Implementing Bloom Filters in Python and Understanding its error probability: A Step-by-Step Guide
 satish Mishra
satish Mishra
Before diving into the implementation of the bloom filters data structure, I highly recommend reading my article on the "What, Why, and How" of bloom filters. You can find the link to the article here.
Main components required for Bloom filters implementation :
Capacity (i): The maximum number of elements that can be stored in the Bloom filter.
Number of Hash Functions (k): The number of hash functions needed to hash the elements.
Number of Bits (m): The number of bits in the array needed to represent the Bloom filter.
Error Rate: Since Bloom filters are probabilistic data structures, we need to define the desired maximum false positive rate.
Probability of False Positive and Relation among i, m, k
Assumes a function that selects each array position with equal probability. Considering m is a number of bits in the array the probability of selecting a bit is 1/m. and the probability of not setting a bit is
p = 1 - 1/m
and there are k hash function so the probability now for not setting a bit by k hash function is
p = (1 - 1/m)**k
and if there are i strings it becomes
p = (1 - 1/m)**(k*i) # ** is power sign
Now our interest lies in setting a bit by mistake for a string which will result in a False positive and thus error rate. The probability of this becomes
p = 1 - (1 - 1/m)**(k*i)
Now we would need to do it for k times
Finally, the error rate for a string comes to:
p = [1 - (1 - 1/m)**(k*i)]**(k)
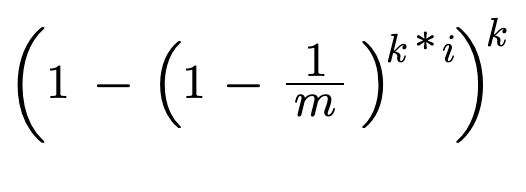
if m is infinite error rate becomes 0
if m is 1 error rate becomes 1 which is 100 percentage
Since:
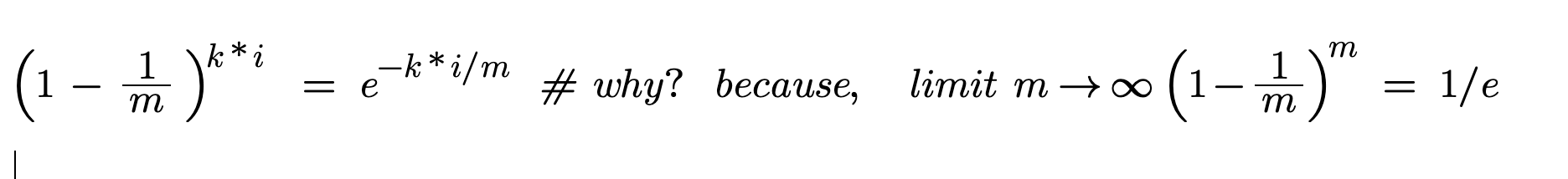
By replacing the above our final Error Probability comes to.
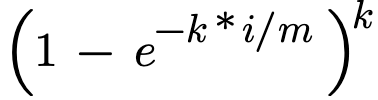
in the above equation our P is minimum when k = log(2)(m/i)
Similarly, we can deduce the optimal value of m (number bits) needed for desired error rate as -(i *log(p))/(log(2)**2) where p is the probability or error rate, i is the number of string
Implementation
import math
import mmh3
class BloomFilter:
'''
Python implementation of Bloom filters
'''
def __init__(self, capacity, error_rate):
'''
Initializes a Bloom filter with a given capacity and error rate
'''
self.capacity = capacity # maximum number of elements that can be stored
self.error_rate = error_rate # desired maximum false positive rate
self.num_bits = self.get_num_bits(capacity, error_rate) # number of bits needed
self.num_hashes = self.get_num_hashes(self.num_bits, capacity) # number of hash functions needed
self.bit_array = [0] * self.num_bits # bit array to store the elements
def add(self, element):
for i in range(self.num_hashes):
# generates a hash value for the element and sets the corresponding bit to 1
hash_val = mmh3.hash(element, i) % self.num_bits
self.bit_array[hash_val] = 1
def __contains__(self, element):
for i in range(self.num_hashes):
# generates a hash value for the element and checks if the corresponding bit is 1
hash_val = mmh3.hash(element, i) % self.num_bits
if self.bit_array[hash_val] == 0:
# if any of the bits is 0, the element is definitely not present
return False
# if all the bits are 1, the element may or may not be present
return True
def get_num_bits(self, capacity, error_rate):
'''
Calculates the number of bits needed for a given capacity and error rate
'''
num_bits = - (capacity * math.log(error_rate)) / (math.log(2) ** 2)
return int(num_bits)
def get_num_hashes(self, num_bits, capacity):
'''
Calculates the number of hash functions needed for a given number of bits and capacity
'''
num_hashes = (num_bits / capacity) * math.log(2)
return int(num_hashes)
# create a new bloom filter with a capacity of 1000 items and a false positive rate of 0.1
bloom_filter = BloomFilter(1000, 0.1)
# add some items to the bloom filter
bloom_filter.add("apple")
bloom_filter.add("banana")
bloom_filter.add("orange")
# check if an item is in the bloom filter
print("apple" in bloom_filter) # True
print("pear" in bloom_filter) # False
This implementation uses the MurmurHash3 algorithm (from the mmh3 library) to generate hash values for elements. It also includes methods to calculate the optimal number of bits and hash functions based on the desired capacity and error rate by following the mathematical equations explained above
We have overridden the __contains__ method of Python class to support lookup using in operator
Note that this implementation may not be the most optimal for very large datasets, as it uses a simple list to store the bits. In practice, more efficient data structures such as bit arrays can be used.
To summarise Bloom filters are a probabilistic data structure that allows for efficient membership testing. They are useful in applications where space is limited and false positives are acceptable.
Reference(s):
https://en.wikipedia.org/wiki/Bloom_filter
Thank you for reading this article. I hope you found it informative and engaging
Subscribe to my newsletter
Read articles from satish Mishra directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
satish Mishra
satish Mishra
software engineer with over 10 years of experience designing, developing, and leading enterprise and cloud-native applications. With a specialization in cybersecurity and infosec domains, I have SOAR, IPaaS, and business workflow automation expertise.