Invoice Processing with Azure OCR and GPT-4: An In Depth Step-by-Step Guide
 Rupesh Gelal
Rupesh Gelal
This blog will guide you through the process of using Azure OCR to extract text from invoice images and PDFs. You will also learn to utilize GPT-4 to extract entities from the invoices. By the end of this guide, you'll have a thorough understanding of Azure OCR service and GPT-4 for invoice entity classification.
Introduction:
Azure OCR(optical character recognition) is a cloud-based service provided by Microsoft Azure that uses machine learning techniques to extract text from images, PDFs and other text-based documents. OCR is a technology that allows computers to recognize and extract text from images, making it possible to search, edit, and analyze text in documents that were previously only available as images. Azure OCR can also recognize and extract text from documents written in various languages, including but not limited to Spanish, Hindi, Portuguese, Korean, and English. This is helpful for freelancers and businesses that operate globally.
GPT-4 is the newest and most advanced language model in the GPT family. Compared to GPT-3.5 or ChatGPT, it's estimated to be ten times more powerful and has performed impressively in various tests and tasks, such as bar exams and standardized tests like SATs and AP exams. Its ability to generate accurate and concise answers that are nearly indistinguishable from human-written responses is remarkable. Moreover, GPT-4 is unique in its capability to process both text and image inputs, making it a highly versatile tool with a wide range of applications.
Getting Started with Azure OCR:
To use Azure OCR service, you need a valid Azure subscription, which you can obtain by creating an account on the Azure portal. In addition to that, you'll need an Azure cognitive service key and an endpoint to connect to the OCR service from your app.
To get the subscription key and endpoint:
Go to the Azure portal (portal.azure.com) and log in to your account.
Navigate to the Cognitive Services dashboard by selecting "Cognitive Services" from the left-hand menu.
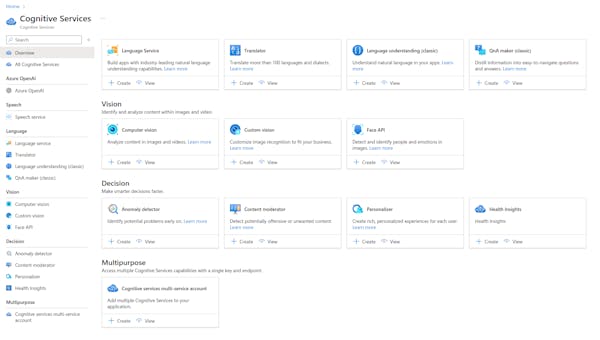
Click the "+ Add" button to create a new Cognitive Services resource. Under "Create a Cognitive Services resource," select "Computer Vision" from the "Vision" section.
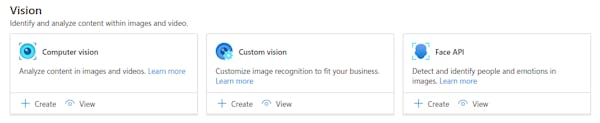
Choose your subscription, resource group, and region, then give the resource a name and click "Review + create."
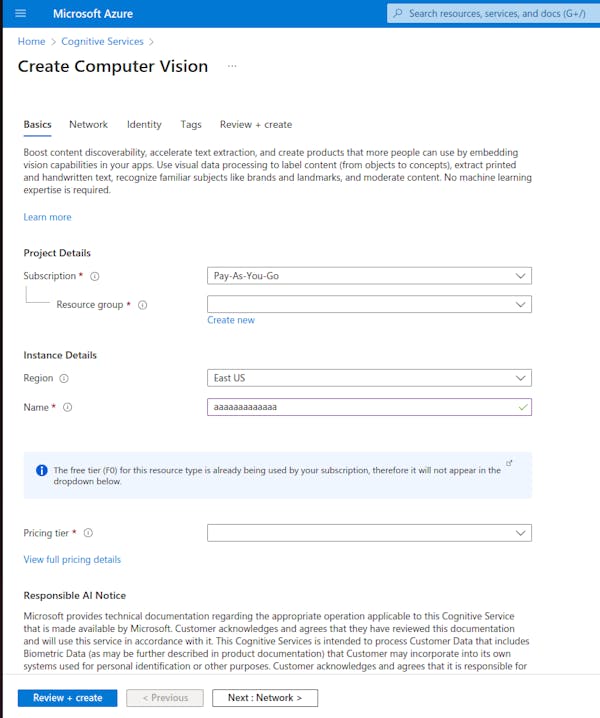
Review the settings and click "Create" to create the new resource.
Once the resource has been created, go to the resource dashboard and navigate to the "Keys and Endpoint" tab.
Under "Keys," you will see two keys that you can use to authenticate requests to the OCR service. Copy one of the keys and save it somewhere secure, as you will need it to access the OCR service.
Under "Endpoint," you will see the endpoint URL for the OCR service. Copy this URL as well, as you will need it to connect to the OCR service via the API.
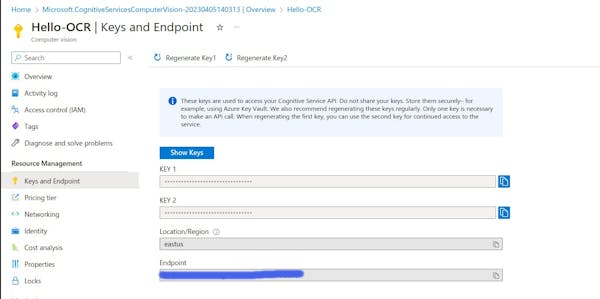
That's it! You now have the key and endpoint you need to use the Azure OCR service.
Extracting text using Azure OCR:
First, we need to install the necessary packages.
azure-cognitiveservices-vision-computervision==0.9.0
pdf2image==1.16.2
poppler-utils==0.1.0
After that, we need to import the necessary packages from the Azure Cognitive Services SDK for Python and initialize a ComputerVisionClient object using the endpoint and subscription_key obtained from the Azure portal. This client object will be used to make requests to the OCR API.
from azure.cognitiveservices.vision.computervision import ComputerVisionClient
from msrest.authentication import CognitiveServicesCredentials
subscription_key = ''
endpoint = ''
computervision_client = ComputerVisionClient(endpoint, CognitiveServicesCredentials(subscription_key))
Next, we will create azure_ocr function that takes an image file as content and returns recognized text from images or pdfs.
from azure_credentials import *
from azure.cognitiveservices.vision.computervision.models import OperationStatusCodes
from io import BytesIO
def azure_ocr(content):
image_data = BytesIO(content)
headers = {'Content-Type': 'application/octet-stream'}
result = computervision_client.recognize_printed_text_in_stream(image_data, headers=headers)
text = ''
for region in result.regions:
for line in region.lines:
for word in line.words:
text += word.text + ' '
text += '\n'
return text
The azure_ocr function creates an image_data object from the bytes of content and sets the Content-Type header to application/octet-stream, and uses the recognize_printed_text_in_stream method of computervision_client to recognize printed text in the image data.
After that, it loops through the resulting regions, lines, and words to extract the recognized text and returns the text as a string.
Now, let's write a code that allows users to upload images or PDF files and extract text from an uploaded file.
from google.colab import files
from PIL import Image
import io
uploaded_files = files.upload()
for file_name, file_content in uploaded_files.items():
if file_name.endswith(".pdf"):
images = convert_from_bytes(file_content)
for i, image in enumerate(images):
img_byte_arr = io.BytesIO()
image.save(img_byte_arr, format='JPEG')
img_bytes = img_byte_arr.getvalue()
ocr_text = azure_ocr(img_bytes)
print(f"OCR text for page {i+1}:")
print(ocr_text)
display(Image.open(io.BytesIO(img_bytes)))
elif file_name.endswith((".png", ".jpg", ".jpeg")):
ocr_text = azure_ocr(file_content)
print(f"OCR text for {file_name}:")
print(ocr_text)
display(Image.open(io.BytesIO(file_content)))
else:
print(f"{file_name} is not a supported file format.")
Here, if statement checks if the file name ends with the ".pdf" file extension. If it does, it converts the PDF file into a series of images using the convert_from_bytes() function from the pdf2image library. The resulting images are then processed using Azure OCR to extract text.
The elif statement checks if the file name ends with either ".png", ".jpg", or ".jpeg" file extensions. If it does, the image file is processed using Azure OCR to extract text. The extracted text is printed to the console, and the image is displayed.
The else statement is executed when the uploaded file has a file extension that is not supported. It prints an error message to the console.
Testing Azure OCR:
Now that we have all things ready, let's check the accuracy of the Azure OCR service.
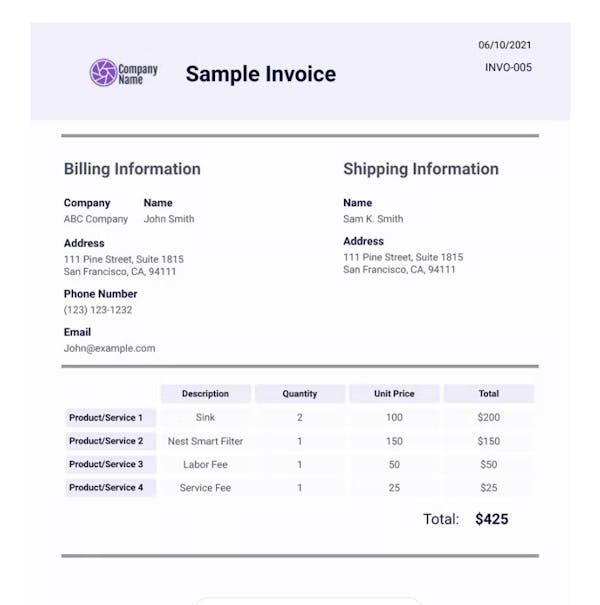
Raw ocr_text:
Company Name Sample Invoice Billing Information Company ABC Company John Smith Address 111 Pine street, Suite 1815 san Francisco, CA, 94111 Phone Number (123) 123-1232 Email John@example.com 06/10/2021 INVO-005 Shipping Information Name Sam K. Smith Address 111 Pine Street, suite 1815 Product/Service 1 Product/Service 2 Product/Service 3 Product/Service 4 Description Sink Nest Smart Filter Labor Fee Service Fee 2 san Francisco, CA, 94111 unit price 100 150 50 25 Total: Total $200 $150 $50 $25 $425
Extracting text using Form-Recognizer service:
In the previous section, we learned how to extract text from invoices in detail using Azure OCR. However, if you only want to extract key information without unnecessary hassle, you can use the Form Recognizer service of Azure. There are two options: using Form Recognizer with a custom model trained on our specific type of invoice or using the general Form Recognizer without training a custom model. Here, we'll use Form Recognizer without training the custom model.
To use Form Recognizer, you need to create a Form Recognizer resource in the same way as you created the Azure Computer Vision (OCR) service in the previous section, and then obtain the key and endpoint.
To get started, you first need to install the azure-ai-formrecognizer package using pip.
!pip install azure-ai-formrecognizer
Then import the necessary modules.
from azure.ai.formrecognizer import FormRecognizerClient
from azure.core.credentials import AzureKeyCredential
Actual code for recognizing form:
endpoint = ""
key = ""
form_recognizer_client = FormRecognizerClient(endpoint, AzureKeyCredential(key))
for file_name, file_content in uploaded_files.items():
if file_name.endswith((".png", ".jpg", ".jpeg", ".pdf")):
with open(file_name, "rb") as f:
if file_name.endswith((".jpg", ".jpeg", ".png")):
poller = form_recognizer_client.begin_recognize_receipts(
receipt=f
)
else:
poller = form_recognizer_client.begin_recognize_invoices(
invoice=f
)
result = poller.result()
text = ""
for recognized_form in result:
for name, field in recognized_form.fields.items():
text += f"{name}: {field.value}\n"
print(f"Extracted text from {file_name}:")
print(text)
Form-recognizer uses Recognizer API to extract information from receipts and invoices. It first sets up the client by providing the endpoint and access key, and then loops through each uploaded file to determine if it's a receipt or an invoice based on its file extension.
For receipts, it calls the begin_recognize_receipts method of the client, passing in the file content as the receipt parameter. For invoices, it calls the begin_recognize_invoices method instead.
Both methods return a Poller object, which is used to asynchronously get the result of the form recognition operation. The poller.result() method blocks until the operation is complete, and then returns a list of RecognizedForm objects.
The code then loops through each RecognizedForm object and extracts the values of its fields, which are stored in a dictionary. The extracted text is then printed to the console.
Let's check the result:
MerchantAddress: 111 Pine Street, Suite 1815 San Francisco, CA, 94111
MerchantPhoneNumber: None
ReceiptType: Itemized
Total: 425.0
TransactionDate: 2021-06-10
Extracting invoice entities using GPT-4:
Next, we will extract invoice entities from the text that was extracted by the Azure OCR service.
Let's import the necessary modules.
import openai
import os
Set the OpenAI API key to access the GPT-4 model.
os.environ['OPENAI_API_KEY'] = ''
Since GPT-4 is a chat-based model, we need to provide the system role for the chat, as well as an example text and example entities to give context for the model.
system_role="Extract entities and values as a key-value pair from the text provided"
example_text="Invoicing Street Address Template.com City , ST ZIP Code BILL TO Name Address City , State ZIP Country Phone Email pp1 pp2 Pp3 P.O. # # / Taxable NOTES : Your Company Name looooo0000 ロ Phone Number , Web Address , etc. Sales Rep . Name Ship Date Description test item 1 for online invoicing test item 2 for onvoice invoicing template This template connects to an online SQL Server SHIP TO Name Address City , State ZIP Country Contact Ship Via Quantity 1 2 3 PST GST INVOICE THANK YOU FOR YOUR BUSINESS ! DATE : INVOICE # : Client # Terms Unit Price 3.00 4.00 5.50 SUBTOTAL 8.000 % 6.000 % SHIPPING & HANDLING TOTAL PAID TOTAL DUE Due Date Line Total 3.00 8.00 16.50 27.50 27.50 27.50"
example_entities="""
Company Name: Your Company Name
Phone Number: looooo0000
Web Address: Template.com
Ship To Name:
Address:
City:
State:
Zip Code:
Country:
Contact:
Quantity: 1
Quantity: 2
Quantity: 3
Unit Price: 3.00
Unit Price: 4.00
Unit Price: 5.50
Subtotal: 8.00
Taxable:
Line Total: 3.00
Subtotal: 8.00
Shipping & Handling: 6.00
Total Paid: 27.50
Total Due: 27.50"""
Now, we can use the GPT-4 model to generate a response based on the provided input.
ocr_genrated_text = "Company Name Sample Invoice Billing Information Company ABC Company John Smith Address 111 Pine street, Suite 1815 san Francisco, CA, 94111 Phone Number (123) 123-1232 Email John@example.com 06/10/2021 INVO-005 Shipping Information Name Sam K. Smith Address 111 Pine Street, suite 1815 Product/Service 1 Product/Service 2 Product/Service 3 Product/Service 4 Description Sink Nest Smart Filter Labor Fee Service Fee 2 san Francisco, CA, 94111 unit price 100 150 50 25 Total: Total $200 $150 $50 $25 $425 "
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role":"system","content":system_role},
{"role":"user","content":example_text},
{"role":"assistant","content":example_entities},
{"role":"user","content":ocr_generated_text}
]
)
Check the response object to see the generated text.
text=response["choices"][0]["message"]["content"]
print(text)
The result:
Company Name: Company ABC
Billing Information:
Name: John Smith
Address: 111 Pine street, Suite 1815
City: San Francisco
State: CA
Zip Code: 94111
Phone Number: (123) 123-1232
Email: John@example.com
Invoice Date: 06/10/2021
Invoice Number: INVO-005
Shipping Information:
Name: Sam K. Smith
Address: 111 Pine Street, suite 1815
City: San Francisco
State: CA
Zip Code: 94111
Product/Service 1:
Description: Sink
Unit Price: 100
Total: $200
Product/Service 2:
Description: Nest Smart Filter
Unit Price: 150
Total: $150
Product/Service 3:
Description: Labor Fee
Unit Price: 50
Total: $50
Product/Service 4:
Description: Service Fee 2
Unit Price: 25
Total: $25
Total: $425
Hence, Optical character recognition (OCR) technology can be utilized for automated data extraction from invoices, while advanced language models like GPT-4 can be used for entity extraction. By adopting these technologies, businesses can save costs associated with manual data entry and improve their financial operations.
If you're interested in invoice processing, you might want to read our Invoice Processing with OCR using Google Vision API and Automated Invoice Processing with GPT-4 and Amazon Textract
For more information on how to use GPT-3 or GPT-4 for entity extraction from text, you can check this video.
Also, AIDemos.com is an incredible resource for anyone looking to explore the potential of AI.
Subscribe to my newsletter
Read articles from Rupesh Gelal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rupesh Gelal
Rupesh Gelal
I am passionate about new technologies and have a strong focus and experience in the areas of Machine Learning and Deep Learning, particularly in Natural Language Processing.