directory on your monitoring server where you will store your Prometheus configuration files. In this example, we'll create a directory called
prometheus:
Create a configuration file for Prometheus called
prometheus.ymlin theprometheusdirectory. This file defines the targets that Prometheus will scrape for metrics. Here's an example configuration that targets the VM we set up in Step 1: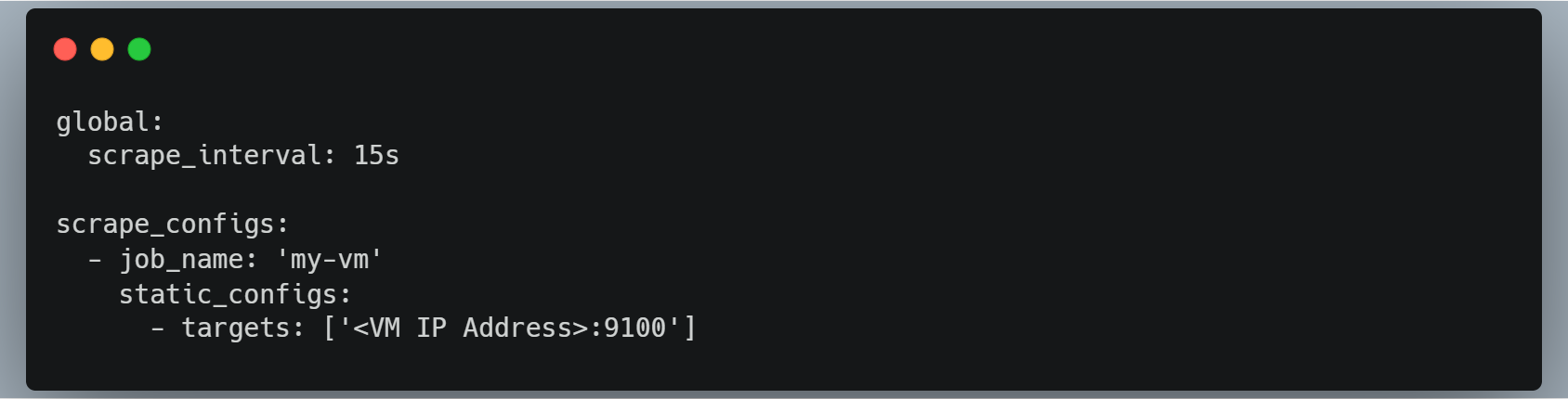
This configuration tells Prometheus to scrape metrics from the
node_exporterutility running on the VM.Start the Prometheus Docker container using the following command:

This command starts the Prometheus container, maps port 9090 to the host machine, and mounts the
prometheusdirectory as a volume in the container.
Define SLIs and SLOs
The next step is to define your SLIs and SLOs. In our example, we'll define an SLI for CPU usage as the percentage of CPU usage on the VM. We'll set an SLO that requires the CPU usage to remain below a certain threshold.
Monitor SLIs and SLOs
Once you have defined your SLIs and SLOs, you need to monitor them using Prometheus. This can be done by adding metrics to your code and instrumenting your system to expose these metrics. Prometheus can then scrape these metrics and store them in a time-series database.
In this example, we'll use the node_exporter utility running on the VM to report CPU usage metrics to Prometheus. To do this, you'll need to install the node_exporter utility on the VM. Here's how you can do this:
Download the latest
node_exporterrelease from the official GitHub page:
Extract the
node_exporterbinary from the tarball:
Move the
node_exporterbinary to the/usr/local/bindirectory:
Create a system service for
node_exporterby creating a new file in the/etc/systemd/system/directory callednode_exporter.servicewith the following contents: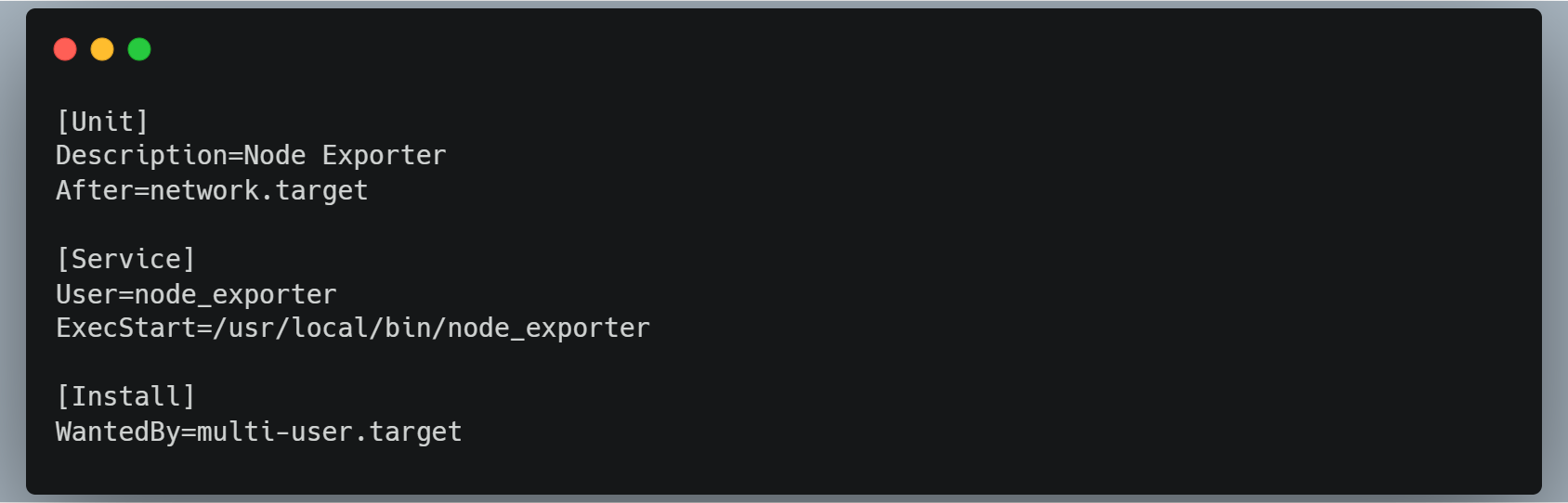
Reload the system service configuration by running the following command:

Start the
node_exporterservice by running the following command:
You can verify that
node_exporteris running correctly by visitinghttp://<VM IP Address>:9100/metricsin your web browser. This should display a list of metrics thatnode_exporteris reporting.
Set SLI and SLO thresholds
After monitoring your SLIs and SLOs, you need to set thresholds for each one. For example, you might set a CPU usage threshold of 70% for your SLO.
To set these thresholds in Prometheus, you can use the prometheus.yml configuration file that we created in Step 2. Here's an updated configuration that sets a threshold for the node_cpu_seconds_total metric:
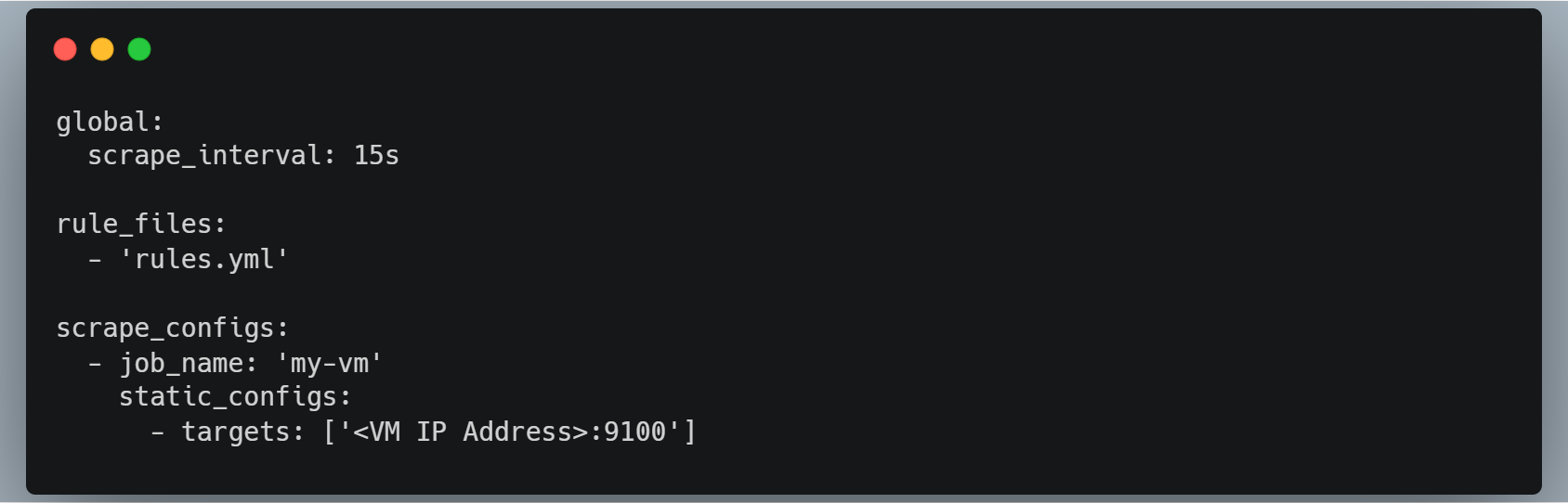
Note that we've added a rule_files section to this configuration file. This section specifies a file called rules.yml that contains rules for Prometheus to evaluate. Here's an example rules.yml file that sets a threshold for the node_cpu_seconds_total metric:
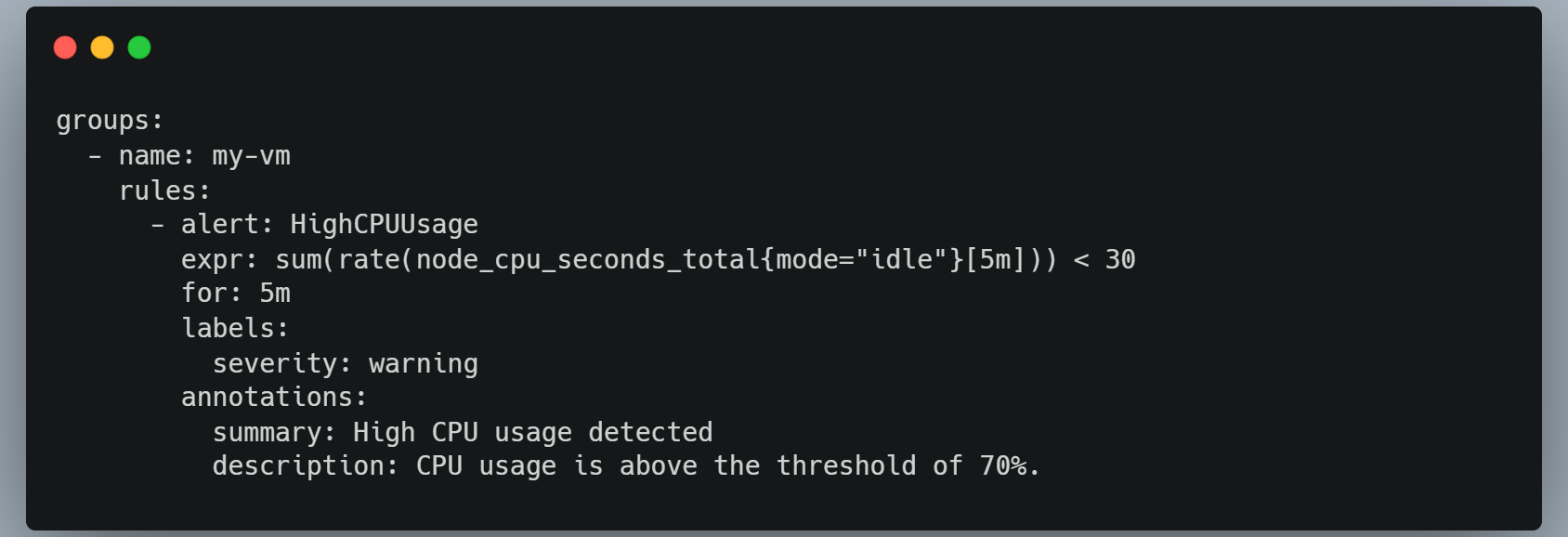
This rule sets an alert named HighCPUUsage if the CPU usage on the VM is below 30% over the last 5 minutes.
Visualize SLIs and SLOs with Grafana
Finally, you can use Grafana to create custom dashboards and visualizations that display your SLIs and SLOs in real-time. Here's how you can set up Grafana with Docker:
Pull the latest Grafana Docker image from Docker Hub using the following command:

Start the Grafana Docker container using the following command:

This command starts the Grafana container and maps port 3000 to the host machine.
Access the Grafana web interface by navigating to
http://localhost:3000in your web browser.Log in to Grafana using the default username and password of
admin.Add Prometheus as a data source by clicking on the
Configurationicon in the left sidebar, then selectingData Sources, and clicking on theAdd data sourcebutton. SelectPrometheusas the data source type and enter the URL for your Prometheus instance (http://<Monitoring Server IP Address>:9090in our example).Create a new dashboard by clicking on the
+icon in the left sidebar, then selectingDashboard, and clicking on theAdd new panelbutton. You can add visualizations such as line charts, bar charts, and heatmaps that show your SLIs over time.
For example, you might create a line chart that displays the CPU usage of your VM over time. You can set the Y-axis to show the CPU usage as a percentage and the X-axis to show the time range. You can also add a threshold line at 70% to show the SLO threshold.
Conclusion
In summary, to monitor and measure the performance of a VM using Prometheus and Grafana, you need to set up the VM and its dependencies, install and configure Prometheus on a separate monitoring server, define SLIs and SLOs, monitor SLIs and SLOs using Prometheus and instrument your system, set thresholds using Prometheus rules, and visualize SLIs and SLOs with Grafana.
Can we emulate a CPU spike on the VM so that we can simulate the same in the dashboard?
Yes, in orderto emulate a CPU spike on the VM, you can use a tool like stress which is a workload generator tool that can generate CPU, memory, I/O, and disk stress on a system. Here's how you can use stress to generate a CPU spike on your VM:
Install
stresson your VM using the package manager for your operating system. For example, on Ubuntu-based systems, you can installstressusing the following command:
Run the
stresscommand with the-coption to generate CPU stress. For example, to generate 4 threads of CPU stress, you can run the following command:
You can run this command in a separate terminal window while monitoring the CPU usage of the VM using Prometheus and Grafana. You should see a spike in CPU usage in the Grafana dashboard as
stressgenerates CPU stress.
Note that you should be careful when generating CPU stress on your system, as this can cause your system to become unresponsive if the stress is too high. It's important to ensure that your system has enough resources to handle the stress and that you have a way to stop the stress if it becomes too much to handle.
Subscribe to my newsletter
Read articles from Piyush T Shah directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by