Summarize product reviews on Large Scale Data
 Aditya Adarsh
Aditya Adarsh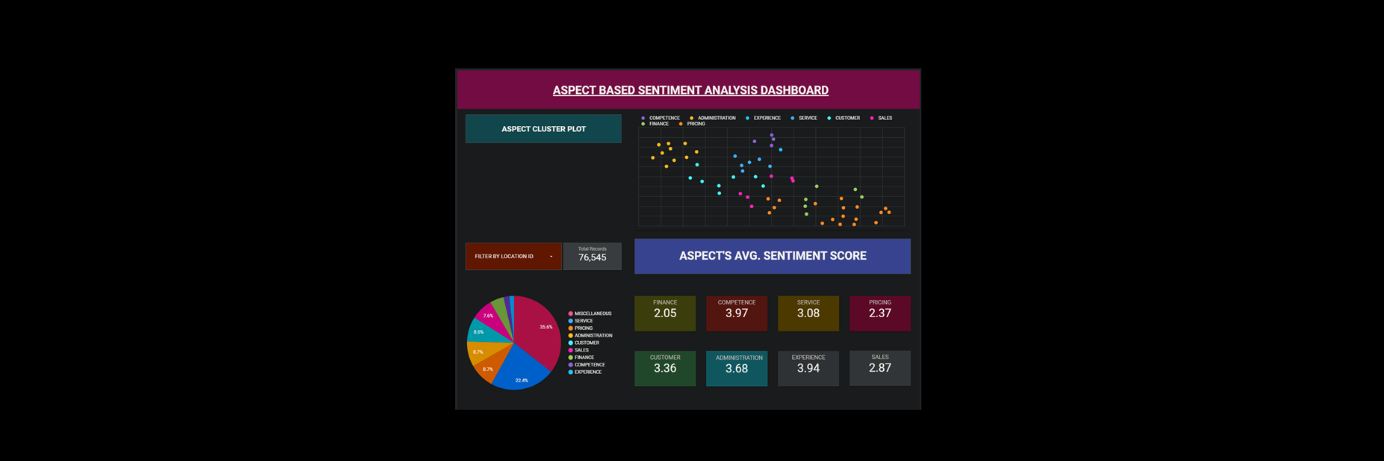
Summary
The project plan for conducting aspect-based sentiment analysis on customer reviews is a comprehensive plan that involves several steps.
Steps -
The first step is obtaining a dataset. In this project, the data is collected using the Google Place API and consists of 5 automotive service location review data. The dataset contains 109923 records and has no labeled output. The dataset is then cleaned by removing null and duplicate comments, expanding contractions, lowercasing the reviews, removing digits and words containing digits, removing punctuations, and changing emotions with words.
The second step is performing data cleaning and feature extraction. The primary feature in this project is the comment, and the analysis involves several techniques to decode the insights of text data. The techniques used for analyzing the comments include word count and character count, box plot of word length, stop word counts, word cloud, unigram analysis, bigram analysis, trigram analysis, and polarity analysis.
The third step is creating models for aspect extraction, inference, and sentiment detection. The aspect extraction model is a hybrid model that combines frequency-based and syntactic-relation-based approaches. It follows a three-step process that involves extracting aspect terms by extracting noun and noun-adjective pairs, extracting aspect terms using a similarity-based approach, and merging both dictionaries to consolidate a final aspect dictionary. The aspect inference model uses pre-trained embeddings to infer the most appropriate aspect for each sentence of the comments. The sentiment detection model uses pre-trained BERT models to find the sentiment of a sentence and its corresponding aspect.
The fourth step is evaluating the models using various metrics. The aspect extraction model is evaluated for its ability to extract all the semantically related aspects and eliminate all the irrelevant aspects. The aspect inference model is evaluated for its ability to assign the closest aspect to the sentence if the similarity score is greater than the threshold. The sentiment detection model is evaluated for its ability to calculate the sentiment of a sentence and its corresponding aspect accurately.
The fifth step is proposing future work, which involves labeling some data with domain experts and using supervised learning-based approaches. The supervised learning-based approach involves using span-level interactions for aspect sentiment triplet extraction.
Finally, a Data Studio dashboard is created to showcase the results of the analysis. The dashboard includes several interactive features that allow the user to select a location ID and calculate each aspect’s average sentiment score.
Overall, the project plan provides a comprehensive approach for conducting aspect-based sentiment analysis on customer reviews. It involves several techniques and models that are designed to extract the most relevant information from the data and provide accurate results.
Demo
Detailed Blog
Literature Survey and Data Sources
Abstract
Summarizing the product from the reviews has recently attracted a lot of attraction due to its extensive application. ECommerce companies like Amazon, and Flipkart contain massive amounts of review data. Consumers and sellers spend a large amount of time reading through long reviews to find out what is perceived as good and bad about a product. Customers and sellers need to understand what exactly the negative review was about. E.g.; If amazon delivered a product late by a week, the ‘service’ aspect is bad rather than the product.
The problem of summarization of reviews can be solved using Aspect Extraction of Opinion mining. Extracting/identifying the aspects of the product can help the business to attract more customers and improve the service. Therefore summarizing the product reviews into various aspects and understanding its sentiment can help the business and customers tremendously. Most of the existing aspect extraction task is done on the small-labeled dataset and applying these methods on large-scale datasets may produce irrelevant results and not be scalable. Also, labeling such large data is a huge challenge and not practical. To overcome this problem, an unsupervised learning approach is more suitable. Furthermore, Existing methods of aspect extraction based on unsupervised approaches use either a fixed number of aspects or only frequency-based approaches which may extract a huge number of the aspects but most of them might not be relevant to the domain and on the other hand, it might exclude infrequent relevant. This study aims to cover such limitations by exploring an efficient approach of combining a frequency-based approach (word level) and a syntactic-relation-based approach (sentence level) which is enhanced further with a semantic similarity-based approach to extract aspects that are relevant to the domain, even terms (related to the aspects) are not frequently mentioned in the reviews.
Business problem
Introduction
Summarizing product reviews can be used in various applications. Businesses/sellers can use this to understand what aspect of the product/service the customer talks about the most and what is sentiment associated with that aspect. Likewise, customers/users can go through an individual aspect of a product rather than reading through all the long reviews. The hospitality industry can use this to identify sentiment for each aspect category i.e., hotel staff, food variety, price, taste, location etc. Such type of aspect extraction is critical sometimes.
E.g.;
Take this review ‘Food was pretty average but ambiance and service were awesome’.
Here the user is appreciating the service and ambiance of the place.
Now take this review ‘Food was okay but the staff was very rude’.
Here even though the food is okay but service is horrible and this type of feedback is critical for the hospitality industry.
Challenges
The main challenge here is working with large-scale unlabeled data and extracting all the aspects without using any fixed aspect vocab. Furthermore, it should be able to extract all the aspects relevant to the product/domain and exclude irrelevant aspects.
Earlier methods
Most of the earlier approaches and research regarding motion magnification can
be categorized into the following two approaches.
Vocab-Based Approach:
In this approach, a predefined aspect vocab is used. Few researchers use only a fixed aspect list while others use a fixed list of aspects to find the relevant terms of that aspect. Further clustering is performed by finding the similarity between review sentences and aspect terms. While this approach is reasonably good for small-scale data It is observed that learned aspects tend to work better on large-scale data.
- Frequency-Based Approach:
This is the most used method by researchers to extract the aspects. Despite being very simple, it is quite effective. This method first high occurrence words and choose the noun and noun phrase as a candidate for aspect. If the frequency of the candidate aspects exceeds some threshold, it is considered an aspect. Once the aspect is extracted then the aspect's sentiment word is selected based on the nearest adjective and finally polarity value is assigned to that aspect. Although the frequency-based method is an efficient one, it has obvious limitations. One of the limitations is that the approach may select words that are not aspects (i.e., pick up many words that do not contain any subjectivity) because it relies only on word frequencies. Furthermore, aspects that are not frequently mentioned will not be detected using this method.
- Syntactic Relation-Based Approach:
The syntactic relation-based method also called the rule-based method aims to analyze the syntactic structure of the sentence and the relations among the words to identify the aspect’s sentiment words.
- Topic Modeling-Based Approach
Topic modeling-based approaches have gained popularity in recent years for aspect-based sentiment analysis. In this approach, the reviews are first clustered into different topics using techniques such as Latent Dirichlet Allocation (LDA) or Non-negative Matrix Factorization (NMF). Then, the sentiment of each aspect of each topic is calculated separately.
This approach allows for more granular analysis of the sentiment of each aspect, as well as the ability to identify the sentiment of each aspect about other aspects within the same topic. However, it requires labeled data for training the topic model, which can be a challenge in some cases.
Some recent studies have shown promising results with this approach. For example, one study used LDA to cluster reviews into different topics and then used a lexicon-based approach to extract the sentiment of each aspect of each topic. The results showed that this approach outperformed other state-of-the-art methods in terms of accuracy.
However, the topic modeling-based approach has some drawbacks. It requires a large amount of computational resources, and it can be difficult to interpret the results. Additionally, the accuracy of the approach is highly dependent on the quality of the labeled data used to train the topic model.
- Approach expected to be followed in this project:
We are going to take reference to the experiments given in this paper.
Our approach is the hybrid approach which combines a frequency-based approach (word level) and a syntactic-relation-based approach (sentence level) which is further enhanced using a semantic similarity-based approach. The core idea of this approach is to extract all the aspects related to the domain without using any fixed list of aspects and also extract that aspect that is not frequent. And produce sensible results on large-scale data.
This approach consists 3 tasks -
Aspect Extraction
Summarize reviews based on aspects.
Estimate aspect sentiment rating
Dataset
Challenges in obtaining a dataset
It is very difficult to obtain or scrape large-scale data under legal compliance. Apart from that, we need to have some labeled data to evaluate the performance of the model. The data set should also have a wide range of products/services as well as varying distribution of reviews for each product.
- Use API to Collect Data:
We can collect places API to collect listing/places review data but the only problem with this API is that it lets you collect only 5-star reviews data points and the quota is really small. There are other similar APIs available as well but it seems to be quite costly.
- Scrape the dataset:
This is one of the easiest ways to collect unlabeled data. It might require extensive preprocessing but it is a good approach for the experimentation purpose. There are various public scraper tools available out there with various limitations but it will get your work done with a bit of tweaking.
We are using one such scraper tool among many to scrape Amazon product reviews data. This API can scrape up to 500 products and 1000 reviews for each product.
- Publicly Available Dataset
Often large companies make their data public under legal compliance to help the innovators and contribute to the open source society. This ‘open data’ help both companies as well as academic researchers mutually. We have one such unlabeled data available from Amazon as well.
Amazon Customer Reviews Dataset
About the Data
The dataset contains the customer review text with accompanying metadata, consisting of two major components:
A collection of reviews written in the Amazon.com marketplace and associated metadata from 1995 until 2015. This is intended to facilitate study into the properties (and the evolution) of customer reviews potentially including how people evaluate and express their experiences concerning products at scale. (130M+ customer reviews)
A collection of reviews about products in multiple languages from different Amazon marketplaces, intended to facilitate analysis of customers’ perception of the same products and wider consumer preferences across languages and countries. (200K+ customer reviews in 5 countries)
Sources of dataset
For this project, we have used places API to get the domain-specific data and get a sense of the real world. We have collected 5 locations data which belongs to the automotive industry.
Loss functions and metrics
Though our primary goal is to extract aspects of unlabeled large-scale data. Due to the unavailability of labels on that data, we won’t be able to compute any performance metric but to evaluate the performance of the model we have collected some small-set labeled data.
F - Measure (F1 score): It is the combination of precision and recall of the model, and it also is defined as the harmonic mean of the model’s precision and recall.
We want our model to have high precision and the analogy behind it is that the model should be able to precisely predict the correct aspect category of the review sentence. It shouldn’t be categorizing the service aspect to the food aspect. At the same time, the model should be able to recall all the sentences related to that aspect. Therefore, F - Measure evaluation metric
Manual Inspection: As we are using large-scale unlabeled data so we cannot apply conventional evaluation metrics to our data due to the unavailability of labels. Therefore, human inspection is required to tune the model.
Real-world constraints and expectations
Latency requirements:
There is no need for real-time generation of aspects or summarizing the reviews at the moment. So we can create a data store to save the model’s output and create an IR system to retrieve the result to display on a dashboard.
Expectations:
The proposed model can extract all the relevant aspects and should be able to exclude irrelevant aspects.
It should be able to handle large-scale datasets with sensible results.
EDA and Feature Extraction
Data Description
The data for this experimentation is collected using google place API. It consists of 5 automotive service locations’ review data.
Total number of records in the dataset: 109923
Note: The dataset does not contain any labeled output.
The dataset contains the following columns:
location id- Indicates which location the record belongs to.comment titlecomment

Null count :
There is no comment title available for any of the comment
Half of the comment data is also missing
Distribution of records by location id :
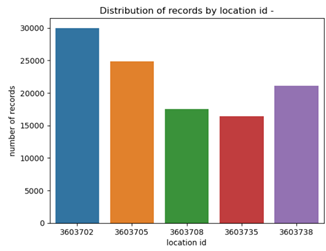
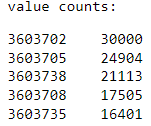
Number of records containing duplicate comments: 4519Number of records after removing null comments and duplicates: 50394
Distribution of records by location id (after removing null comments and duplicates) :
Basic Data Cleaning Steps:
Remove Null and Duplicate comments
Expand contractions
Lowercase the reviews
Remove digits and words containing digits
Remove punctuations
Change the emoticons with words
Univariate Feature Analysis:
As the comment is our primary feature in this project, we can perform all sorts of analyses which can decode the insights of text data. Below are a few examples -
Word count and character count
Box plot of word length
Stop word counts
World Cloud
Unigram Analysis
Bigram Analysis
Trigram Analysis
Polarity Analysis
Plot Analysis
- Word count
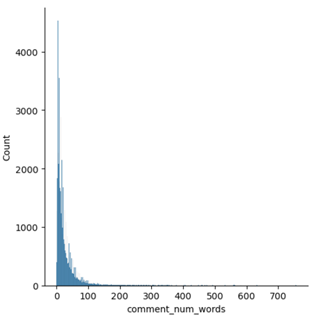
- We can observe that most of the comments have a word length of fewer than 150 words but there are a few comments which have very high word lengths. Those reviews may not be useful as they may contain only noise.
- Box plot of word length
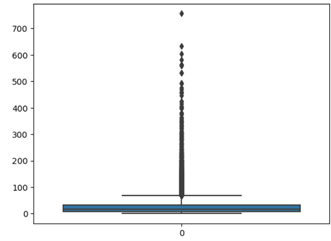
Box-plot of word length can help us to detect those records where comment length is abnormally high.
We can observe that 99 percent of the data having a word length of less than equal 152 words. So it is better to remove those comments from the dataset which is having skewed word counts as it won’t add much to the overall result.
- Stop word counts
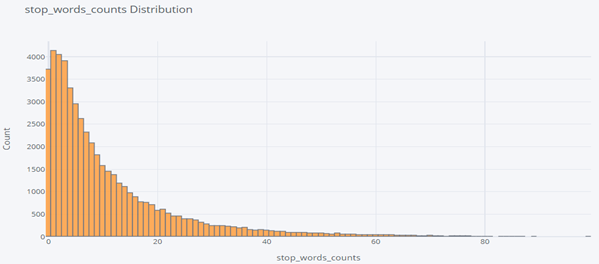
- Again, just like the word count distribution plot, the stop count distribution plot also follows the Pareto distribution.
- World Cloud

Word Cloud visually represents the frequency of different words present in a document.
It gives importance to the more frequent words which are bigger in size compared to other less frequent words.
It is important to remove all the stop words before visualizing the Word Cloud plot
Plot -
We can observe that words like Service, helpful, Call, and Vehicle are the most used words.
It is a bit difficult to get the top 100 frequent words along with their frequency just using this word cloud plot. There comes the need for unigram frequency analysis.
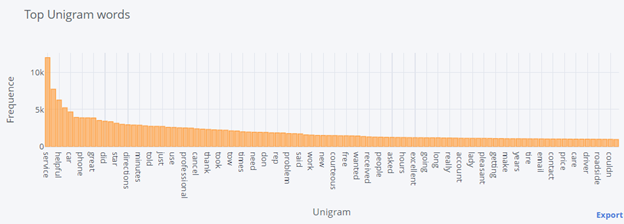
- Unigram Analysis
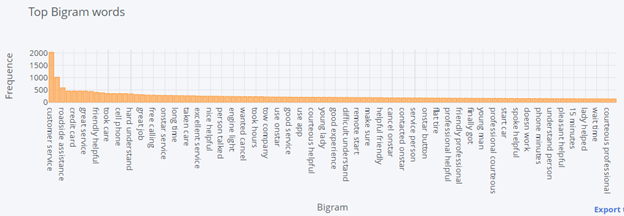
- Bigram Analysis
- Trigram Analysis
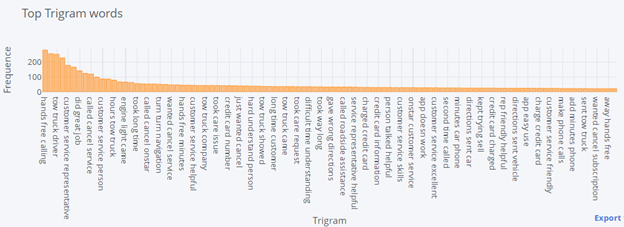
N-gram analysis is the frequency-based approach to understanding the most used words.
This type of analysis can help to get an idea of what sort of Aspects people are talking about.
We can infer from n-gram analysis that comments have mostly below topics
Customer service
Application (App)
Assistance and Speed
Service provider
Auto Parts (like flat tire, engine light)
Skills and competence
These insights can help us to choose appropriate aspect terms.
- Polarity Distribution Plot
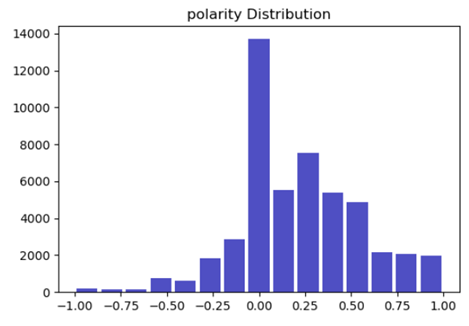
Help us to infer whether people are taking good or bad
We can observe that a lot of the comments have neutral sentiments.
We have more comments having positive sentiments.
Feature encoding
As our data consists of text data only, we can encode it using 2 approaches:
Frequency-Based (E.g. BOW)
It represents the word using its occurrence.
The dimension of the features could be very high because of the large vocab size and It usually creates sparsity.
It also doesn't capture the semantic essence of the word.
Semantic Relation Based (E.g. W2V and BERT)
- Word embeddings aim to map the semantic meaning of words into a geometric space. The geometric space formed by these vectors is called an embedding space
Our experiment approach is trying to find the aspects using both a frequency-based approach and a semantic relation-based approach. So we will incorporate both techniques one way or another.
For the frequency-based approach, we will count only the frequency of nouns and noun adjectives using syntactic grammar rules.
For the Semantic Relation-Based approach, we will use custom-trained w2v, pre-trained w2v and pertain Bert embeddings.
High-dimensional data visualization
Below are the following techniques that can be used for visualizing high-dimensional data.
PCA
tSNE
uMAP
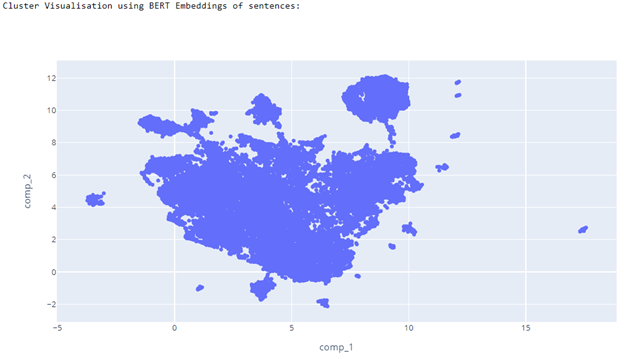
For this experiment, we are using the UMAP technique to visualize high-dimensional text data. uMAP is very similar to tSNE but works slightly faster than tSNE. The main advantage of tSNE types of technique over PCA is that it captures the distance of the neighborhood. That means if two words have the same meaning then It will try to preserve this information in the projection.
Plot -
Split the reviews into sentences
Get the embeddings using pre-trained Bert sentence encoder
Custer visualization using uMap
Modeling and Error Analysis
Our experiment consists of 3 tasks:
Aspect Extraction
Aspect Inference
Aspect's Sentiment detection
Each step involves a model and corresponding error. This report we will explore each step one by one and explain the experiment that we have conducted.
1. Aspect Extraction
For this step, we have taken the reference from this paper and written the algorithm from scratch.
Our approach is the hybrid approach which combines a frequency-based approach (word level) and a syntactic-relation-based approach (sentence level) which is further enhanced using a semantic similarity-based approach. The core idea of this approach is to extract all the aspects related to the domain without using any fixed list of aspects and also extract that aspect that is not frequent. And produce sensible results even on large-scale unlabeled data.
The core idea for Extracting Aspects -
Hybrid combination of both a frequency-based approach (word level) and syntactic-relation-based approach (sentence level) followed by a semantic similarity-based approach.
The model should be able to Eliminate all the irrelevant aspects and should able to extract all the semantically related aspects.
Understanding the approach in detail -
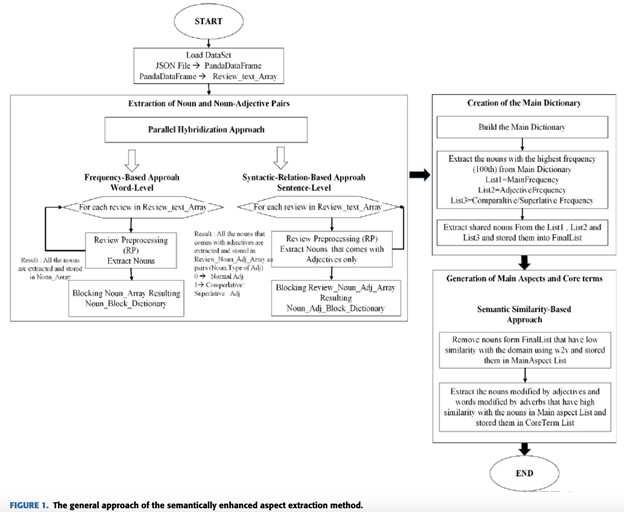
There are three main components of this step:
1.1. Extracting aspect terms by extracting noun and noun-adjective pairs
- Extract noun and noun-adjective pairs as those have the potential to be classified as aspects.
Two approaches are used:
Frequency-based approach (FBA)
Syntactic-relation-based approach (SRBA) - Uses Dependency parser
- Both of these approaches work in parallel, also called Parallel Hybridization Approach (PHA)
1.2. Extracting aspect terms using a similarity-based approach
- Using pre-trained embedding, get those words that are semantically similar to domain aspects.
1.3. Merging both the dictionary and consolidating a final aspect dictionary
Below is the flow chart of mentioned approach -
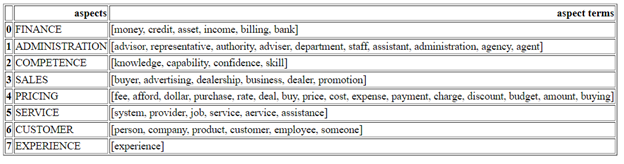
Below is the list of domain-relevant aspects -


Choosing only 8 aspects for the experiment. Below is the list -
FinanceAdministrationCompetenceSalesPricingServiceCustomerExperience
For the similarity-based approach, we have experimented with 3 models.
Pre-trained Word2Vec embedding trained on google news data
Custom-trained Word2Vec model on our dataset
Using pre-trained Bert embeddings
As we don’t have the labeled data for this experiment, we have to manually inspect the result by eyeballing it.
Findings -
Both pre-trained word2vec embeddings and custom-trained word2vec embeddings didn’t work well as per the experiment.
Whereas, Bert embedding gave the most appropriate result among all three.
Below is the final list of aspects and aspect 'terms extracted using mentioned approach and various experiments -
Aspect’s cluster visualization :
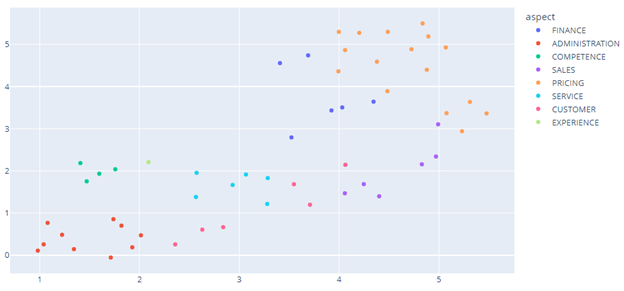
2. Aspect Inference
The objective is to infer the most appropriate aspect for each sentence of the comments.
To achieve this task, we have followed the below steps
Split the reviews into sentences using NLTK.
Encoded each sentence using pre-trained BERT.
Encoded each aspect term using the same pre-trained model.
Find the cosine similarity b/w sentence and aspect terms.
Assign the closest aspect to the sentence if the similarity score is greater than the threshold otherwise assigns it as a
miscellaneousaspect category.
Getting an appropriate threshold could be a bit tricky at first. But with some hit and trail and after eyeballing the result it could be done.
Sample Result:

Cluster Visualization of Aspects:
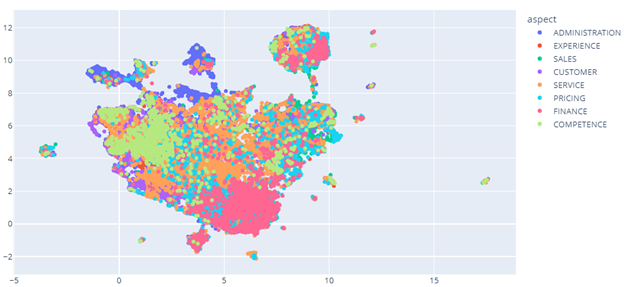
3. Aspect's Sentiment detection
Using a pre-trained Distil BERT model to find the sentiment of a sentence and its corresponding aspect
Ref: Hugging face sentiment pipeline
Sample output

Pros and cons of this model
Pros -
The model can capture semantically similar aspects, unlike other approaches like the frequency-based approach or syntactic relation-based approach only.
Works great when we don’t have unlabeled large-scale data because of blocking techniques used in the frequency-based approach (word level) and syntactic-relation-based approach (sentence level).
This model is very simple and intuitive and can be easily used for other domains/industries, given some domain aspects.
Cons -
As we are using an unsupervised learning approach to assign the aspect and calculate the sentiment of each sentence, the result is not very accurate.
Because of the lack of labeled data we cannot fine-tune the Bert embeddings further to get a better result.
Advanced Modeling and Feature Engineering
We have seen that an unsupervised-based approach is simple, intuitive and gives a pretty decent result. But the result can be significantly improved if we would have had labeled data.
That's why to improve the overall result we only experimented with the pre-trained embeddings. And finally finalized the embedding which gave the most appropriate result.
For Embedding, we have used all-MiniLM-L6-v2
For Sentiment calculation, we have used nlptown/bert-base-multilingual-uncased-sentiment
Project Deployment and Productionisation
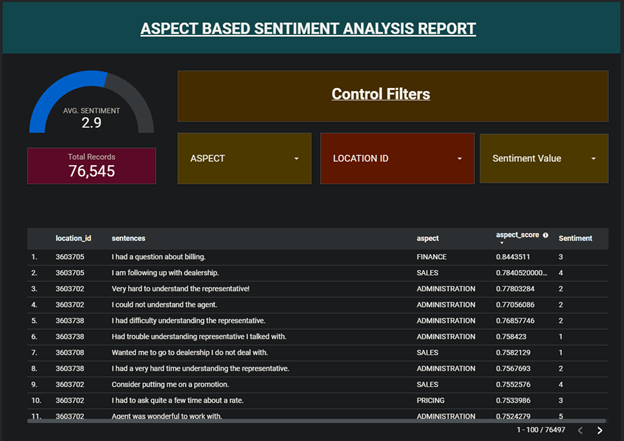
Our eye-catching experiment for this project is an interactive report. It automatically calculates each aspect’s average sentiment score by selecting a location id.
We have used Data Studio to create the report. Here is the link to the dashboard.
Snapshot 1
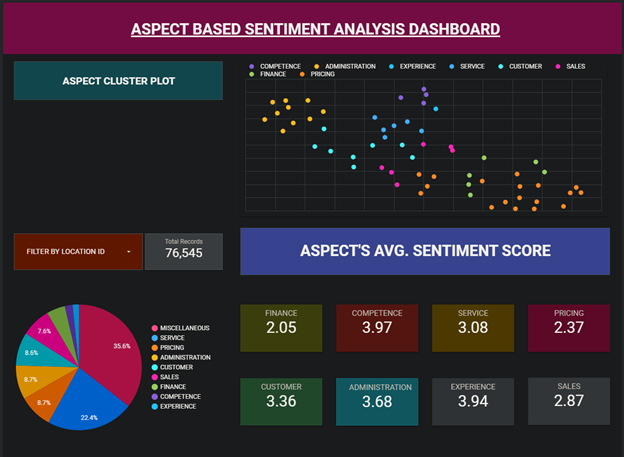
Snapshot 2
A further approach is to label some data with the help of domain experts and use a supervised learning-based approach.
One such approach is Span-Level Interactions for Aspect Sentiment Triplet Extraction.
References
[1812.03361v2] An Unsupervised Approach for Aspect Category Detection Using Soft Cosine Similarity Measure (arxiv.org)
Aspect Extraction in Customer Reviews Using Syntactic Pattern - ScienceDirect
Performing effective Aspect Based Sentiment Analysis | Board Infinity - YouTube
Sentiment Analysis is not enough!! | by Dhruv Gangwani | DataDrivenInvestor
Aspect-based Sentiment Analysis — Everything You Wanted to Know! | by Intellica.AI | Medium
Aspect Extraction and Opinion Analysis (achyutjoshi.github.io)
👉Git code repo
Subscribe to my newsletter
Read articles from Aditya Adarsh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aditya Adarsh
Aditya Adarsh
Data Scientist